ThousandEyes actively monitors the reachability and performance of thousands of services and networks across the global Internet, which we use to analyze outages and other incidents. The following analysis of Microsoft’s service disruption on January 25, 2023, is based on our extensive monitoring, as well as ThousandEyes’ global outage detection service, Internet Insights.
[Jan 26, 2023]
Summary of Findings
- The disruption was triggered by an external BGP change by Microsoft that impacted connected service providers, leading to destabilization of global routes to its prefixes, which led to significant packet loss and diminished reachability of its services and those of its customers.
- The bulk of the incident lasted approximately 90 minutes, although residual connectivity issues were observed into the following day.
- During the incident, ThousandEyes saw changes in traffic distribution via DNS that may have indicated steps to steer traffic away from impacted areas within Microsoft’s network.
Outage Analysis
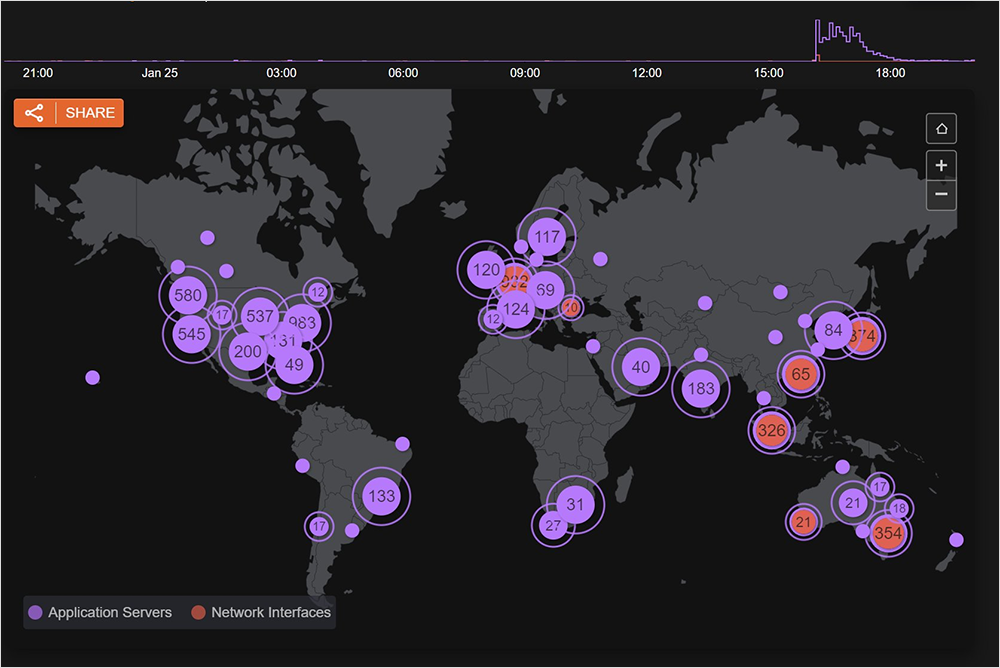
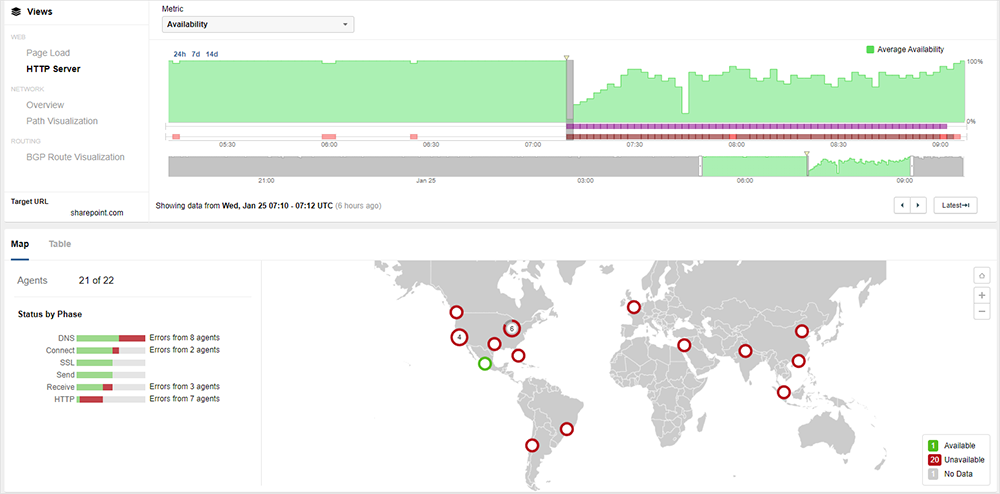
Beginning at approximately 7:05 AM UTC, Microsoft experienced a significant global disruption that impacted connectivity to many of its services, including Azure, Teams, Outlook, and Sharepoint (see figure 1).
