ThousandEyes actively monitors the reachability and performance of thousands of services and networks across the global Internet, which we use to analyze outages and other incidents. The following analysis of Comcast’s service disruption on March 5, 2024, is based on our extensive monitoring, as well as ThousandEyes’ global outage detection service, Internet Insights.
Outage Analysis
On March 5th at approximately 19:45 UTC (11:45 AM PST), ThousandEyes detected an outage in Comcast's network backbone that impacted the ability of some of its customers to reach a range of services, including Webex by Cisco, Salesforce, and AWS. Although the outage appeared to impact a small portion of Comcast’s backbone, no remediative traffic rerouting was observed. Traffic continued to flow to the impacted infrastructure throughout the incident, leading to sustained access issues until the outage was resolved at approximately 21:40 UTC (1:40 PM PST).
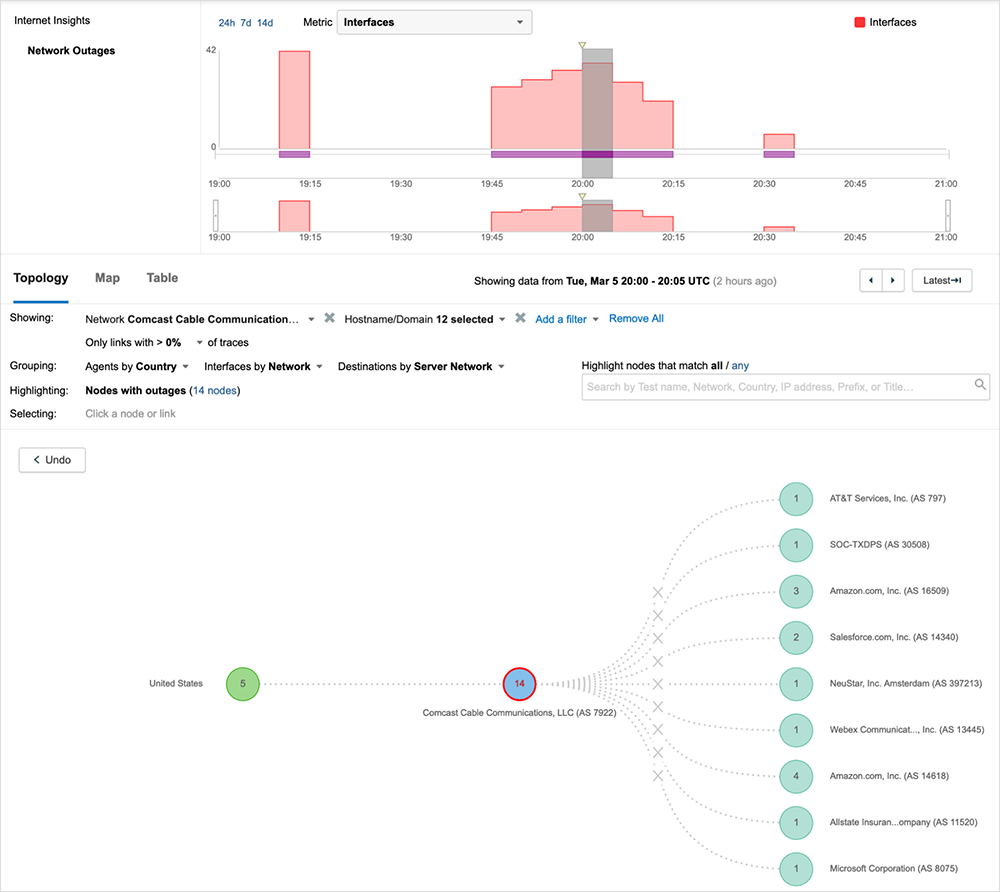
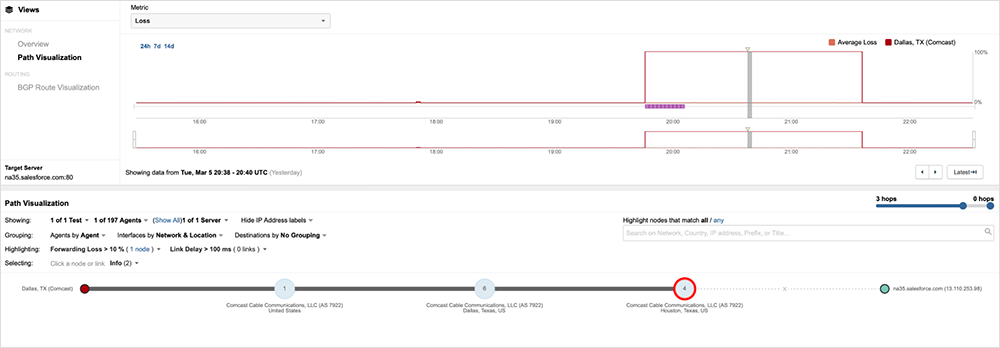
ThousandEyes’ outage detection service, Internet Insights, identified the incident in near real time, capturing its onset, duration, and resolution, as seen in figure 1 below.
