Beginning at 4:20 UTC June 17 (9:20 PM PDT June 16), Akamai’s DDoS mitigation service, Prolexic Routed, experienced a service disruption that rendered some of its customers’ websites unreachable for varying lengths of time — some just minutes, others longer. At that time, ThousandEyes observed a notable surge in network outages, as service providers peering with Prolexic lost their connections to the service, resulting in 100% traffic loss.
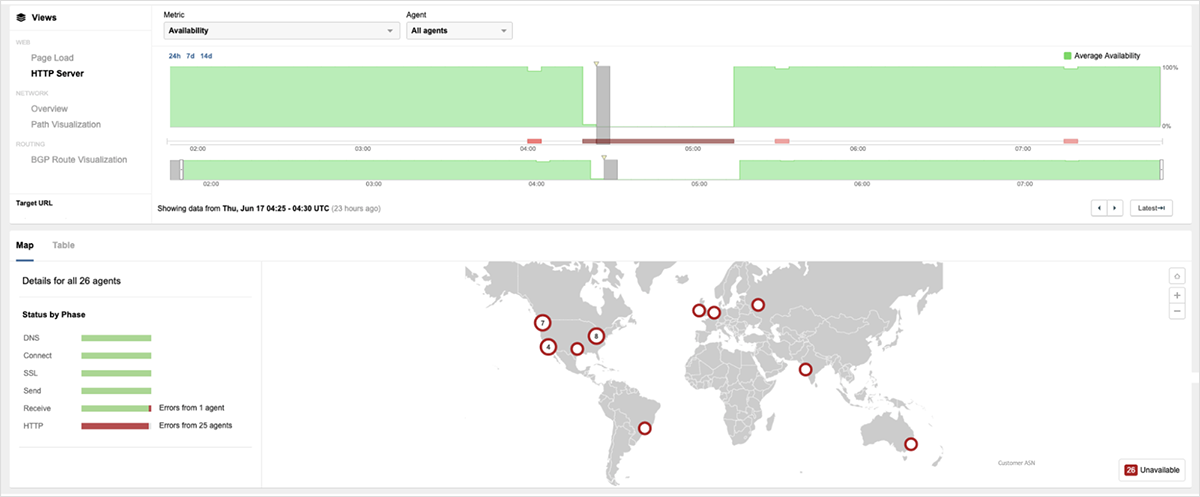
The impact of the outage was only at its most severe in its initial minutes, with residual impact minimal in terms of sites affected. Akamai ultimately resolved the issue and restored the service at 8:47 UTC.
In Akamai’s statement announcing service restoration, it noted that the outage was not due to either a system update or cyber attack but instead by inadvertently exceeding a routing table value used by the service. This is consistent with ThousandEyes’ observation of the incident, in which we saw a total loss in reachability of the service. In the event of a DDoS attack, the DDoS mitigation service would still be in the BGP path to sites under attack as it worked to absorb the malicious traffic. This was the case when Prolexic successfully defended Github from the largest recorded DDoS attack in Internet history.
