In this post from ThousandEyes Connect New York, we’ll discuss the presentation by Luca Salvatore, Network Engineering Manager at DigitalOcean. Luca heads the network team at the cloud Infrastructure-as-a-Service (IaaS) provider based in New York City.

During his talk, Luca describes the challenges of managing networks at DigitalOcean and how his team has used ThousandEyes to streamline the process of responding to customer complaints and troubleshooting network problems.
The Evolution of Networking at DigitalOcean
Founded in 2011, DigitalOcean is a virtual private server provider with data centers around the world. Luca describes DigitalOcean’s rapid growth: “In early 2012, we had a few hundred customers running 1000 to 2000 VMs. Today, we have 11 data centers, 12,000 physical servers, and we’re hosting over half a million VMs (Virtual Machines). Next year, we plan on opening another two or three data centers.”
Luca leads a very lean team of five network engineers who manage DigitalOcean’s substantial network infrastructure: “We’re primarily a Juniper shop, so we use MX routers, AX switches and QFX switches. Our latest design is using all QFX switches; we build 40Gb down to the servers—we have 40Gb top of rack, a 40Gb spine aggregation layer, a 40Gb core, and we buy tons of transit from all the Tier 1 providers. We’re also really big on peering, so in every single one of our locations we’re on an IX (Internet exchange) point, sometimes two or three, depending on the location.”
DigitalOcean has also begun implementing software-defined networking (SDN), one of the biggest buzzwords of the last few years. “What that really means for us at DigitalOcean is separating the control plane from the data plane. The data plane is where the action happens—where things are forwarded very quickly. And to scale a data center and half a million Droplets (which is what we call our VMs), you really need a control plane that knows where everything is and is able to talk to and build the tunnels between your hypervisors and data centers. Our next set of data centers will be our first set of fully software-defined networks.”
Major Challenges
One of DigitalOcean’s biggest challenges is scaling. “In our early days, we built gigantic Layer 2 networks. It gets scary—some of the biggest EX9200 switches that we use have a maximum ARP (Address Resolution Protocol) entry count of 256,000 ARPs, and when you run a data center that has 100,000 or 200,000 VMs, you start to see some strange issues pop up on these switches. We’ve really pushed a lot of the Juniper gear to levels it hasn’t been pushed before.”
Another challenge has been deployment. “When you need to build data centers and add racks quickly, you need to have a very automated process. We have a system using Juniper’s Zero Touch Provisioning that allows us to plug a switch into the network, and it pretty much builds itself. We can build out 20 or 30 racks in the time it takes a switch to download its version of JunOS, which is 5 minutes.”
As a cloud provider, Internet stability is also a major concern. “The Internet is an unstable place, and you really need tools that can give you insight into what’s going on. Obviously, ThousandEyes is a great tool for that.”
Latency and packet loss are among the most important performance metrics for DigitalOcean. “What we find is customers are actually pretty aware of latency and packet loss. We get tickets logged all the time from customers who notice a 20 or 30 millisecond increase to their Droplet.”
Lastly, Luca discusses DDoS attacks: “Denial of Service attacks are a constant problem; right now, I’m sure we have a DDoS attack happening—it’s nonstop. Most of the attacks, mainly coming out of China, are from people’s home devices that have been compromised. And it really doesn’t take much for a few thousand compromised machines to spin up a lot of traffic. Places, like CloudFlare, getting 400 to 500Gbps DDoS attacks are actually not that uncommon these days.”
The network team at DigitalOcean certainly has a lot on their plate. In the next section, Luca explains how ThousandEyes has helped with his team’s daunting workload.
Why ThousandEyes?
So what kind of solution was DigitalOcean looking for? “We needed to know what our network looked like from outside our network. Before we used ThousandEyes, we used Pingdom; it was okay for what it did, but it really didn’t give us much visibility into how our network looked from a customer’s perspective. So we did a trial of ThousandEyes and everyone was pretty much on board from the first day.”
Luca also describes how his team uses ThousandEyes: “We started monitoring every single data center that we have. We choose about 30 to 40 Cloud Agents and point them at a Droplet in every data center. Then we start to track latency and packet loss. We also run a couple of Enterprise Agents in three of our locations so we can track bandwidth. The main thing we’re looking at is, how does the customer see us? Latency and packet loss are really good things to know from a customer perspective.”
Interestingly, DigitalOcean also trains their support team with ThousandEyes. “Every new support member that comes on board is trained to use ThousandEyes. This allows us to give our customers a really high level of support. If we get a big flood of tickets because some transit carriers had an outage, the support guys can log into ThousandEyes and see what’s going on; then they don’t have to ask the network engineers. It means that they can respond to the customer with some really good information on the first response. We don’t have to go back and ask, ‘Can you give us a traceroute? Can you give us some pings?’ We can actually say, ‘Yes, we’ve got a problem, we’re troubleshooting it,’ and then update our status page. It makes our support a lot quicker, and it means there are fewer interrupts for the network team.”
The team also uses alerting features on ThousandEyes, which are integrated with an on-call system, PagerDuty. For example, “if a location has 20% packet loss for more than 10 minutes, it’ll trigger an alert to a network engineer who can troubleshoot the issue. Typically it’s really easy to see where our problem is, and it’s easier to fix that problem once you’ve identified it.”
