
Introduction
Kafka Streams is a light-weight open-source Java library to process real-time data on top of an Apache Kafka Cluster. Like any other stream processing framework (e.g., Spark Streaming or Apache Flink), the Kafka Streams API supports stateless and stateful operations. The Kafka team built it on top of the core Kafka producer and consumer APIs, so mainly, it shares similar advantages and disadvantages. In the Endpoint Agent, one of the monitoring solutions we have here at ThousandEyes, we use Kafka Streams quite a lot. In this post, I'm going to walk you through our journey using it and discuss some of our use cases and problems we faced deploying these services in Production.
Scheduled Tests
One of our first use cases was the Scheduled Tests. Scheduled Tests are network tests that are run against an IP or hostname and provide network statistics. The idea is that our backend dynamically schedules them to be run periodically on an agent that matches some configurable labels. To make it more concrete, agents that are under a specific network or a particular location should run a test against a domain example.com every 10 minutes.
The initial implementation of the backend consisted of a scheduled job that would run every 15 minutes, attempting to assign tests to agents. After some stress testing, it was clear that this approach was not going to work for ten or even hundreds of thousands of agents, for the following reasons:
- Scheduling performance degraded as agent count increased
- There was no easy way to scale this service horizontally, only if we run it on powerful machines
We needed a different approach to this problem, so we derived inspiration from the way our Endpoint Agents check-in with our backends every 10 minutes.
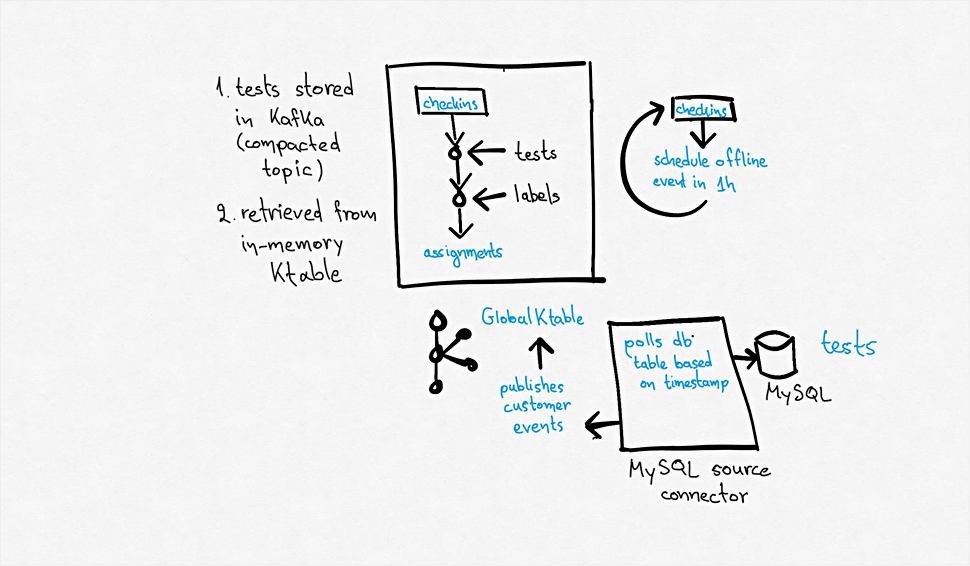
We began pushing those events in Kafka, and by utilizing the Kafka Streams DSL, we would match agents to tests, and then store those matches in a Kafka Streams KTable. We could now scale out by adding more Kafka Streams threads or instances, maxing at the number of partitions of the topics of the topology.
We then leveraged Kafka Streams Interactive Queries feature to fetch those tests from the corresponding state store, which lived in memory on one of the instances.
Reacting to the check-in stream was not enough, however. In the Endpoint Agent world, agents come and go, and we needed a way to de-associate tests from offline agents. To do this, we built a micro-service that would generate an offline event per agent as soon as they stopped checking in with our backends for an extended period. Then we modified the Scheduler code to consider that event.
Here, I need to mention that we recently launched some improvements on our backend, going completely reactive by introducing web-sockets for the communication with the agents—but that’s a topic for another day.
Other Sidekick Services
That was not the only sidekick service that we built for the Scheduler.
As I mentioned before, to effectively work with Kafka Streams and be able to join check-ins with other data, we needed to work with "KTables." So we needed a way to convert our customer’s metadata that we stored in MySQL tables into "KTables." Although we did our research and tried a couple of technologies like "Kafka Connect" and "Logstash," we rolled out our connectors because it was easier to reuse our existing codebase and also our microservices infrastructure for scaling and monitoring.
We called them Scheduler Kafka Connectors, and implementation-wise, they are polling SQL tables for changes.
When they detect a change, they produce an event with the row changes to a compacted topic, and we can consume that topic as a GlobalKTable from the Scheduler app.
A minor caveat here, we are not deleting entries in MySQL; we mark them as deleted, so it was easier for the described technique to work.
If you need to do something similar, I would suggest taking a look into something like Debezium, which taps into the bin log of the MySQL databases and publishes the changes to a Kafka topic. This way, you are not polling the database tables, and you can even get events when the application code deletes a row.
Now, we needed to display the assignments of an agent over time and even keep historical data. By querying the KTable mentioned before, we wouldn't be able to get that information, because it is just a key-value store. Instead, we build sink connectors that would consume from that topic and move that data in a datastore appropriate for querying timeline data like Elasticsearch or MongoDB.
We developed these connectors using Spring boot, Spring Kafka, and we used SQL configuration language for each connector, instead of having to add code every time we needed to start a connector.
The configuration looks like:

