Networking teams need to act quickly when performance issues or customer-impacting outages occur. Those who are typically the first to respond to these types of incidents, however, may not always have the expertise to decipher complex problems spanning multiple domains as they occur, often relying on signals from various systems to help them identify and triage the problem—or even manually combing through data to detect anomalies across their corporate network.
This approach to troubleshooting has become time-consuming and inefficient, potentially delaying incident response and resulting in prolonged user impacts. Moreover, networking teams can struggle to prioritize mitigation efforts as they lack context on how problems are impacting their users’ digital experiences. This requires expert knowledge across different domains, which can be challenging for less advanced networking professionals.
For over a decade, ThousandEyes has been empowering networking teams to instantly troubleshoot complex digital experience issues using correlated, cross-layer visualizations that are updated in near real-time. Now, we’re introducing our latest innovation, Event Detection, which aims to simplify and accelerate the troubleshooting of performance problems.
Event Detection: Automated, Simplified Troubleshooting
Event Detection is a new feature in the ThousandEyes platform that automatically detects incidents as they occur, and brings them to your attention—dramatically simplifying and accelerating the troubleshooting process. It does this by finding, analyzing, and correlating critical issues across your digital delivery stack automatically.
Event Detection uses advanced algorithms to detect widespread issues impacting the networks and applications you are monitoring. It examines the performance data to identify anomalies and pinpoint the source of problems common across the network and applications, highlighting affected locations or applications. Event Detection also eliminates false positives and “noisy” data that can complicate troubleshooting efforts.
Event Detection also categorizes ongoing and past incidents based on their problem domains. This helps networking teams to better understand patterns over time. Incidents can be grouped into categories such as server, network, proxy, or network-related outage.
Real-world Use Cases for Event Detection
Over the past several months, some ThousandEyes customers have been using Event Detection within their environments to solve complex challenges. Let’s look at three of their stories below.
Customer 1: An Online Trading Platform
With websites hosted in multiple locations around the world, this online trading platform understands the critical need to quickly detect website issues and determine their exact location. Due to the time-sensitive nature of online trading, any downtime or unavailability of their website could result in severe consequences.
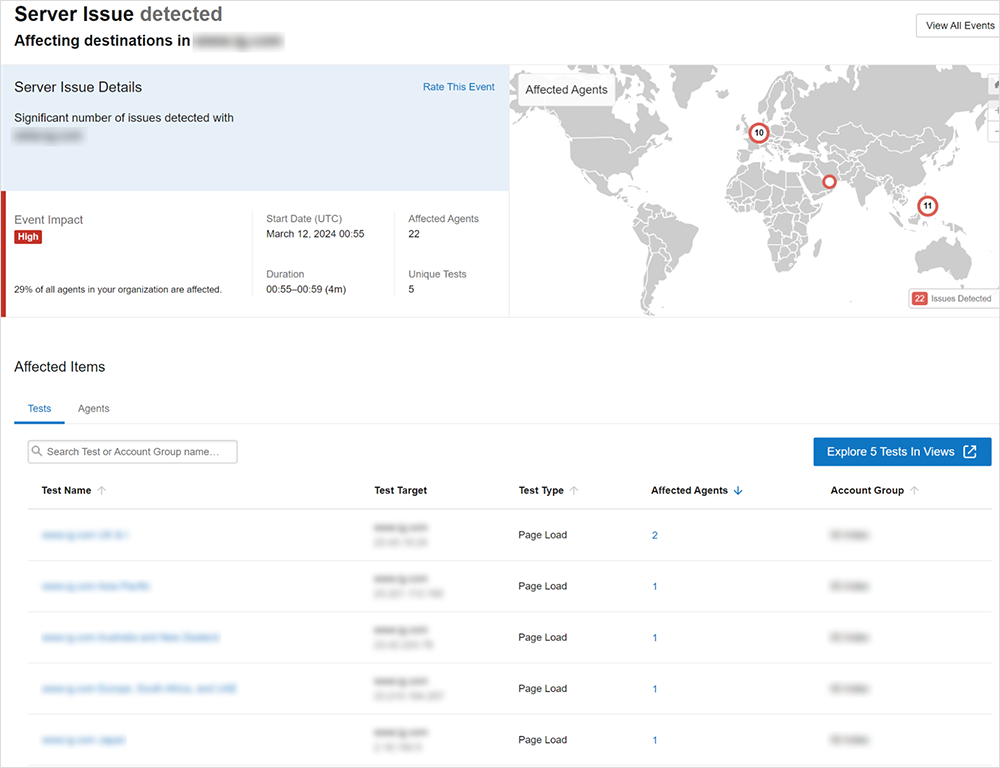
On one occasion, the online trading platform experienced an issue when its website was not accessible across the world for a period of five minutes. At the onset of the incident, ThousandEyes alerted them to the problem and helped them visualize their customers' digital experience from vantage points around the globe.