Luca also takes advantage of the reporting function: “We use it for our monthly KPI meetings. I present a lot of graphs out of ThousandEyes—I just take a screenshot and put it onto our internal slide decks, and the executives love it, so it makes my life easier. I don’t have to go digging for data.”
Examples from Real-Life Network Monitoring
Though the issue isn’t in the network for the majority of events, sometimes it unfortunately is. Luca shows data from an outage caused by a DDoS attack in DigitalOcean’s Frankfurt location. The four nodes circled in red are the links connecting DigitalOcean’s edge routers to the rest of the world. The DDoS attack was roughly 100Gbps; all links were maxed out at 100%. DigitalOcean does have some remote blackholing, but it unfortunately didn’t kick in during the outage. “You can see that every location we were monitoring from was reporting a lot of packet loss. It was easy for us to identify that there was a problem with our routers.”
.")
Sometimes, the issues are less obvious. Luca shows a screenshot from a Comcast outage in New York City: “You can see there are are a bunch of green Cloud Agents getting through to the endpoint, which is a Droplet hosted in our New York City data center. There were a bunch of things that were working fine, but there were also a lot of Comcast customers who were complaining. Our support team logged on, saw this, and were able to say, ‘It looks like a Comcast problem; we’ll get our network engineers to jump on that.’ We just shut down our Comcast link in New York City and the problem went away.”
 in New York City.")
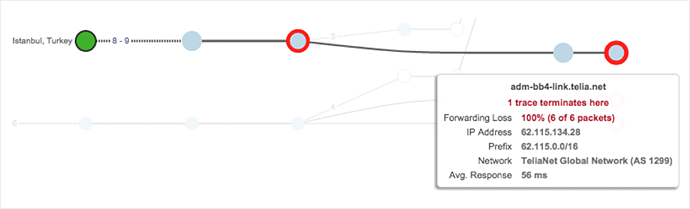
And, as a final example, sometimes the data looks impossible to interpret. Luca shows a problem his team encountered last week with one of their peers, Telia, that was performing software upgrades on their core infrastructure. Telia had forgotten to down a BGP session somewhere.
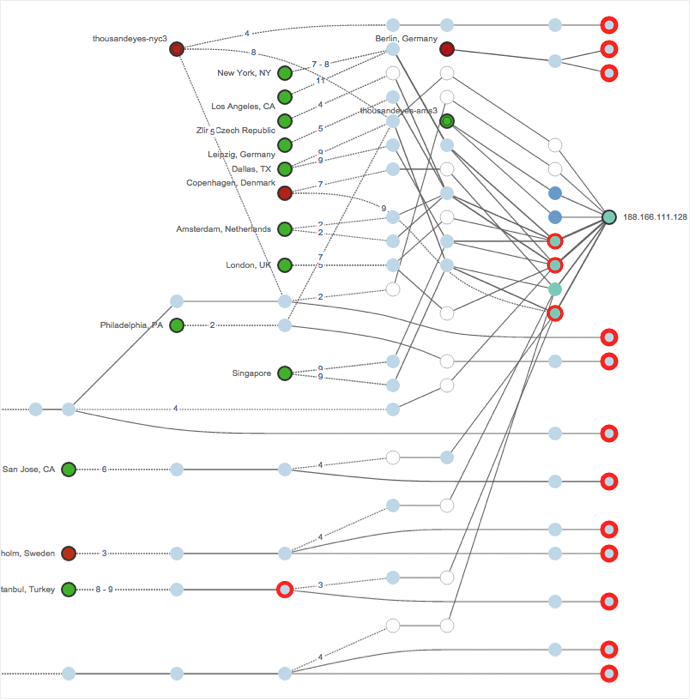
But Luca maintains that the answer is still clearly shown in the data: “It’s actually really easy to see if you just drill down: we can see that the route terminates at this router in Telia. It didn’t have a route back to DigitalOcean, so it’s dropping 100% of traffic. We just downed our link and the problem went away.”
Final Thoughts
Luca summarizes his talk with a few final thoughts, reiterating some of his main points about managing networks at DigitalOcean.
- “Cloud computing has been a buzzword in the industry for 5 or 10 years now; it’s definitely here to stay. Companies like DigitalOcean are proof of that. You don’t get to hosting half a million VMs without it being something that is going forward. It’s going to be huge.”
- “Automation is definitely necessary, especially when you’ve got two and a half thousand network devices. If I want to roll out a change to every single one of them, we use Juniper’s PyEZ Python library. It takes about 20 minutes to push out a change to a few thousand devices.”
- “Customers are sensitive to problems on the Internet, and they’re actually aware of what latency and packet loss are, so you need to have a good answer when they experience issues. Tools like ThousandEyes really help with figuring out exactly what’s happening. A lot of customers send us traceroutes and expect us to have a good answer—without these types of tools, we really can’t.”
- “Visibility is key. Being a company that lives on the Internet, we really need to know the state of the Internet in all of our regions. ThousandEyes is great for that.”
- “Having your support team trained on all the tools and knowing how to respond to a customer is key.”
- Share the tools: “All of our monitoring tools are shared with everyone in our company; there are dashboards up all over our office, including some of the ThousandEyes customized dashboards.”
For more details from Luca’s comprehensive talk, check out the video of the full presentation below.