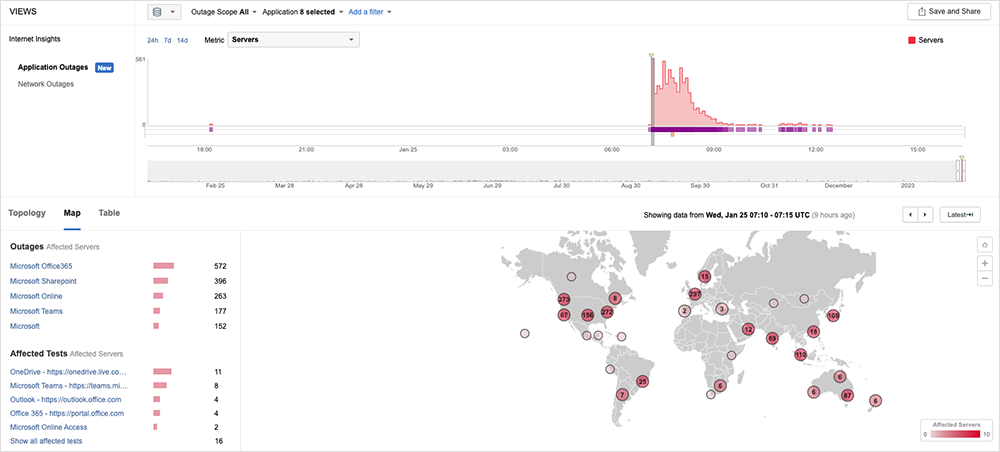
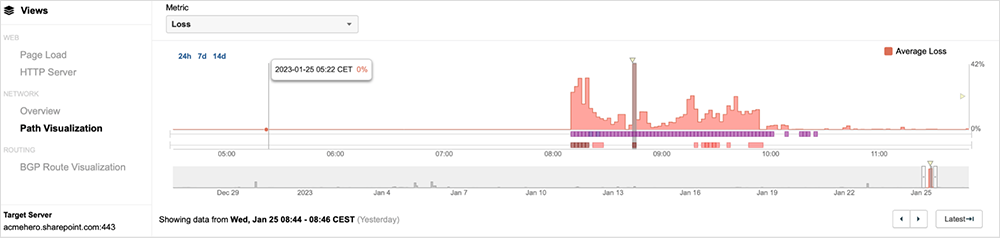
During the incident, ThousandEyes observed high levels of packet loss as Microsoft and other services became unavailable due to connectivity disruptions at and around Microsoft’s network (as seen in figure 2).
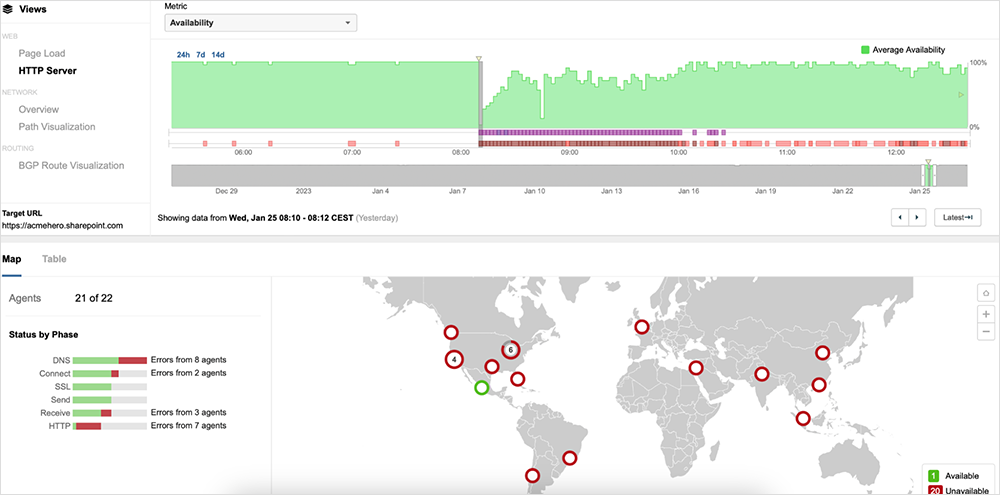
This observed packet loss translated directly into service degradation. Many users connecting to these services at that time would have experienced HTTP and DNS timeouts. Our data shows timeouts in the application "Receive” time, further indicating the effect of the network on service availability. Figure 3 shows the spike in packet loss that directly correlates with BGP events that were also observed.