By exploring data from these vantage points in Views, they found that the problem was related to the servers hosting their application. In this case, their applications worldwide used a content delivery network (CDN), which was where the fault lay. Using Event Detection, they were able to rapidly identify that the issue was not related to the network or the Internet but rather to their service provider that was delivering the application to its users.
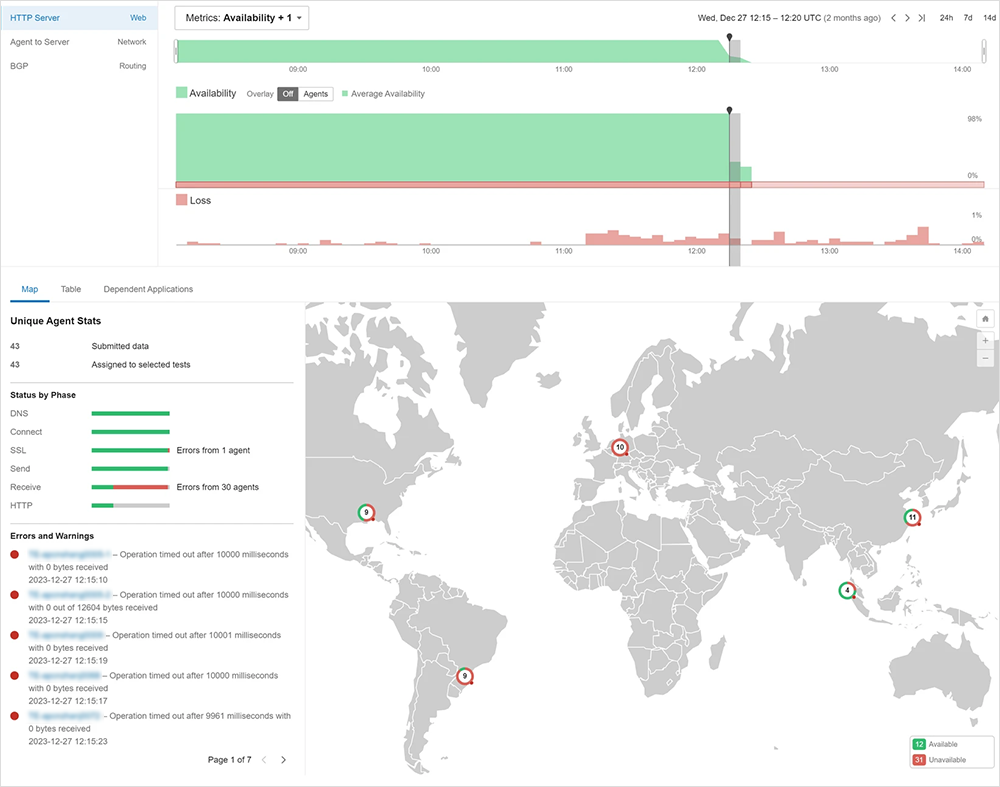
According to the customer, during one incident, Event Detection helped the online trading platform identify the issue within 2-3 minutes, resulting in a 90% time savings. They stated that Event Detection saved them from spending 20 minutes for each outage or alert and helped them understand the scope of the problem.
Customer 2: A Leading Chemical Producer
A leading chemical producer in Europe with operations around the globe required a solution to monitor its network performance seamlessly across multiple sites and applications without complications. While the chemical producer’s IT team was ultimately responsible for assuring employees' digital experience, a third-party vendor managed and operated its network. To identify pertinent issues without requiring additional setup, the IT team turned to Event Detection.
