ThousandEyes actively monitors the reachability and performance of thousands of services and networks across the global Internet, which we use to analyze outages and other incidents. The following analysis of LinkedIn’s service disruption on March 6, 2024, is based on our extensive monitoring, as well as ThousandEyes’ global outage detection service, Internet Insights.
Outage Analysis
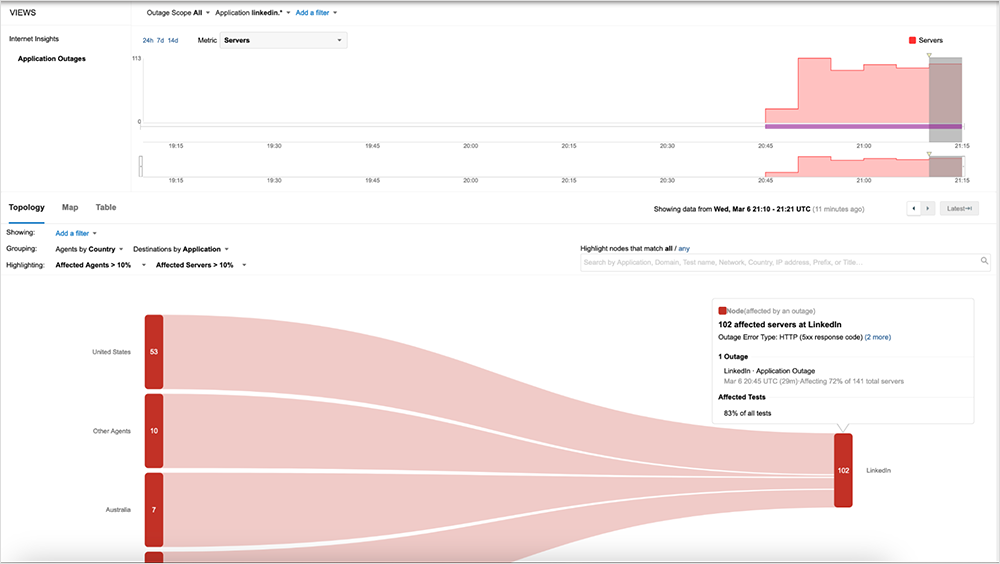
On March 6, LinkedIn experienced a service disruption that prevented some users from accessing its applications on mobile and desktop as well as some of its business services, including LinkedIn Ads and Marketing Solutions.
Availability Drops, But the Network Appears Normal
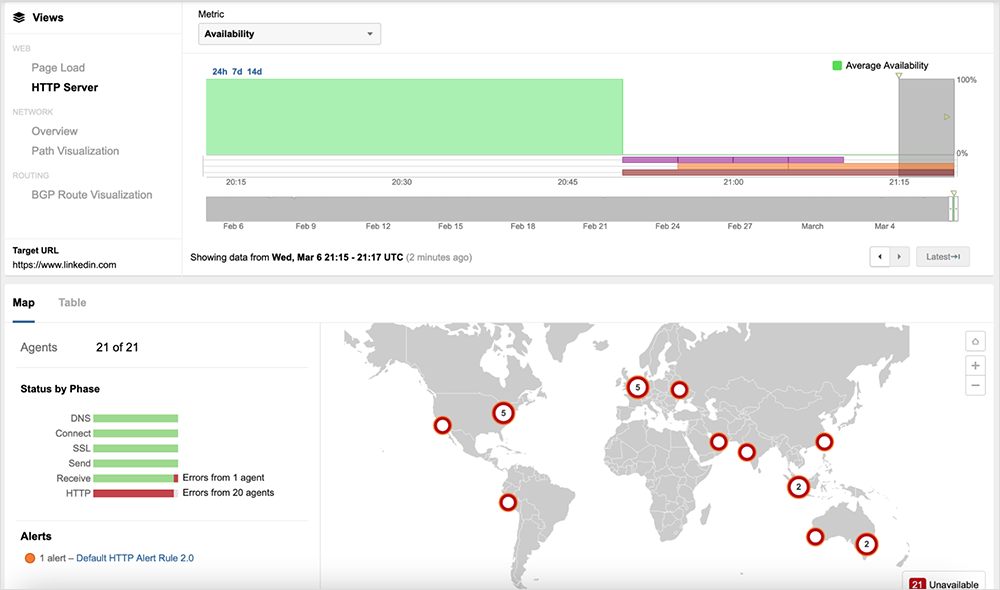
ThousandEyes first observed the issue around 20:45 UTC (12:45 PM PST), when global vantage points captured a sudden drop in service availability. This incident appeared to occur simultaneously across regional locations, but there appeared to be no significant network issues that would have impacted reachability to LinkedIn.