And an instance can run multiple of them. Of course, we scale these connectors horizontally on top of Kubernetes with the help of Kafka consumer groups. We went ahead and built sink connectors only for Elasticsearch and MongoDB, and they are currently powering our data ingestion pipeline for our timeline data in the Endpoint Agent.
Reconciler
As we involved the Scheduler, we realized that scheduling on the check-in and offline events wasn't enough. When the user changed their test configuration from our web application, the agents weren't aware of those changes, and they kept submitting data using stale configuration until they checked in again, got rescheduled and got the correct context.
To fix this, we needed a way to notify the Scheduler to retrigger scheduling in those circumstances.
That's how we came up with the Checkin Reconciler. This service keeps track of the latest active agents that are still checking in with our backend in a KTable. When a customer changes a test, then those agent check-ins are sent as input to the Scheduler, rebalancing the "tests" for the whole agent fleet of the customer's account.
This tiny application enabled other uses cases, too:
- On the fly, decide which agents match specific criteria. Because the KTable lives into memory (also on disk through the use of RocksDB), we expose it with Interactive Queries as a Rest API, and other services can query it.
- Scrape statistics from that KTable, how many agents are active on a specific point in time without affecting the datastore that stores those check-ins, that might be used by operational dashboards or other parts of the application.
Windowed Aggregations for Alerting Use Cases
Another use case we had for stream processing was alerting on a windowed aggregation of data regarding our Browser Session Alerts, which are alerts based on data generated by the browser activity of the users we monitor with the Endpoint Agents. We experimented with two technologies for this use case: Kafka Streams and Akka Streams. We built prototypes with both but decided to go with Kafka Streams mostly due to its fault-tolerant KTable capabilities and, of course, because we were more knowledgeable at the time with Kafka Streams.
In the beginning, it all began with the Window operator:

We soon realized that Kafka Streams relies on a continuous refinement model, meaning that it emits new results whenever records are updated. That's not ideal for our alert triggering use case since every update on the aggregation gets published, which means that "alerts" are triggered even when the final aggregate is not complete.
After reading about it, we figured that we could circumvent this by using the Suppress operator, which made the situation better. We were now emitting only one event when the window was getting closed.

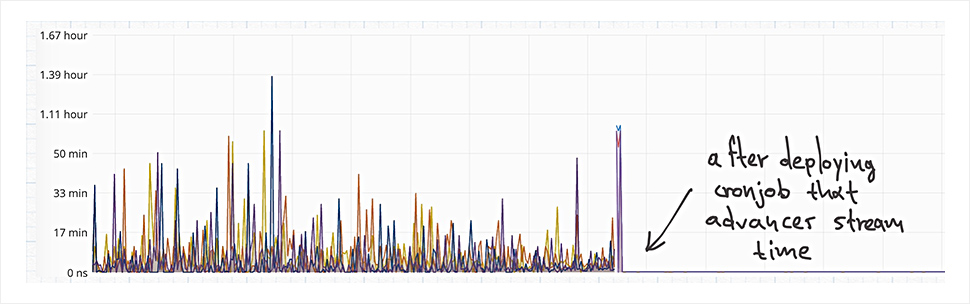
Then we deployed it, and we added Prometheus metrics to figure out how fast windowed aggregation was getting emitted downstream after a closed window.
The results weren't that encouraging, we kept noticing significant differences of 30 seconds and sometimes even a whole minute.
The reason behind this was that Kafka Streams:
- builds a windowed aggregation based on event time, which is the time that the event happened
- has an event-driven ‘close window’ operation, meaning that a message needs to arrive with an event time that is after the close window timestamp so that Kafka Stream can close the window
To circumvent this, we built a cron job that fires an empty event on all partitions every time that Kafka Streams needs to close a window. That way, we advance the stream time of the windowed aggregation ourselves, and we keep it in sync with the system clock time. And the graph looks like:
Production Issues
Kafka Streams Interactive Queries
When you are querying the Kafka Streams application for a key, through a Rest API, for example, you are not sure where exactly a particular key lives. So when you hit an instance, if the key is missing, you need to use the Kafka Streams metadata to find out to which instance the key actually lives and make a request there.
The problem we faced was when we started seeing responses taking too long from that service, after investigation, was that the instances were querying each other until their pools were exhausted, resulting in them being unresponsive. To fix this, we made sure that no more than two hops take place when we want to retrieve a key.
Other things that went bad include:
- defaults in timeouts when calling between the Kafka Streams instances, which needed to be lower
- having a poorly configured liveness probe on Kubernetes, which could have resolved the situation, by restarting the instances that had their thread pools stuck
Kafka Streams Significant Delays when Starting
The most significant delay when Kafka Streams is rebalancing occurs from rebuilding the state store from changelog topics. Changelog topics are compacted topics, meaning that Kafka retains the latest state of any given key in a process called log compaction.
Kafka organizes topics on Brokers as segment files. Whenever a segment reaches a configured threshold size, Kafka creates a new "segment," and the previous one gets compacted. By default, this threshold is 1GB. Kafka appends new records to the latest "active" segment, and no compaction takes place. Therefore, most state persistence stores in a changelog end up continuously living in the "active segment" file and are never compacted, resulting in millions of non-compacted changelog events. For Kafka Streams, this means that it needs to read many redundant entries from the changelog.
Given that state-stores particularly care about the latest state, this delay is not useful at all. Reducing the segment size triggers a more aggressive compaction of the data. Therefore, new instances of a Kafka Streams application can rebuild the state much faster.
Conclusion
Kafka Streams makes it easy to build scalable and robust applications. Combine it with technologies like Kubernetes, Prometheus, Spring Boot, and you have a spaceship.
As soon as you start building applications with it, you enter the event-driven world, and many things need to be modeled differently from a regular web application. Also, event time becomes an essential aspect of the application, but at the end of the day, you will reap the benefits.