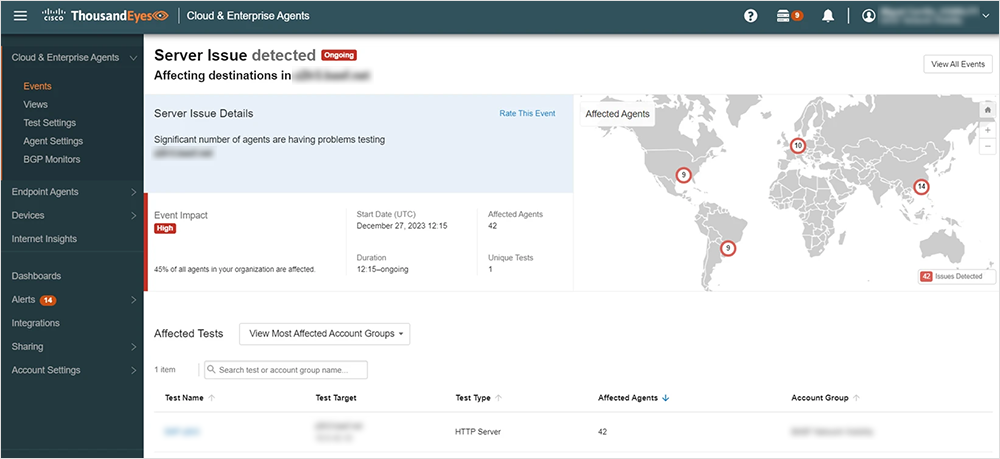
Recently, the chemical producer faced a significant global issue that impacted several of its locations. These locations were unable to access local SAP instances, which they suspected could be a network issue. Fortunately, ThousandEyes' vantage points were monitoring the local SAP instances, providing crucial data that helped them correlate the issue.
In this case, Event Detection identified that the problem was not related to the network but to the server or application itself and affected around 42 sites. After the incident, they confirmed that the root cause of the problem was a database that handles all the requests centrally from all the local SAP instances.
Customer 3: A Leading Mining Company
A leading metal and mining company based in Australia has a network team that relies extensively on specialized tools to diagnose and troubleshoot issues. In an effort to reduce the time spent on each tool, the team wanted to concentrate on domain identification and the related data across domains. They discovered that Event Detection could help them by automatically correlating data across all the ThousandEyes vantage points they are using to test various applications, which piqued their interest.
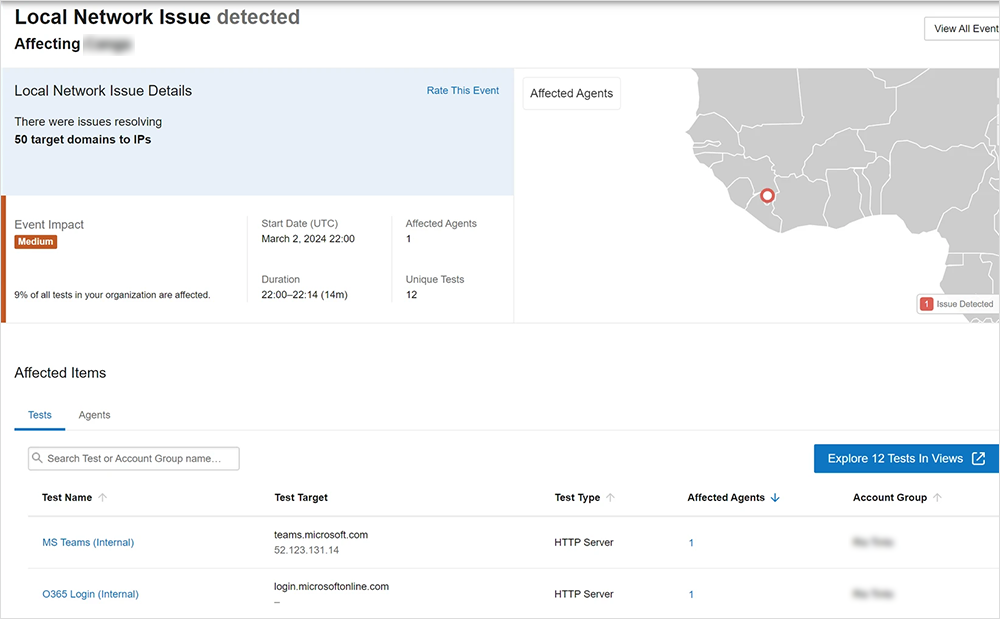