Explore an interactive view of this outage event in the ThousandEyes platform. No log-in required.
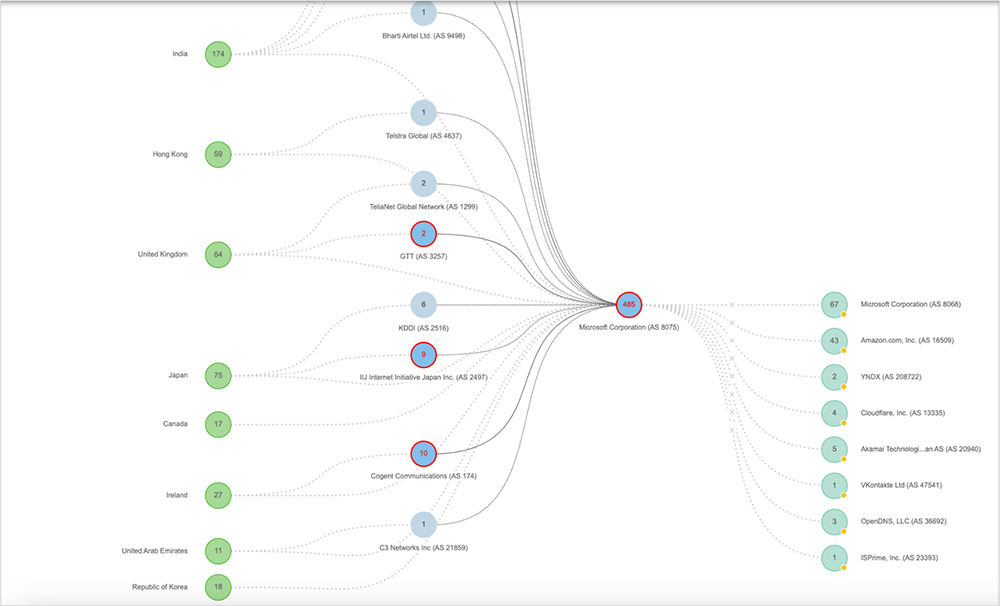
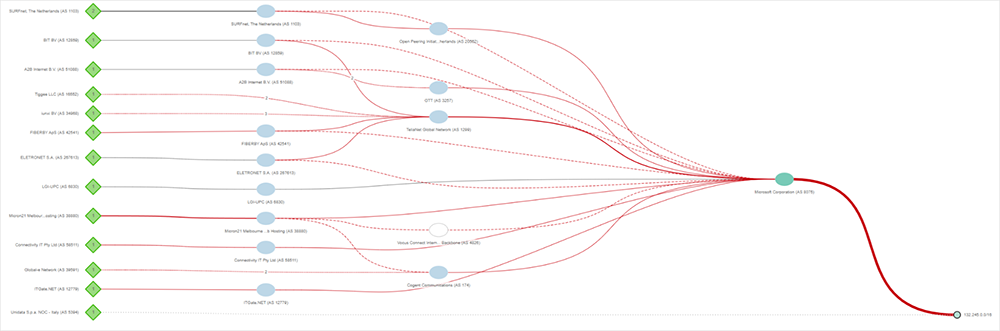
ThousandEyes observed a significant number of BGP route changes for prefixes advertised by Microsoft's AS 8075 beginning at just after 07:10 AM UTC, immediately precipitating the packet loss. Both /24 prefixes, as well as summary prefixes (such as /12 prefixes) were impacted.