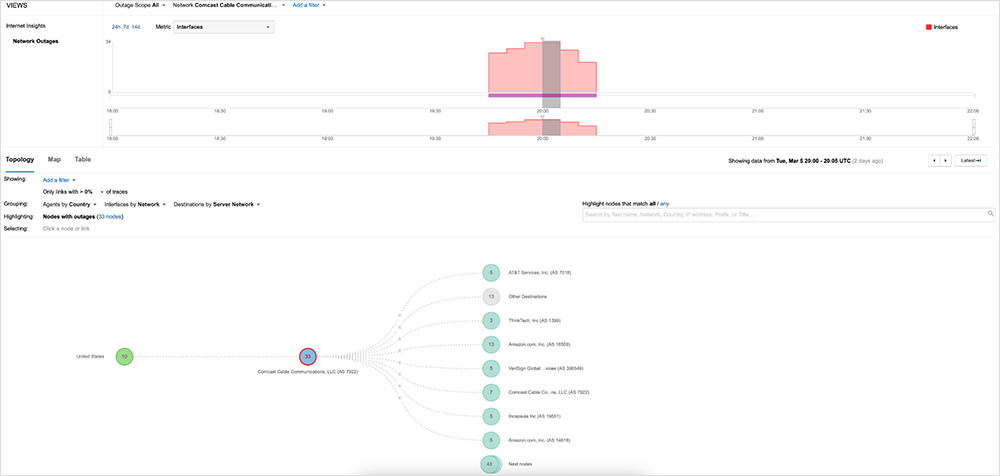
Because Internet Insights leverages billions of daily measurements from hundreds of thousands of global vantage points, it was able to provide a view of this outage from many angles, including the spectrum of services and users impacted by it. The following analysis is based on that view, as well as many ThousandEyes service tests.
Houston, We Have a Problem
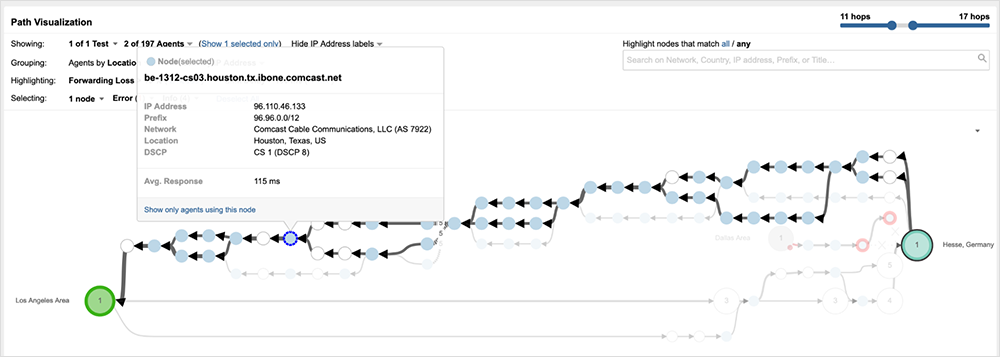
At around 19:46 UTC (11:46 AM PST), ThousandEyes observed traffic terminating around the Houston, Texas, portion of Comcast’s backbone network. The onset was sudden. Traffic traversing the affected infrastructure saw an immediate drop off—100% packet loss—with no apparent ramp-up that might indicate congestion or other stress conditions in the network. Figure 2 shows traffic originating in Dallas, Texas, destined to Salesforce getting dropped in Houston.

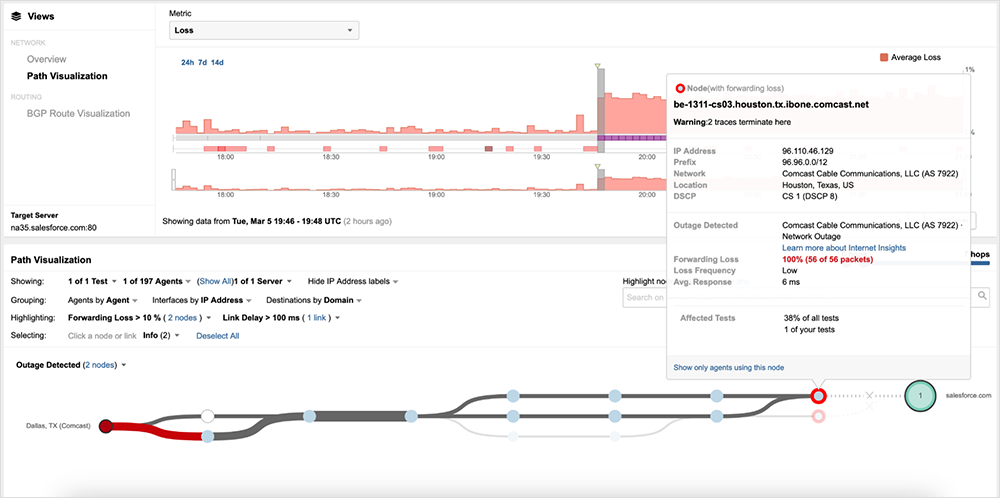
Minutes before the outage began, at 19:44 UTC (11:44 AM PST), connectivity to Salesforce was functioning as anticipated, with traffic successfully routing through the Houston, Washington D.C., and Virginia portions of Comcast’s network, before handing off to Salesforce’s NA35 data center located in Virginia (see figure 3).