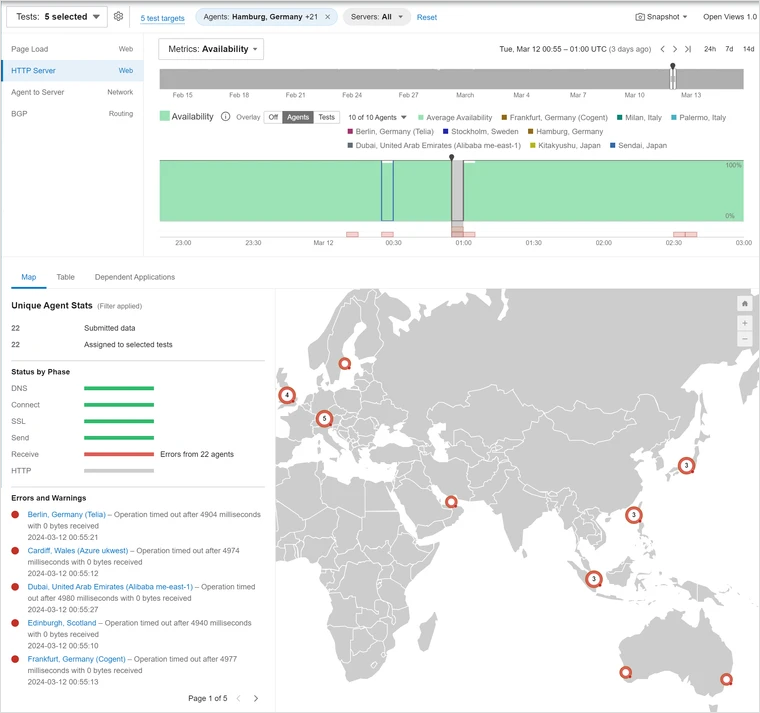
Event Detection proved invaluable when an incident occurred at one of the mining company’s sites. It revealed that there were local connectivity issues at that location related to resolving domain names. With the problem domain highlighted in Event Detection, the mining company was able to concentrate its investigation and discovered that the primary DNS server for that site was offline, and the secondary DNS server was now handling all requests.
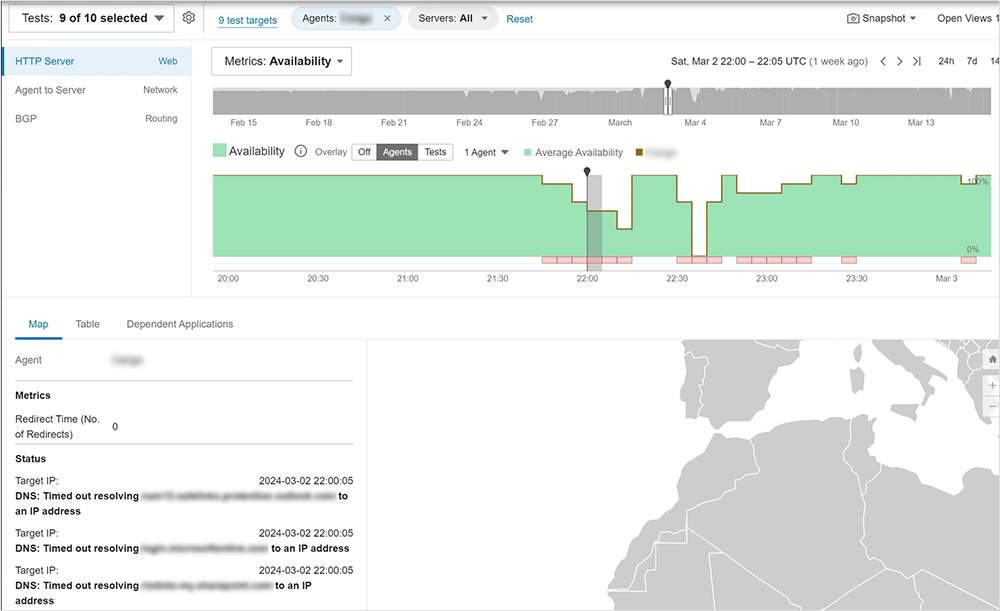
While it was good to know that the DNS failover worked as expected, the mining company also discovered a latent DNS issue that was previously unknown to the services team. This discovery helped them to avoid a potential catastrophe in the event that the secondary server also failed.
Troubleshoot Without a Trouble
Event Detection is a powerful feature that enables teams to swiftly pinpoint the problem domain of issues. It automatically groups both current and past incidents based on the problem domain, which provides better insight into service disruptions over time. This feature significantly reduces the time it takes to detect and identify issues, known as mean time to detect (MTTD) and mean time to identify (MTTI).









