


This week on the Internet, we chart the rise of the application outage and analyze two examples: 1Password’s one-off synchronization incident, and a recurring string of degradations and dropouts at Dropbox that, as it turns out, were the result of a long-running resiliency and disaster readiness program. Before we expand on those application outages, let’s look at network outage numbers for the past week. Following the reversal of the three-week upward trend that we observed last week, this week again saw a rise in outages. Total global outages rose from 219 to 285, a 30% increase compared to the previous week. This was reflected domestically, where observed outages rose from 81 to 107, a 32% increase compared to the week prior. In total, U.S. outages accounted for 38% of all global outages last week, which is a slightly higher proportion compared to the previous week, when it was 37%.

Over the course of 2022, ThousandEyes has tracked a steady increase in the number of application outages; that is, tests that encounter degradation or error codes that point to an issue that resides within the application itself, instead of to an external issue caused by third-party connectivity or cloud hosting.
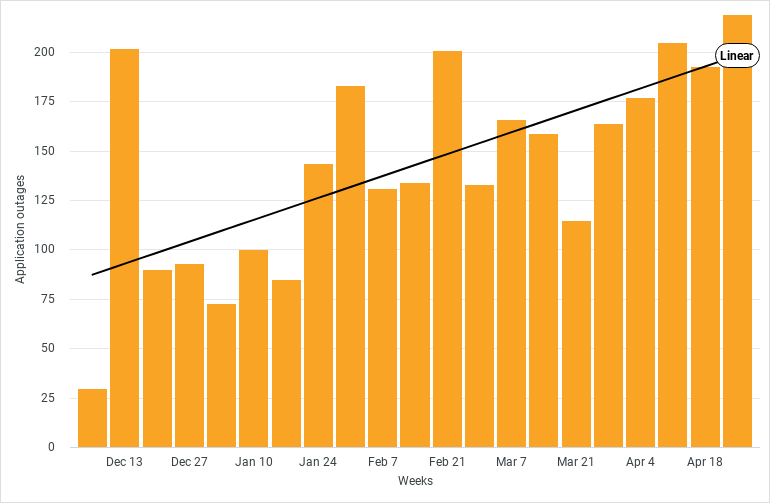
We saw two examples of application outages this week that are worth digging into further.
First, 1Password encountered database synchronization issues in the U.S. that reportedly “affected new user signups and syncing new data across devices.”
The incident started out as “multiple reports of failed connections and issues with login to 1password.com” before being recognized as a data synchronization issue. A disconnect formed between the database and the end user; the front end of 1Password was reachable, but when users tried to transact on it, such as to save a new password, it failed to establish a connection into the back-end database. This could be seen as an “unavailable service” within ThousandEyes’ tests.

1Password indicated in a media report that the root cause was a “planned database upgrade” that did not go as planned. It’s a textbook example of the types of application outages we’ve increasingly seen this year, where the fault lies within the application architecture itself, and does not correspond to any external issues, such as network outages elsewhere on the Internet.
An even more interesting example of this is a string of incidents affecting Dropbox over the past two-plus years that were officially explained by the vendor’s technology team in an expansive blog post.
To briefly summarize, Dropbox underwent a multi-year effort to improve its disaster readiness and to reduce the amount of time it would need to recover from a catastrophic event impacting one of its regions. In particular, the company wanted to show it could maintain availability even if its San Jose data center became unavailable, such as due to an earthquake.
The write-up on this effort is meticulous and includes some learnings for application and operations teams alike.
Applications, as we’ve previously established, often rely on a complex ecosystem of plugins and dependencies, each of which have their own interdependencies on other services to operate and function. It only takes one of these elements in the end-to-end application delivery chain to break to affect everything upstream and downstream of it.
Dropbox’s engineers appear to have encountered unexpected dependencies when they tested the impact of disconnecting one of their data centers entirely. The chosen test facility contained S3 proxies that a neighboring Dropbox data center relied on, which degraded the availability of Dropbox services. According to the blog, “What this test found was that, because we don’t yet treat facilities as independent points of failure—but plan to in the future—many cross-facility dependencies still exist.”
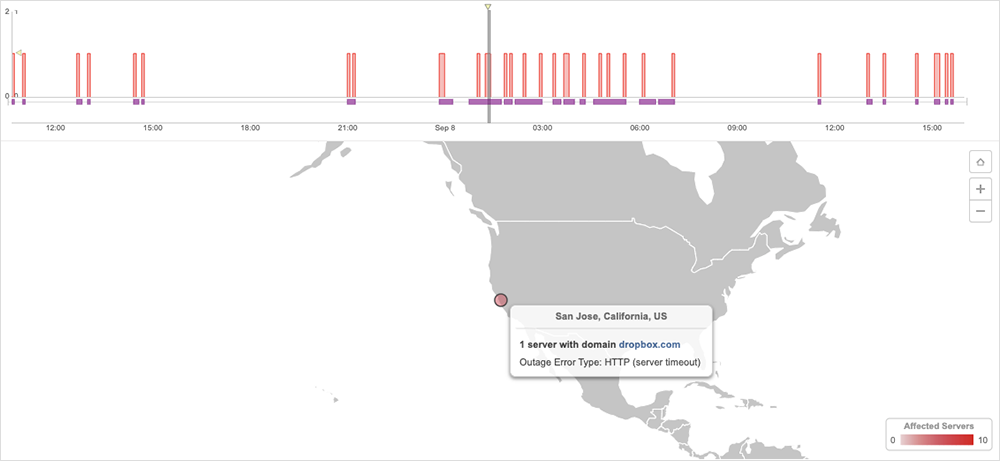
As they note, “the whole purpose of disaster recovery tests are the lessons.” In this instance, the test usefully highlighted “unknown unknowns” in their application architecture. And while Dropbox’s front-end offers a streamlined file storage experience, there are a host of services and systems behind the scenes for file access rules, locks, edit restrictions, file access authentication and authorization systems.
What’s most essential, however, is to understand how users are impacted by all of these dependencies when they connect to services: how their queries are structured, and the workflow of all the different elements needed to complete a transaction.
Dropbox ultimately had to go back and look at how their application was structured and where key elements were served, and then factor that into the way they designed their disaster recovery and failover processes. The write-up shows their multi-year resiliency efforts ultimately paid off, and they were able to blackhole the San Jose data center successfully for 30 minutes, without impacting availability. The fact that they did so speaks to the lengths that application owners will go to today to differentiate on performance. There are important lessons here for a lot of teams and organizations.
On a final note, regular readers will have noted our analysis last week on the downward trend in Internet outages in the first part of the year. For April alone, we measured a 24% decline. Again, watch this space for a more detailed and expansive look at the numbers.









