


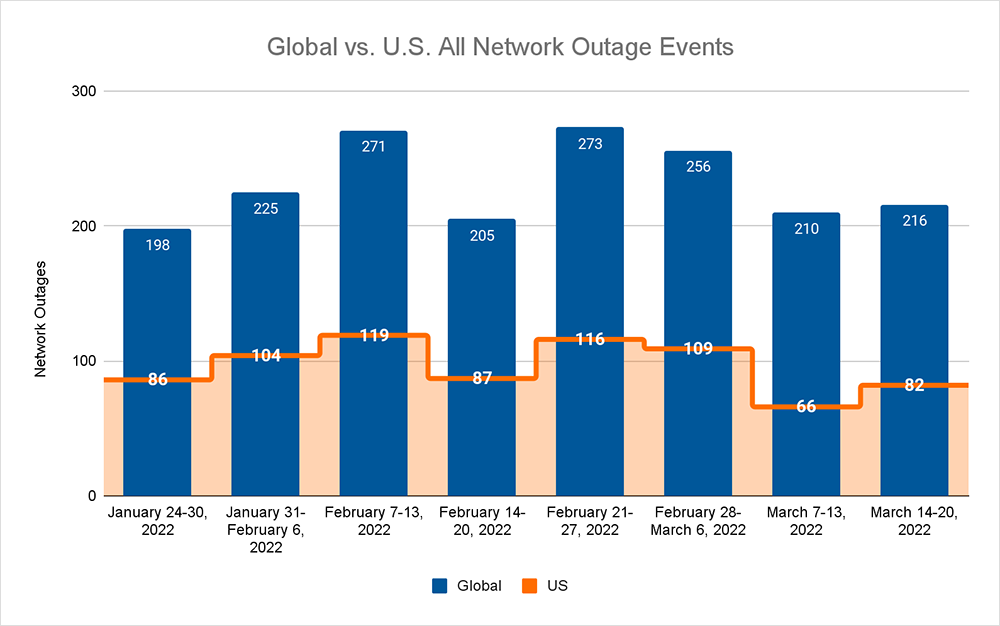
This week on the Internet, we saw a slight uptick in outage numbers compared to the previous week. There were a handful of brief application blips, but nothing of note in particular. Globally, after a two-week downward trend, we observed total outages increase from 210 to 216, a 3% increase compared to the previous week. This increase was reflected domestically, where outages numbers rose from 66 to 82, a 24% increase compared to the prior week. When we look at total global outages, the proportion of U.S. outages also increased 7% this week to 38%, vs. 31% the previous week. This increase means that the levels are trending toward the average percentages we saw across 2021.
This brings us to this week’s topic. We’re now well into the third month of 2022, and it’s already shaping up to be a different kind of year. What do I mean by that? Let me explain.
Typically in our outage statistics, we’re used to seeing a steady rise in the number of overall outages from January through March; and 2022 appears to be following a similar pattern, albeit with a lower number of outages overall. I say “appears to be” because there are a couple of deviations from the standard pattern.
First, January and February have been remarkably similar in terms of the outage numbers that we observed in each month. While it’s too early to make a definitive call on March, the month is trending fairly similarly to the first two months of this year.
And although I anticipate the typical “step pattern” of outages increasing month-over-month to continue in 2022, the size or cadence of the steps we’ve observed so far between January and March appear to be smaller than in previous years.
There’s also a noticeable step down in the absolute number of outages to date in 2022 when compared to prior corresponding periods. I should also note that this comparison does not include the anomalous impact of the start of mass work-from-home arrangements in March 2020. In looking at month-to-month outages, it’s clear the absolute numbers are down in 2022 and there is less variation from month to month.
And remember, this is occurring against the backdrop of growing amounts of Internet and cloud infrastructure being deployed worldwide.
The cloud infrastructure market alone brought in an extra $49 billion in the past year. Astronomical business growth is driving a huge increase in data center builds, cable lays and general infrastructure expansion. More infrastructure means more stuff we can instrument, and more moving parts means more potential points of failure or things that could go wrong. If past experience is any indicator, it would be entirely realistic to expect to see more failures occur more often.
Yet, they aren’t.
There’s a logical explanation for this, but also a potentially anomalous one, as well.
The logical explanation is that all the years of effort put into operational and infrastructure resilience is paying off. As engineers, we always design our own networks with resiliency in mind but had to rely, at some point, on other parties to carry our traffic. Resiliency between those different networks varied, and we were only ever as good as the party with the lowest resiliency or our ability to create workarounds.
Network conditions that might once have resulted in significant user-impacting incidents are mitigated well before anything particularly adverse is able to occur. Now, given the broad focus on site reliability engineering (SRE) and the addition of ‘Ops’ to just about every possible IT discipline (DevOps, SecOps, AIOps, etc.), it’s possible we’ve turned a corner on collective resiliency, such that when we (or our packets) do encounter degraded conditions, engineers are alerted. Workarounds can be quickly initiated, such that the user impact is low to negligible.
That doesn’t mean that significant outages will disappear completely. Of course, we’re witnesses to an increasing and diverse footprint when it comes to services and the associated service delivery chain, architected to provide services to a global user base. As we’ve previously discussed, a failure in a single part of that delivery chain environment can cause significant user-impacting issues. By having visibility across all the components you rely on, you can be better positioned to make changes to each one based on ambient conditions. You might change where your data is served from, how a container is accessed, or even the ISP or path to or from your equipment to avoid an outage or a catastrophic failure. The options available will depend a bit on your organization’s access to redundant capabilities, but this agility in network design is achievable.
The other explanation (for a start of the year with fairly stable outage numbers month-on-month and fewer outages overall than past years) is that 2022 is a bit of an anomaly because it started out more slowly than previous years. Whereas in past years, business activity really kicked off in earnest in February, it seemed that organizations have taken a bit longer this year to get into gear. Things are happening now—the sales kick-offs are done, the virtual events are back and there seems to be more activity generally. But this is effectively a month to six weeks later than other years.
It is possible that this is playing out in outage numbers: a muted start to the year by business has flow-on impacts. And, as the move to a more hybrid and distributed workforce expands around the globe, we might continue to see an adjustment in terms of the “typical” outage numbers, when compared to similar periods in previous years, essentially marking a shift away from what we’d determine to be traditional patterns. Time will tell.