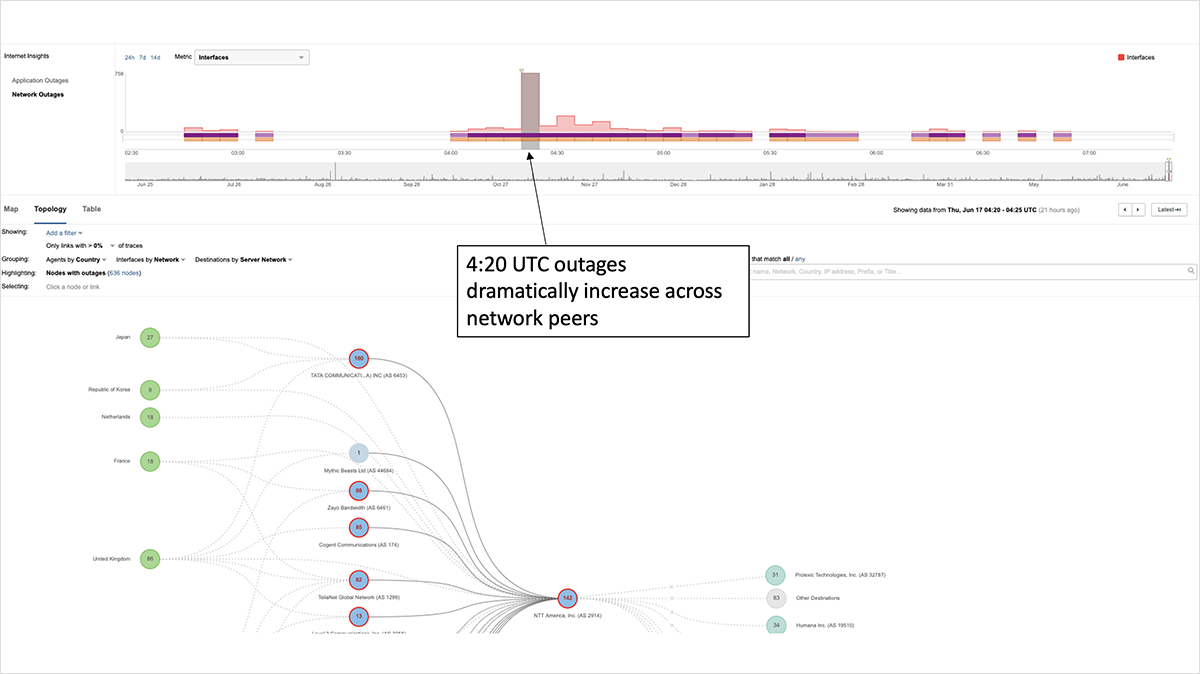
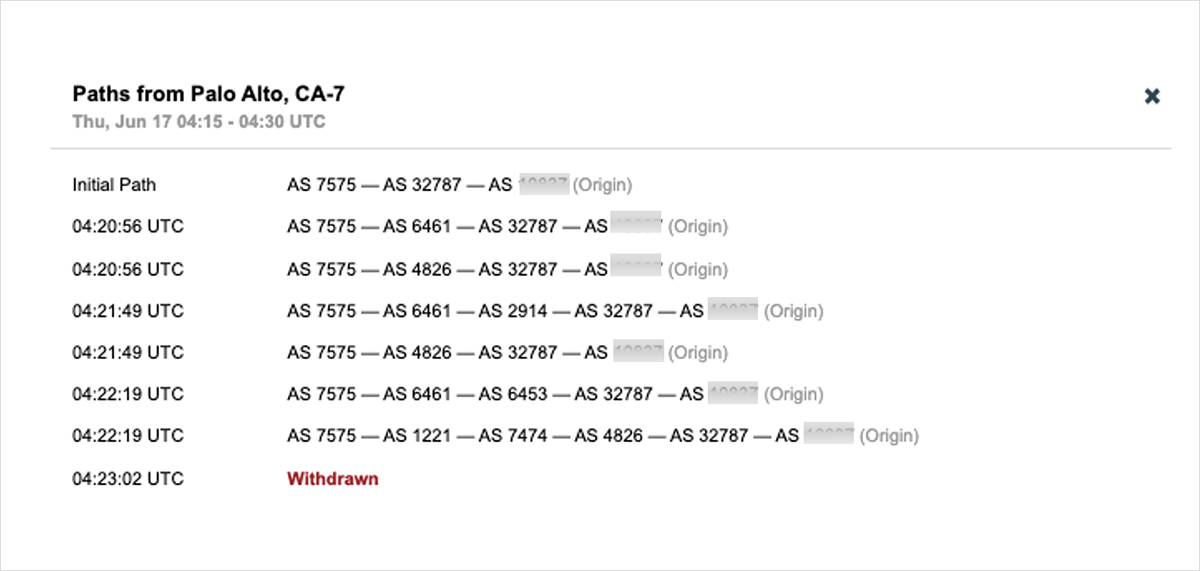
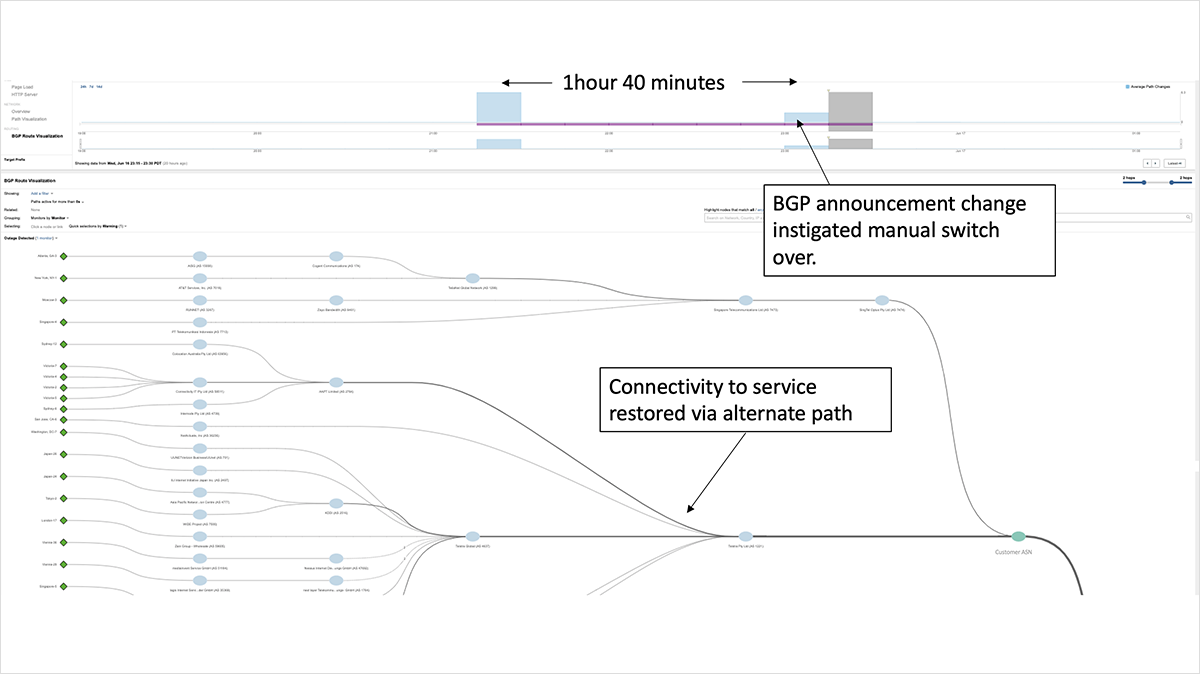
In this case, Prolexic quickly removed routes to its scrubbing centers to allow customers to failover to their backup services. ThousandEyes saw widespread BGP route flapping in the minutes just after 4:20 UTC, as downstream service providers attempted to reach the impacted target destinations by switching to alternate, less optimal BGP paths before eventually all routes were withdrawn. Figure 3 shows rapid route switching for an impacted service, with progressive paths getting longer (less-optimal), as the service provider sought a viable route. The route was eventually withdrawn and removed from this provider’s routing table—mere minutes after the onset of the incident.
In contrast, a major transit provider outage last year impeded its customers’ ability to recover over a sustained period of time as it continued to advertise routes to its customers even though it was unable to handle traffic at the time. By continuing to advertise these “zombie” routes, many of its customers were unable to steer traffic to alternate paths to restore service reachability. By quickly taking the action of removing routes, Prolexic minimized the impact to its customers, as customers were free to reinstate BGP announcements through other providers to route around the issue. Once that action was taken, customers who quickly restored connectivity to their sites were the ones who had redundant processes already in place.
Same Outage, Different Outcomes
Prolexic Routed is designed to protect against DDoS attacks by advertising its customers’ network prefixes (with their permission), then sanitizing the incoming traffic, before handing it off to the customers’ network. The service can be deployed in on-demand mode, where traffic is redirected when an attack is identified, or in an always-on mode, where all the traffic is routed through the Prolexic infrastructure. The always-on customers were those impacted by this outage. However, two factors influenced how much of an impact the outage had on individual Prolexic customers.
Firstly, the time of day the outage occurred meant that it predominantly fell outside of regular business hours for the U.S. As such, customer impact was minimal. However, the outage occurred in the middle of the working day for Australia and other countries in the Asia-Pacific region.
The second factor was how quickly the customer was able to bypass the Prolexic environment to restore connectivity and services for its users. Organizations that had an automated failover system (or pre-established back up plan) in place designed to trigger redundancy processes were able to recover connectivity very quickly—in some cases, within minutes.
