


A “Nothing happened here” plaque perplexed a student and archivist on a Northwestern campus in 1990, a duplicate plaque had a cameo on How I Met Your Mother, and for $25, anyone these days can orchestrate the same historical mischief with an “On this site in 1897 nothing happened” novelty plaque.
If it were to exist in a digitized version, we could have used it this week because it was—on the surface—an unremarkable week for Internet outage watchers. A week where “nothing happened.”
Except that, just like the 1897 plaque, that isn’t completely the case. After all, if you were to buy a plaque and randomly affix it somewhere, it’s likely that *something* happened in that spot in 1897, even if no one was around to record it. And similarly, on the Internet, even when it looks like nothing is happening, there’s always something going on behind the scenes.
Case in point: If we were looking at numbers only, there were more outages on a global basis this week than last week.
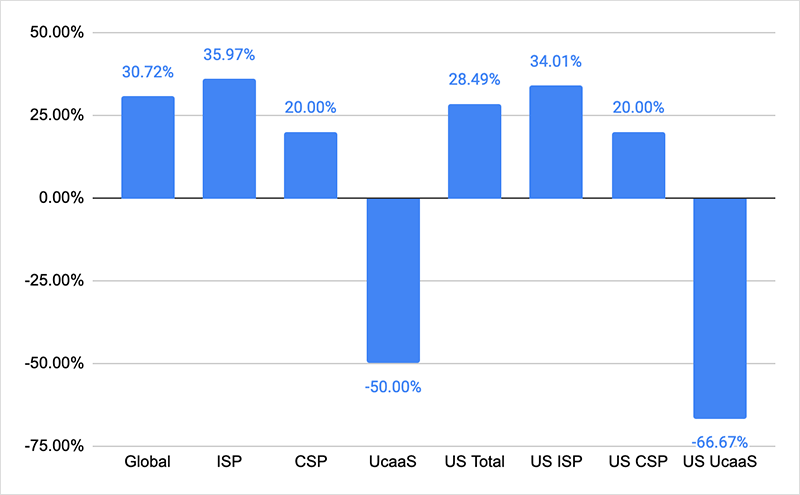
Globally, total outages were up 31% with the major contributor being the ISPs where outages increased by 36% week over week. Looking at this from a US perspective, the total outages increased 28%, while US centric ISP outages increased 34%. In line with the total outage increase, we also saw cloud provider network outages (CSP) rise 20% compared to the previous week , this was both in the US and on a global basis. In fact, the only service category where the number of outages fell was collaboration app networks (UCaaS).
But while there were more outages observed, compared to the previous week, the mood of the Internet could be described as calm. When we look at the anatomy of an outage, there are certain characteristics that go a long way to determining how big or disruptive an outage is. These include aspects such as duration and time of day, but also “blast radius” (how far the outage ripples out across the Internet, in terms of location and peers directly impacted by the outage). The difference of the outages observed last week compared to the previous week was those characteristics that saw a lot of short-duration outages, heavily localized, which minimized their blast radius and downstream/customer impacts. Whereas the outages the previous week had one significant outage both in terms of duration and the magnitude of the blast radius.
Context is everything.
Unlike last week where a single outage (Facebook) dominated the news cycles and overshadowed all else, this week nothing big enough happened that made international headlines. And what did happen, while higher in volume, provided no real cause for concern once the context of the event was established and understood.
While a large number of ISP outages occurred, not all ISPs are created equal, especially when it comes to size and reach. The way an ISP’s infrastructure is architected is almost “serial” — so one relies on another, which in turn relies on another. If one has an outage, it can have a significant flow-on effect. That’s particularly true for a tier one ISP, since they have a lot of transit, peering or sub-wholesale arrangements that smaller ISPs rely on.
But we didn’t see that in the week’s numbers. Rather, what we saw was a range of smaller ISPs having outages. These outages may have ranged from minor maintenance works to catastrophic, but the impact was heavily localized and the “blast radius” of the impact was low relative to the scale of the Internet.
It’s a similar story when tracking sudden spikes and drop-offs of network traffic on paths to ISPs, CSPs and other service provider types. Since earlier this year, we’ve seen outage figures inflated by SECaaS (Security as a Service) products, such as DDoS mitigation appliances, secure proxies and secure gateways that, in the course of their correct and proper functioning, produce traffic patterns that, to the untrained eye, exhibit outage conditions.
Without the correct context, it appears providers are suffering from a large number of degradations that have to be routed around. But attributing these “incidents” to SECaaS interventions, as opposed to disruptive outages, often results in speedy recognition and traffic re-routing that limits (even eliminates) disruption to providers’ user populations.
Context comes from having good visibility and good supporting data. The more you see, the more you know, and the better you can understand and handle an anomalous traffic event.









