[Dec 15, 12:00 pm PT]
Both today’s incident and last week’s outages involved the AWS network, where traffic loss was preventing reachability of services. In the case of the December 7th outage, the traffic loss caused by congestion was occurring between the border of AWS’ main network and their internal management network. Today’s incident, however, occurred within their main network, where traffic from sources both inside and outside AWS was getting dropped.
Historically, many incidents with wide impact on the network involve significant impairment of the control plane, preventing network devices from routing traffic correctly or at all. However, in these incidents, that does not appear to be the case, as destinations were still reachable from a routing standpoint, with some traffic successfully reaching the intended destinations.
In the first incident, AWS devices performing critical functions involving traffic forwarding and network address translation (NAT) were overwhelmed. In today’s incident, a large increase in traffic loss similarly suggests that some network functions in the data path, such as routing or NAT, were not able to operate at normal capacity (for an, as yet, unknown reason), preventing full reachability of apps and services.
[Dec 15, 9:35 am PT]
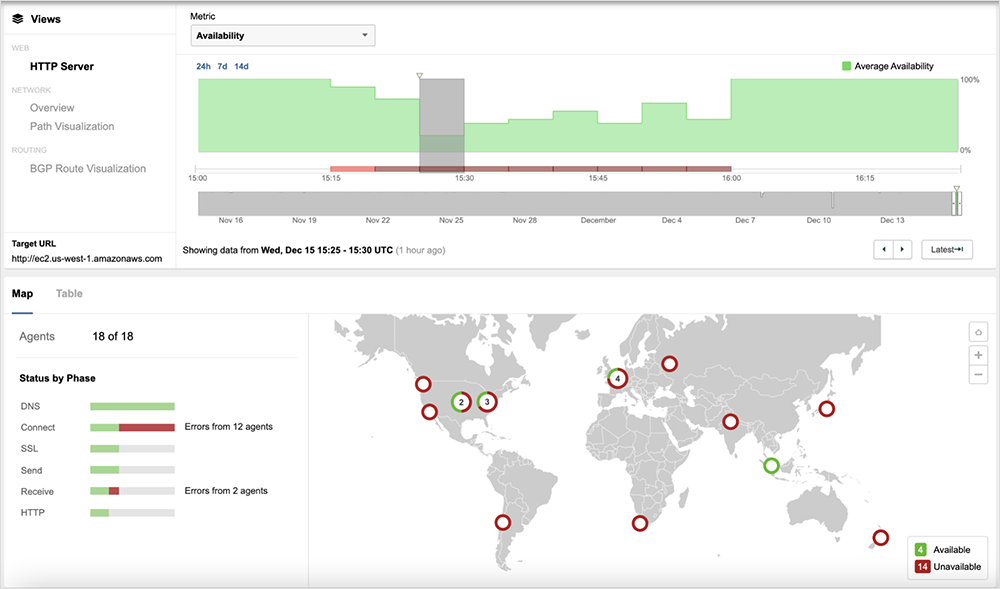
ThousandEyes can further confirm that us-west-2 was also impacted by the reported network issues with many users experiencing packet loss connecting to us-west-2.
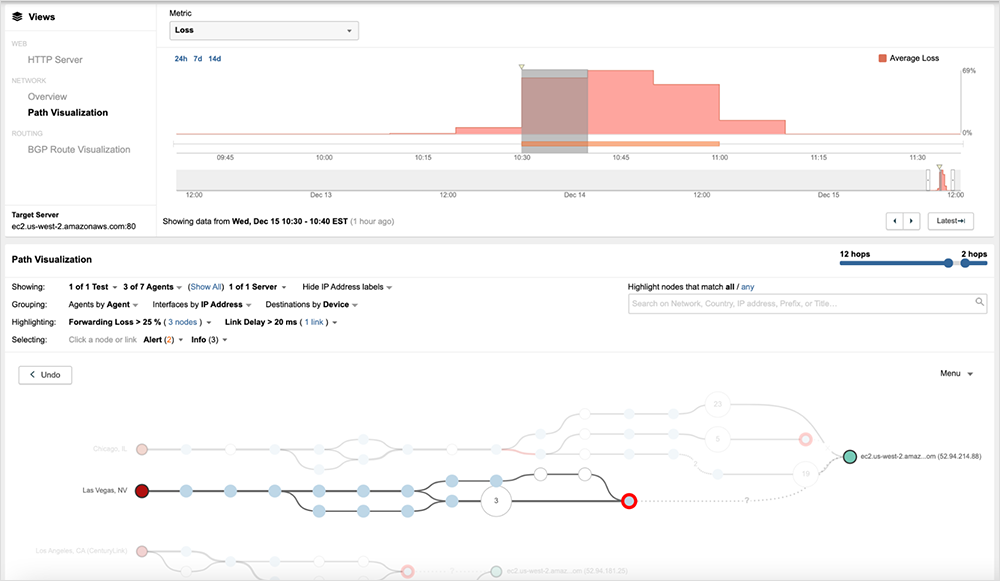
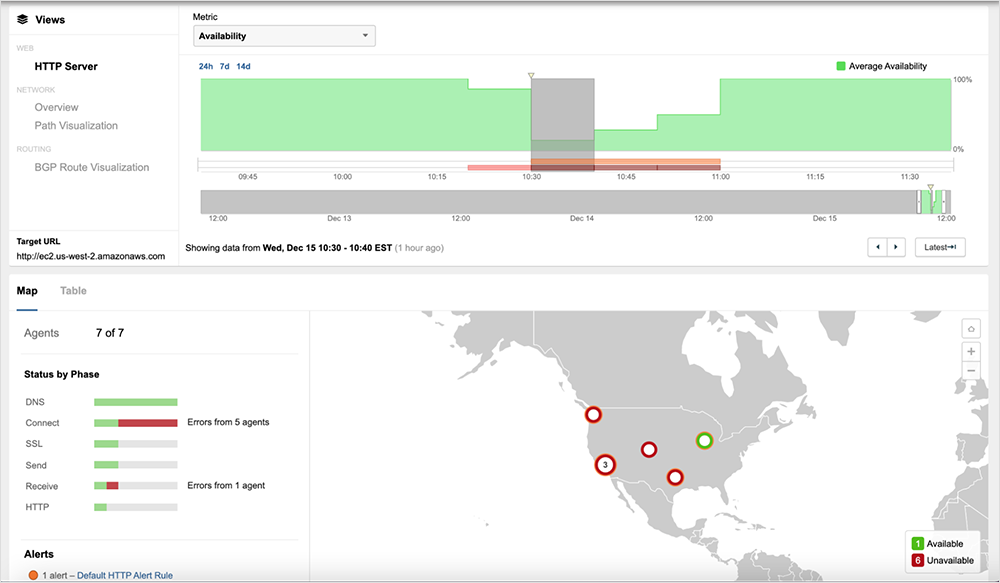
[Dec 15, 9:15 am PT]
ThousandEyes observed packet loss within AWS’ network during the incident, and Amazon has confirmed that network connectivity issues were responsible for the disruption.
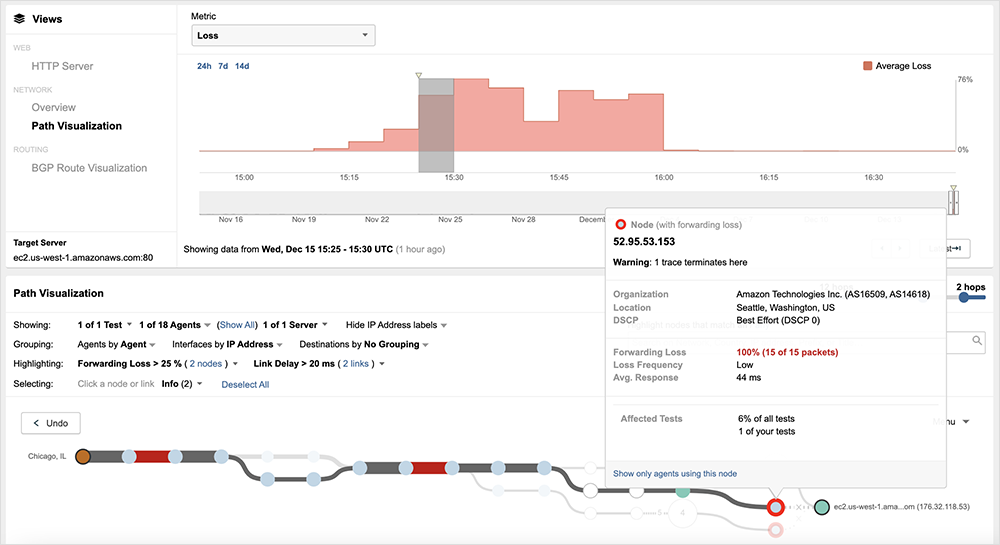
[Dec 15, 8:45 am PT]
An AWS incident impacting us-west-1 that started at approximately ~7:15am PT affected the reachability of multiple applications like Okta, Workday and Slack. AWS is reporting the issue is now being remediated.
Live link to view the AWS outage in ThousandEyes here. No login required.