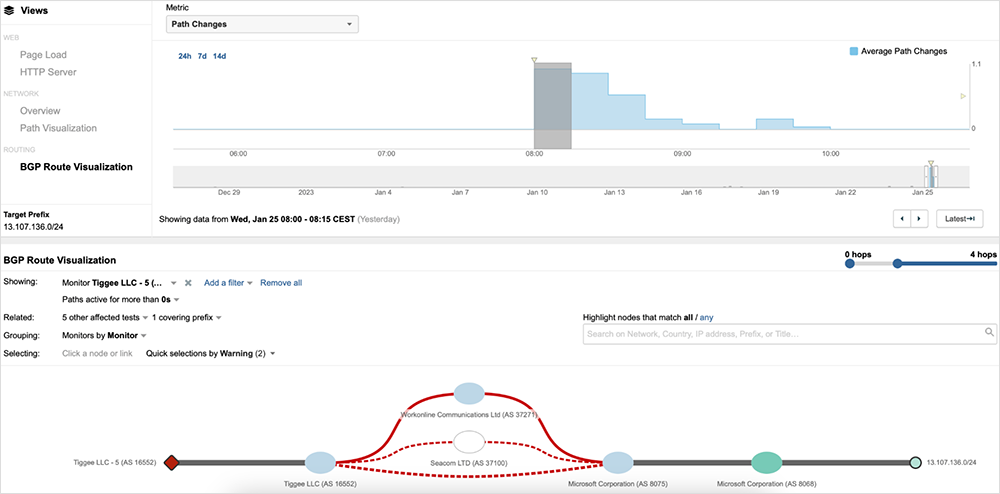
At the start of the changes, route announcements of affected prefixes appeared to be withdrawn and, shortly after, re-advertised. These withdrawals appeared to largely impact direct peers. During the brief withdrawal periods, with a direct path unavailable, the next best available path would have been through a transit provider. Once direct paths were readvertised, the shortest AS_PATH path would have been selected, resulting in a reversion to the original route. These re-advertisements repeated several times, resulting in significant churn (route table instability). Given the rapid nature of the changes, it's likely an automated process was involved.
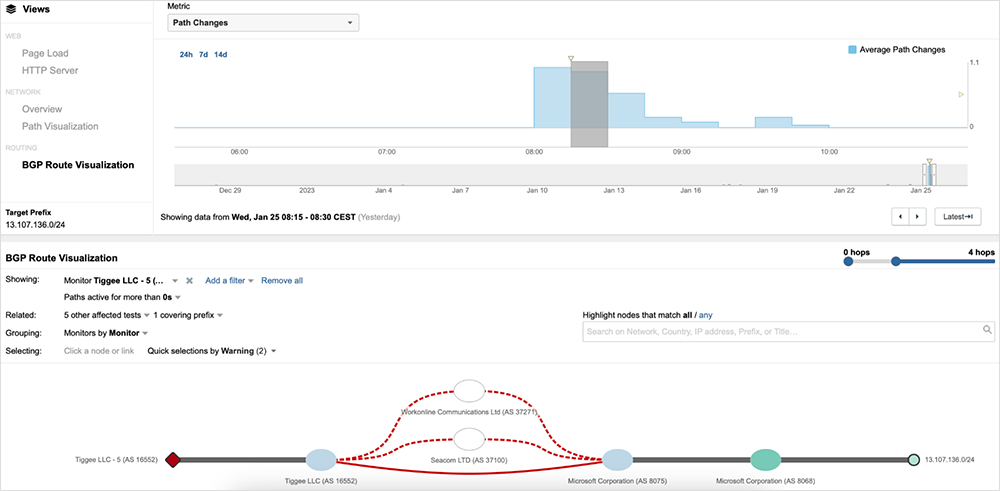
ThousandEyes continued to observe this cycle, until routing mostly stabilized and routes settled on the shortest AS_PATH (direct peering) at 07:22 UTC. However, a spike in BGP changes returned just after 07:40 UTC, when ThousandEyes observed a re-occurrence of the behavior, as seen in figure 6.