Timeout Errors at the CDN Edge
According to LinkedIn, the company uses Azure Front Door (AFD) for its edge CDN infrastructure. In short, AFD connects with users locally and then forwards those requests to an application server located in one of LinkedIn's data centers. During the outage, AFD Points of Presence (PoPs) were working normally and responding to incoming requests, as ThousandEyes observed; however, as the outage progressed, the AFD PoPs began reporting a series of errors, which can indicate an issue with the backend system. The initial errors were related to OriginTimeout, indicating that the AFD was unable to establish a connection to the origin server within the configured timeout period.
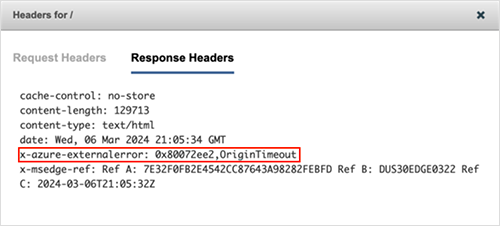
It is possible that the error occurred due to network connectivity problems between AFD and the origin server. HTTP 503 service unavailable errors followed the timeout errors and further indicated a backend server-side issue.
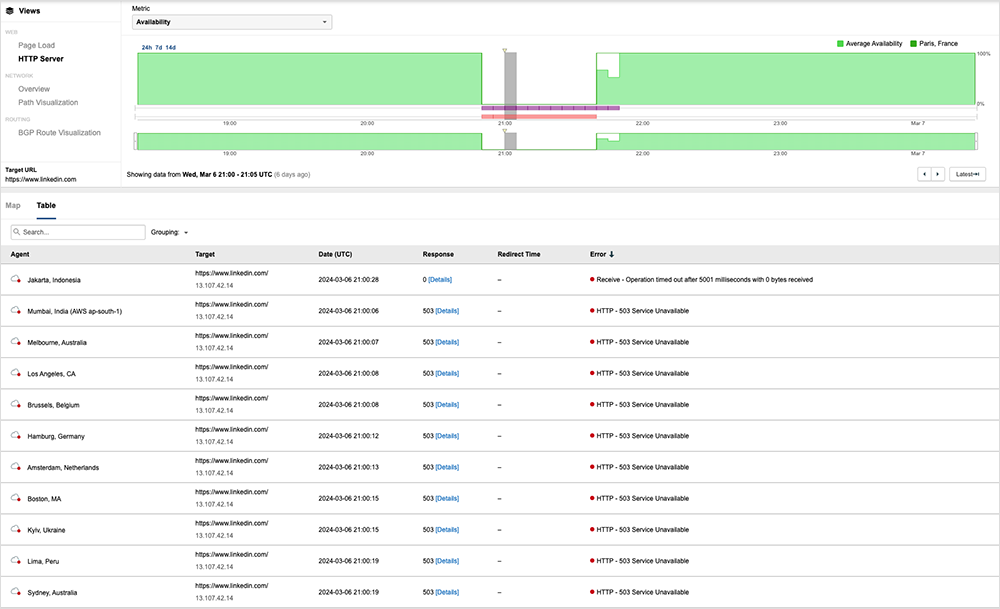
Services Are Restored Globally
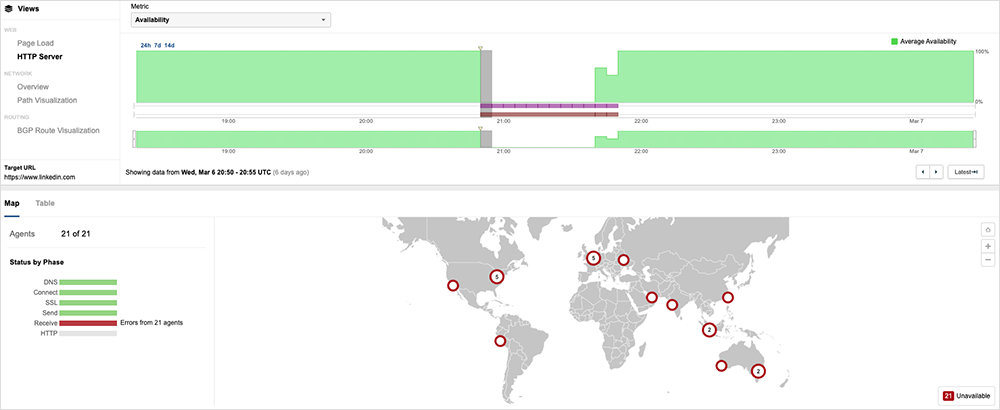
The LinkedIn service began to recover around 21:38 UTC (1:38 PM PST). As the service was restored, ThousandEyes began to observe some HTTP 502 bad gateway responses for some locations. This can indicate that an invalid response was received, likely because the origin could not understand or process the request, which can be a sign of system overload as the service is restarted or restored. The recovery was completed for all users around 21:50 UTC (1:50 PM PST).