As a key interconnection point between the US East and West Coast regions, some Comcast users attempting to reach services on either side of Houston may have experienced service disruptions. In particular, users in California and parts of Texas would have seen an impact. For example, figure 4 shows traffic from San Jose, California, dropping at a core router (CR) in Houston and returning an error message, indicating the network is unreachable.
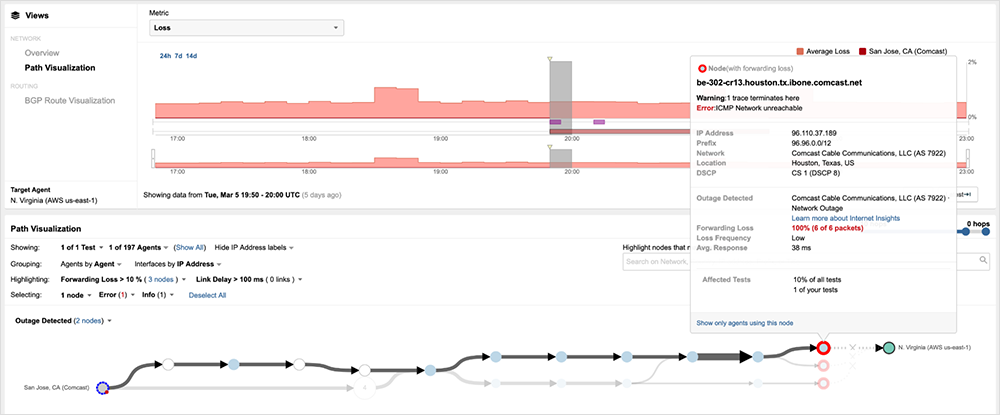
Within Comcast’s network, core routers (CRs) effectively serve as the gate into and out of each regional point of presence (PoP). All traffic routed to the PoP, even traffic that is not locally destined, must traverse the region’s core spine routers in order to get routed on to the next region in the path to its destination. (For a brief primer on Comcast’s network design, read our coverage of the Comcast outage in November 2021.)
While some impacted traffic was dropping on the edge of the Houston network (see figure 5), other traffic was successfully routed to the core spine routers before getting dropped.
Figure 6 below shows traffic between Los Angeles and AWS’ Frankfurt data center successfully traversing Comcast’s Houston network—even leveraging the same routers that appeared to be dropping impacted traffic.
However, for the routes impacted, no shift of traffic to healthy alternate routes was observed during the entirety of the incident. Figure 7 shows the midpoint of the outage, with traffic paths at that time continuing to terminate at the same point in the network.
A network of Comcast’s size would have planned redundancy measures, where traffic will automatically fail over to available alternate paths in the case of issues impacting a portion of the network. Whatever the underlying event that triggered the incident—whether a fiber cut, line card failure, or configuration gone wrong, the Houston PoP was clearly not wholly incapacitated and was still able to successfully route traffic. Even if capacity issues would have made that untenable, Comcast maintains other paths between the US East and West regions that could have been used to route around the Houston portion of the network. Why that failed to happen in this case is unclear. Regardless, the disruption was relatively short-lived, lasting a total of one hour and 48 minutes. First observed at around 19:45 UTC (11:45 AM PST), it appeared to be cleared by around 21:40 UTC (1:40 PM PST).
Initial Outage Misattribution and the Importance of (Good) Data
As one of the largest ISPs in the United States, any significant service issue would typically lead to broad user impact. While end users were affected by this outage, there are several aspects of it that prevented broader disruption (and awareness) of it.
Because the outage was localized to only a portion of Comcast’s backbone in Texas, most Comcast customers would have maintained overall Internet connectivity and would have been able to reach many sites—particularly ones popular with consumers. Most even moderately trafficked applications and sites are served by CDNs that are local to users (at least within urban and suburban areas), so most consumer traffic doesn’t need to traverse Comcast’s inter-region backbone. Even if content ultimately needs to be fetched from an origin host not in the region, CDN providers maintain connectivity with multiple Internet and transit providers, ensuring resilience in the event any one provider is unable to route traffic.