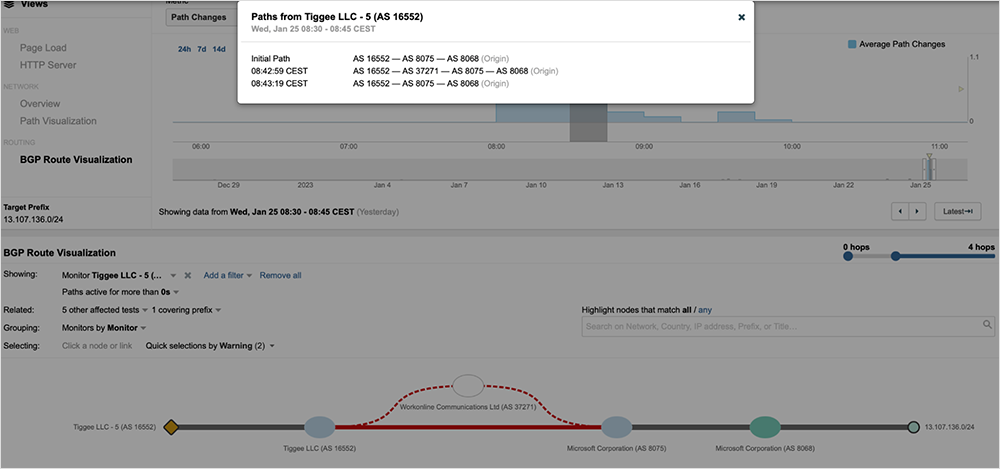
Around 08:10 AM UTC, ThousandEyes observed additional BGP updates. The shortest route was restored, and connectivity for the majority of route tables observed remained stable from that point on.
Rapid changes in traffic paths coupled with a large-scale shift of traffic through transit provider networks, would have led to the levels of loss seen throughout this incident. Figure 7 below shows significant levels of packet loss, with some user locations experiencing as high as 100% packet loss.
As previously mentioned, most routing tables stabilized at around 08:10 AM UTC. However, the last significant BGP update activity happened at approximately 08:45 AM UTC, after which service providers reverted to utilizing the best, shortest part that was in place before the outage occurred. With routing stabilized, packet loss began to settle, ultimately subsiding five minutes later at around 08:50 AM UTC, which marked the end of this event.
Conclusions and Recommendations
Operators of network and digital services must make constant changes, small and large, for maintenance, security updates, business growth, and so on. Any time a digital system is touched, there can be a risk of something going wrong and no network is immune to such risks. Change management is the constant bane of IT Operations teams, but with diligent process, change reviews, prepared rollback plans, and quality assurance testing prior and after any change, the risks of disruption can be greatly reduced.
The second need of every IT team is robust visibility, including end-to-end visibility across all technology domains involved in delivering the service to their users. Knowing as quickly as possible that performance has drifted from desired levels is critical to reducing the pain to your customers, users, and partners. Notification of a fault is no longer sufficient today; IT teams must also be able to quickly pinpoint where the fault is and who owns and can fix it. Visibility is essential for rapid problem remediation, rollback of a change gone wrong, and being able to know with confidence that user experience meets your expectations.
While this was a large outage in terms of global impact and number of affected services, it was apparent that Microsoft did indeed quickly begin mitigation methods, signaling that they had ample visibility of the problem as well as rollback and remediation plans. The length of this outage is likely a result of an operations team ensuring that they are doing the right thing given the scope of the outage they were facing.
Want to know more? Watch the on-demand webinar to see what ThousandEyes observed during this major outage and walk away with practical lessons that your ITOps team can implement.
[Jan 25, 2023, 09:00 AM PT]
At around 7:05 AM UTC, Microsoft started to experience service related issues. At the same time, ThousandEyes observed BGP withdrawals and a significant number of route changes which resulted in a high amount of packet loss, ultimately affecting various services. See an interactive view in the ThousandEyes platform. No log-in required.
More details about the event:
- Microsoft started experiencing service related issues around 07:05 AM UTC.
- ThousandEyes observed that many Microsoft BGP prefixes were withdrawn completely but then almost immediately re-advertised. The nature of this event indicates an administrative change, likely involving some automation (due to scope and rapidity of changes).
- The changes had a cascading impact on global routing tables, causing significant churn. Prefixes were either withdrawn or re-advertised to transit providers resulting in more churn (BGP Best Path Selection Algorithm is used to find suitable paths, so, initially traffic was rerouted through transit providers before more direct paths were eventually restored).
- The BGP changes resulted in a high amount of packet loss, with many user locations experiencing 100% packet loss.
- When it comes to application-related impact, our data shows timeouts in the application “Response,” further indicating the effect of the network on service availability.