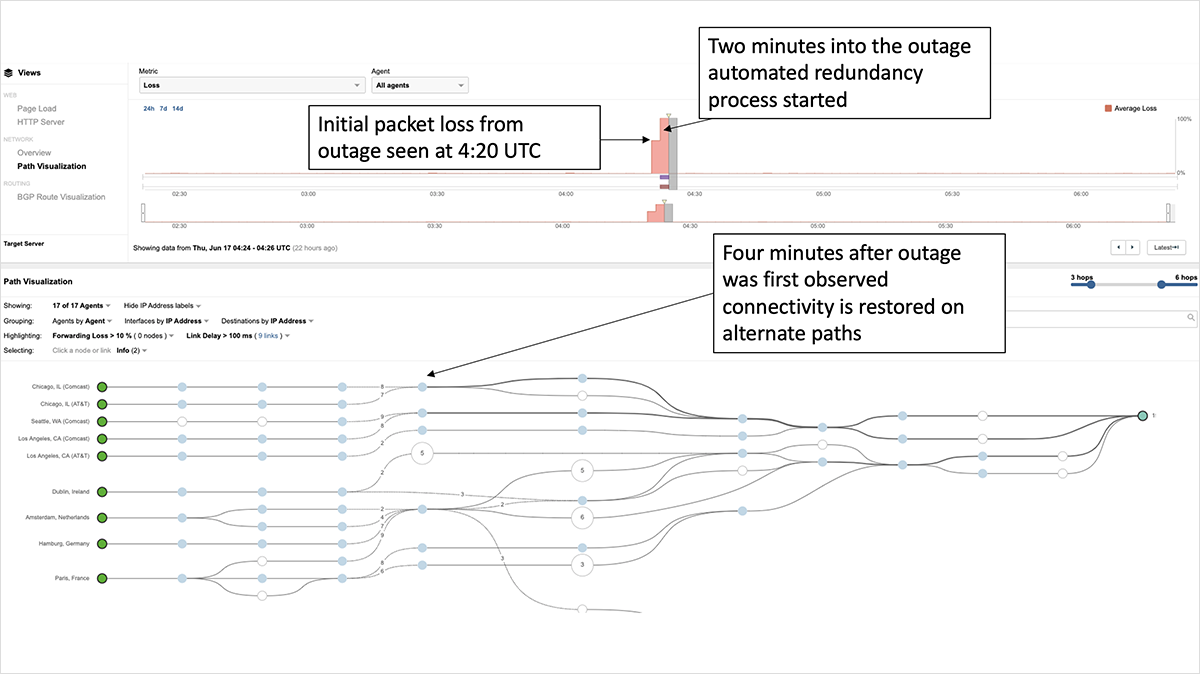
For example, the Prolexic customer shown in figure 3 (a large U.S.-based financial service) bundled several /24 prefixes under a /19 prefix that it was already announcing through two transit providers, effectively routing its users around the outage. The extremely rapid switchover and recovery of the service suggests an automated response to some condition related to the outage, rather than due to a manual recovery process.
In comparison, organizations that relied on manual intervention took longer to propagate the changes needed to re-establish connectivity via alternate paths. For example, a financial service based in Australia was impacted for approximately an hour and forty minutes. Ultimately, it was able to recover connectivity to its service by readvertising its affected prefix via an alternate service provider.