Only certain services that required traversal across Comcast’s backbone would have been impacted, which is why most of the applications suspected to be down included those that map users to a particular service instance. As a result, many Internet users began to report issues reaching specific applications, leading to the initial conclusion that multiple services were experiencing simultaneous outages.
The collaboration service Webex is one example of an application mistakenly assumed to be down early in the Comcast outage. This may be due to how this application is architected, where sessions are initiated by connecting users to a particular service point associated with their account or corporate tenant. Similarly, Salesforce users ultimately connect to a specific data center where their instance is hosted.
AWS was also called out as a potential culprit given that it provides services to many of the impacted applications, including the ones noted above. Figure 8 shows traffic between San Jose, Los Angeles, and Dallas and AWS’ eu-central-1 data center located in Frankfurt, Germany, getting disrupted by the Comcast outage in Houston.
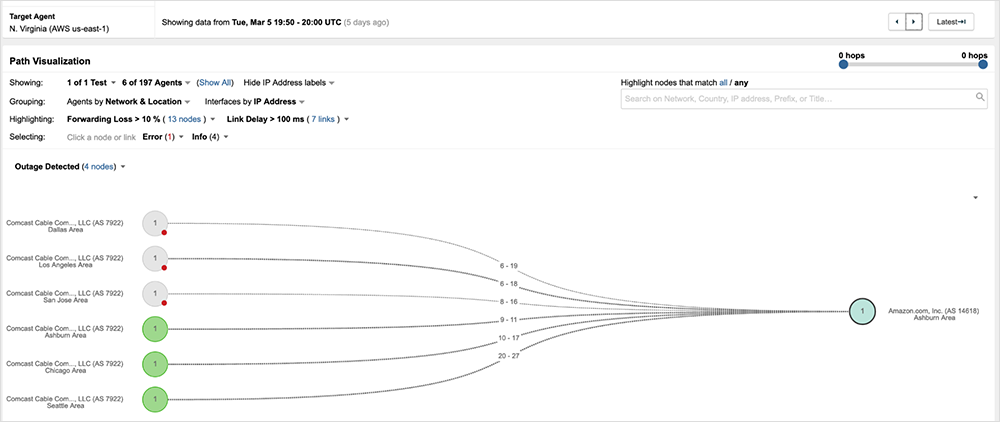
AWS even went so far as to issue a statement denying any issue with its network or services. Instead, it identified an external network provider as the source of the service disruptions.
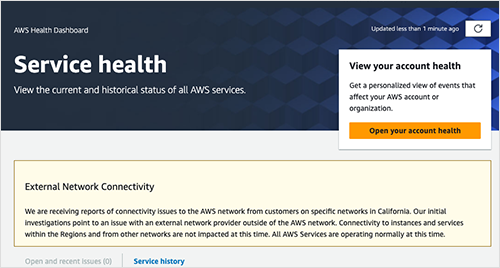
Given the above, it’s important to highlight that since the outage mostly impacted users connecting to an application not locally hosted or fronted by a CDN, a simple mechanism to restore service reachability would simply have been to connect to the local enterprise VPN or Secure Services Edge (SSE). Since these services will be connected to multiple ISP and transit providers, users could have effectively routed themselves around issues, avoiding Comcast’s backbone network entirely. Knowing they had the power to instantly restore access to disrupted apps and services, would have required users or their IT helpdesk to understand the true source of the outage.
Lessons and Takeaways
When user connectivity or critical applications are disrupted, it’s key to quickly determine whether the problem lies with you, an application, or a third-party provider. This information is essential for effective operations. By correctly attributing responsibility, you can implement appropriate plans, processes, and mitigations to minimize the impact on your users.
In cases where multiple services are affected, it can be particularly difficult to assign responsibility and determine the fault domain properly. If you reach the wrong conclusion, you may end up taking the wrong actions, which can further disrupt your users, which is why it’s crucial to rely on accurate data (versus rumor or social sentiment alone). In the case of this particular outage, accurately isolating the issue to Comcast’s network backbone would have enabled IT teams to advise users on remediative steps (such as connecting to a VPN) to restore service access.
To learn how you can gain independent visibility across your entire service delivery chain, sign up for a free trial of ThousandEyes.
[Mar 5, 2024, 3:00 PM PT]
At approximately 19:45 UTC (11:45 AM PST) on March 5th, ThousandEyes began observing outage conditions in parts of Comcast’s network, which impacted the reachability of many applications and services, including Webex, Salesforce, and AWS. The outage appears to have impacted traffic as it traversed Comcast’s network backbone in Texas, including traffic that originated in regions such as California and Colorado. As of 21:40 UTC (1:40 PM PST), the incident is resolved.
Explore an interactive view of the outage in the ThousandEyes platform (no login required).