We recently wrapped up the fall edition of ThousandEyes Connect San Francisco. Keeping up with tradition, we had some excellent speakers who shared some interesting stories about how they monitor their business critical infrastructure. As our first guest speaker we were thrilled to have Jim Morrison from Quantcast, a digital advertizing company focussing on audience measurement and real-time advertising. As Senior Manager of Edge Services at Quantcast, Jim leads the team that builds and maintains low latency, high throughput serving systems.

Jim kickstarts the presentation by setting the stage for how Quantcast gathers metrics to curate audience-targeted advertising. Quantcast comprises of two distinct product lines: Quantcast Measure is the data collection engine that provides free audience measurement for a website and Quantcast Advertise ingests the data provided by Measure for targeted advertising. Quantcast Measure collects non-personal, per-user data ranging from basic demographics to income and education level and sometimes even the user’s propensity to buy an Aston Martin versus a Jaguar! These two engines together handle upto 2.5M requests per second and each request is handled with a latency of less than 100ms. Processing such high data is no simple task and an indication that the network and underlying infrastructure is critical.
Pixel, the Pixie Dust
Jim moves on to introduce the “pixel”, the magic potion that facilitates gathering of highly customized data for Quantcast Measure. A pixel is an asynchronous tag, a snippet of javascript, that loads in the background upon the first view of a web page. This script triggers a simple HTTP request to the pixel-serving architecture that responds with a 1x1 transparent image that allows Quantcast to record user-information. The pixel serving architecture is key to Quantcast Measure and designed to have quick response times with latency less than 100ms. Jim recounts, “the goal is to never slow down a publisher’s or customer’s web page, which means the pixel serving network should be fast and available at all times.”

Jim uses an example from a pixel attached to his own website, to draw attention to the fact that while the web page can initiate multiple HTTP requests, only a couple of those requests target Quantcast. He also points out that it takes ~ 50ms to serve the pixel, which is quite impressive! “Anything lower than that, we would need to get closer to the users”, says Jim. So, how does one get closer to the user?
Behind the Magic Door
The pixel-serving architecture has two critical components. One is the sites themselves, that are located close to the users and serve the pixel requests with less than 100ms latency. The second component is aggregating the data in a common location to convert it into actionable intelligence for the Quantcast Advertise engine.
Pixel-Serving Sites
Quantcast has 12 globally distributed pixel-serving sites based on geo-DNS. Geo-DNS provides a user in location X a DNS mapping to a web server in a nearby location. This allows Quantcast to route users to the nearest pixel-serving site based on the IP address of the user. Interestingly, Quantcast couples the geo-based DNS with anycast for redundancy. Anycast is an addressing and routing methodology wherein multiple physical endpoints are logically represented by a single IP address. So if a site goes down, users are routed to another site with the same IP address without any service interruption. Every site has a simple top-of-the-rack switch that uses a single BGP default route to a Tier 2 ISP which further peers with the rest of the Internet. In Jim’s words, each site consumes a “dirt simple cheap footprint.”
Pixel-Consolidation
While serving the pixel quickly is critical, it’s not the only component of this well-oiled machine, says Jim. Aggregating the global data is important to ensure that a single data set is analyzed to provide insights to their customers. So, how does Quantcast aggregate the data from the globally distributed pixel-serving sites? Well, through the Internet of course!
One of the most interesting aspect of the Quantcast network is that they rely completely on the Internet for data collection and aggregation. Each pixel-serving site is like an island on the Internet. There are no MPLS or VPN circuits that connect the pixel-serving sites to the aggregation location. And when it comes to security, all authentication and encryption is done at the application layer, eliminating the need for a secure transport.

Monitoring the Internet-Centric Architecture with ThousandEyes
Maintaining an infrastructure with low latency and high throughput while completely relying on the Internet is no easy task. Jim recalls that while evaluating external vendors last year, ThousandEyes intuitive UI and historical timeline features proved extremely valuable. Aligned with the two-tier architecture, Quantcast uses ThousandEyes to monitor both end-user experience and the data aggregation site.
Monitoring End User Experience
Quantcast leverages ThousandEyes Cloud Agents with instrumented HTTP tests to emulate end user experience and validate availability of the pixel-serving sites. Rephrasing Jim, “We want to know if our sites are up and actually available to the user and if the pixels are loading fast enough.” In addition to monitoring latency and the underlying network path, ThousandEyes also helps troubleshoot DNS level issues. As shown below, Quantcast was able to detect a DNS issue in the Indian sub-continent and quickly troubleshoot the root cause.
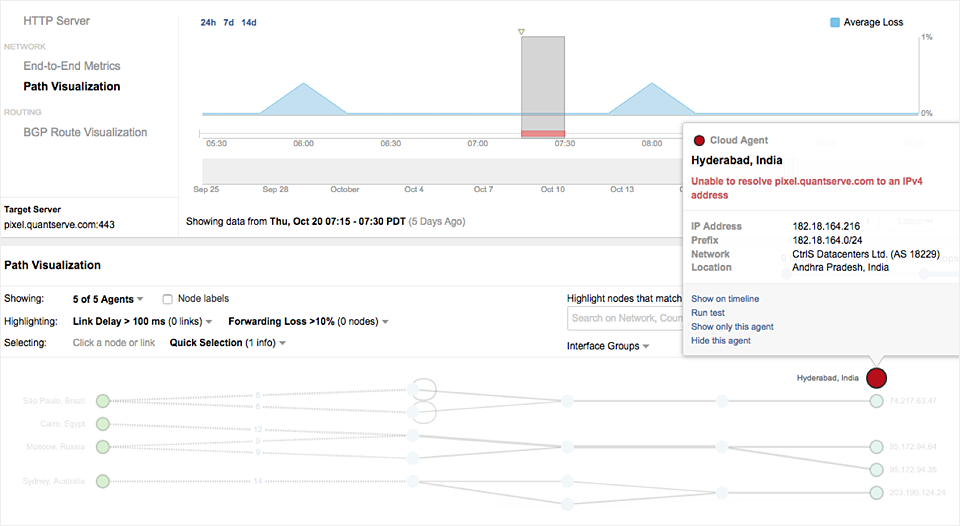
Monitoring the Aggregation Engine
Quantcast also leverages ThousandEyes Cloud Agents to emulate the globally distributed pixel-serving sites and measure reachability and latency to the aggregation site. Traffic from the pixel sites usually traverse multiple hops, primarily over two intermediary ISPs, before reaching Quantcast. As the pixel-serving sites are connected to the aggregation site via the Internet, understanding what went wrong and where is crucial to troubleshooting and establishing a root cause. Jim explains, “using the Internet for data transfer means it’s subject to random failures. Monitoring helps us understand service degradation and detect where exactly in the network they happen.” Jim finishes his talk leaving the audience with an interesting thought. He believes that application software needs to be more resilient and self-healing to network failures as that would significantly lower service disruptions and time to repair.
We are getting ready to host our next ThousandEyes Connect in New York next week. Stay tuned for more interesting talks!