Lessons Learned
-
Understand your service dependencies. Applications are intricate systems that rely on a vast network of plugins and dependencies to function correctly. These dependencies, in turn, rely on other services to operate, creating a complex web of interdependent services and technologies. However, any component in the delivery chain can fail to perform as expected, causing a ripple effect that impacts all downstream and upstream services. This can result in unresponsive applications and error messages.
-
Know who to hold accountable for resolution. To understand the root cause of such issues, it's crucial to identify the responsible party. This helps determine whether the issue lies with you (the user), the application, or a third-party service. Having this information is essential for effective operations because once you have the necessary data, you can implement appropriate plans, processes, and mitigations to minimize the impact on your users.
-
Always have a resiliency plan. It's important to note that remediation may not always be within your control. Therefore, it's crucial to have a backup solution in place to keep your business running in the event of an outage. For example, when LinkedIn experienced an outage, some users and companies turned to other social media platforms to post updates and keep their businesses running smoothly. This demonstrates the importance of having contingency plans in place to ensure business continuity and minimize the impact of such issues as much as possible.
[Mar 6, 2024, 2:00 PM PT]
At around 21:38 UTC (1:38 PM PST), the LinkedIn service started to recover. As of 21:50 UTC, the incident appears resolved for all global users.
Explore an interactive view of the outage in the ThousandEyes platform (no login required).
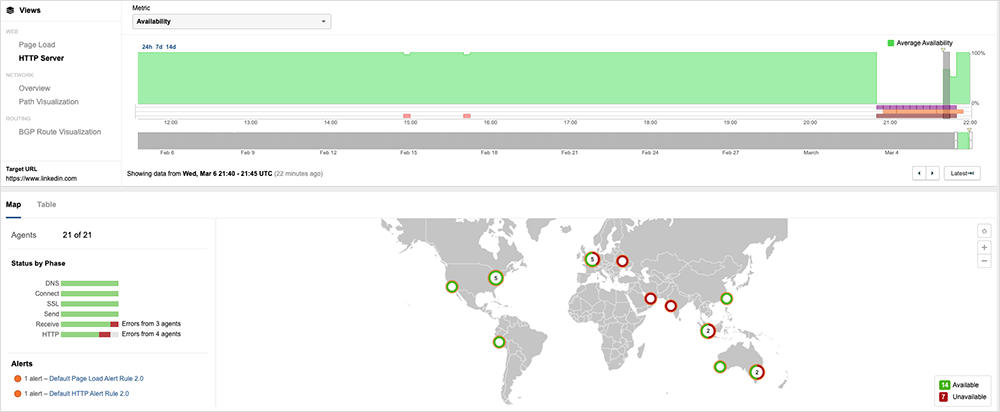
[Mar 6, 2024, 1:45 PM PT]
At approximately 20:45 UTC (12:45 PM PST), ThousandEyes detected a service disruption for global users of LinkedIn. The disruption is manifesting as service unavailable error messages, likely indicating a backend application issue. The incident is ongoing.
Explore an interactive view of the outage in the ThousandEyes platform (no login required).