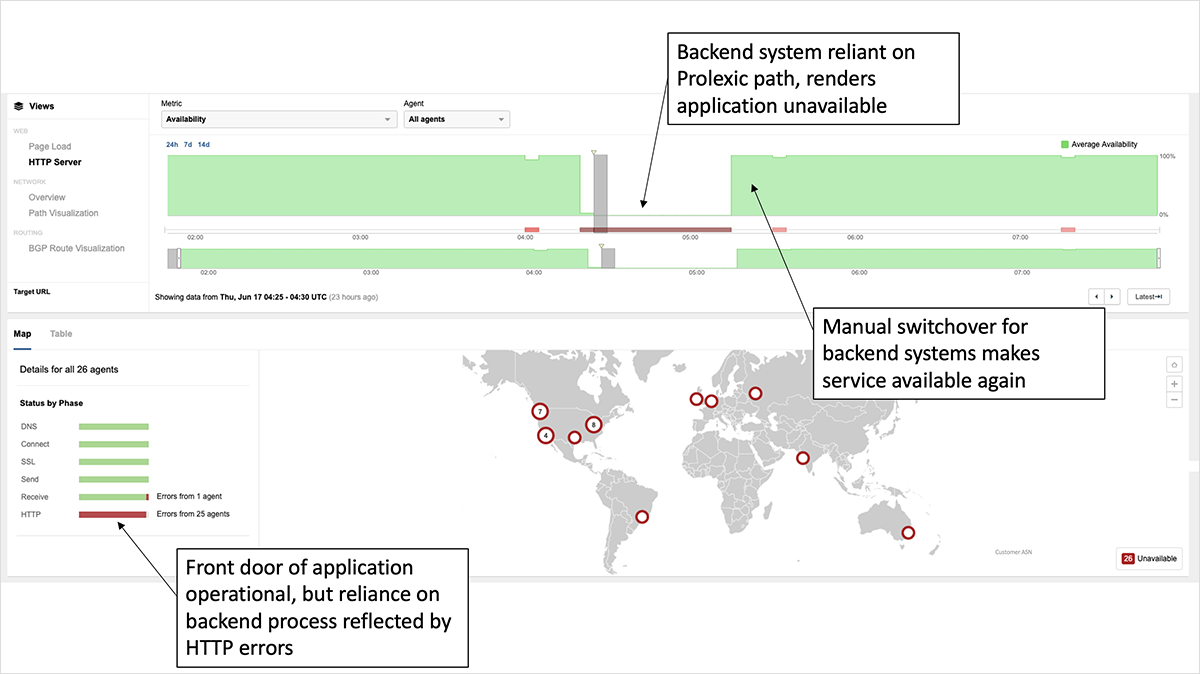
Not every impacted customer lost connectivity to its service front door. The organization shown in figure 5 uses Akamai’s CDN service, which was reachable throughout the Prolexic outage. However, requests for the site were returning 503 errors starting at 4:20 UTC, as a backend system critical to loading the page was unavailable, as it was sitting behind the Prolexic service. Most sites today have many backend and even third-party dependencies that are not visible via the front door, so the broader impact of outage likely went beyond its direct customers. Any lack of visibility into all associated dependencies potentially meant that some organizations were not immediately aware they were impacted and, as a result, took longer to both identify and fix the issue.
Lessons and Takeaways
Organizations that were able to react the quickest to the outage (whether via automation or manual intervention) were those that had backup plans in place before the outage. Outages are inevitable. Even the most sophisticated companies, such as Google and Amazon, experience outage events that can have significant impacts on their customers and global Internet users. In the case of the Prolexic outage, quick action by Akamai enabled most customers to recover within minutes.
Ultimately, as a customer of any critical service, you need to have a backup plan for when outages do happen, as they will, and this incident was yet another reminder of the need to implement best practice operations that involve redundant services, a clear plan or automated process to switch to backup when needed, and the visibility and insight to trigger or inform you when a switchover is needed — including visibility into early warning indicators. Hence, you know if and when to activate backup procedures.
Other mitigation efforts include diversifying delivery services for web content, i.e. adding redundancy, and making sure to understand all of the third-party dependencies that can impact customers’ web and app experience. Today’s applications and services are built on a multitude of best-in-breed functionality that runs on different systems and processes to execute transactions and requests. To make sure customer experience is never compromised, it’s critical to see and understand all of the components and dependencies that have the power to take down your service.
In an effort to cater for any conceivable scenario or failure in your delivery system, you could theoretically look to design a multi-nested redundancy system, with backup systems themselves having backup systems. While backing up the backupers is certainly a valid approach in some cases, but in others, the extra expenditure might not have justified the ultimate cost of downtime. If we take Occam’s razor approach, the best practice is likely automated redundancy rather than to pay for two services to run in parallel or to have a second DDoS mitigation service paid for just to sit on standby. Fundamental to any diversification approach is visibility. You need visibility to make informed decisions so that by continuously evaluating the availability and performance of your service delivery, you can ensure that you have proactive awareness of potential issues that will enable you to respond and resolve quickly and plan accordingly for the future.
To learn more about weathering outages, check out our eBook, “Outage Survival Guide.” To stay up-to-date on the latest Internet outage intelligence, be sure to subscribe to our podcast, The Internet Report.





