At approximately 9:50 UTC (5:50 AM ET) on June 8, 2021, Fastly—a global Content Delivery Network (CDN) provider—suffered a major outage that impacted the sites and applications of its many customers. The outage lasted for about an hour, during which time users attempting to reach impacted sites would have received 501 service unavailable errors, or experienced issues loading content. Although the outage did not fully resolve until approximately 10:50 UTC (6:50 AM ET), some of Fastly’s customers were able to minimize the impact to their services by leveraging alternative providers to deliver content.
Fastly subsequently issued a statement identifying a latent software bug introduced in a May 12th software update as the root cause. The bug was triggered by a customer updating their CDN configuration — a routine occurrence for CDN customers. While Fastly has not identified the configuration that triggered the outage (as of June 10, 2021), the impact—85% of their service, according to Fastly—was felt globally.
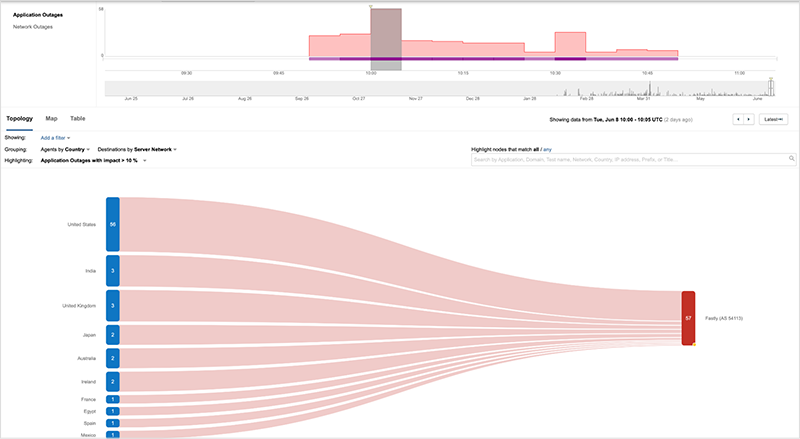
Read on to learn more about how this outage unfolded and how four different services experienced the outage very differently, or, if you prefer a podcast experience of this same analysis, tune in to this week's episode of the Internet Report, Ep. 40: Fastly's Outage and Why CDN Redundancy Matters.
Critical Role of CDNs in Modern Web Delivery
CDNs are distributed infrastructures that cache and serve content on behalf of their customers, in order to accelerate delivery to users. They play a key role in enabling increasingly large amounts of content to be consumed over the Internet because they improve web performance and reduce Internet backbone utilization. Without distributed, local delivery, the massive popularity of streaming media services and complex applications would likely not have taken place because most users would have had a poor digital experience.
While primarily used to improve user experience, CDNs reduce traffic load on their customers’ application infrastructure, which may reduce the amount of resources required where the application is hosted (also referred to as the “origin”). They can also play a vital security role by fronting the origin, thereby obscuring its location from malicious actors. In fact, most CDNs today offer advanced security functionality, either as part of a standard offering or as an add-on service. Many CDNs can block commonplace malicious traffic, as well as thwart sophisticated, large scale DDoS attacks.
Fundamentally, however, CDNs perform two functions:
-
- They deliver static/cache content from their edge nodes to end users, and
- They fetch dynamic/non-cache content from site origin to deliver at their edge.
A single webpage may be composed of dozens or even hundreds or more web objects — some configured to be stored by a CDN’s caching servers, and others configured to be refreshed from the origin frequently or even with each user request. Adding to this complexity is that the components making up a web page or application may be sourced from different locations and services, including multiple CDNs.
Many popular sites leverage more than one CDN provider to deliver content to users, primarily for redundancy but also for optimizing performance. For example, user requests could be load balanced across multiple CDNs using DNS query responses. Alternatively, the root object for a site could point to an index.html file served by one particular CDN provider, but subsequent site components could be served by different CDN(s) or other sources.
How a site or application owner chooses to architect its content delivery can determine the severity of impact of an outage like the one Fastly experienced. We can see real world examples of this by examining the availability of four sites that leverage Fastly’s services—Reddit, NYTimes, Amazon, and eBay. The same outage led to different outcomes for these customers.
One Outage, Many Outcomes
When the Fastly outage began at roughly 9:50 UTC, there was a dramatic, global drop in the availability of its service—but not all of the content it delivered went offline. Some of Fastly’s customers had resilient delivery architectures or they were able to take action to mitigate the impact of the incident—leading to very different outcomes for their users.
The content providers, NYTimes and Reddit, are two examples of customers using Fastly’s service as the sole CDN for their primary site domains, but while Reddit was impacted throughout the outage, the NYTimes was not.
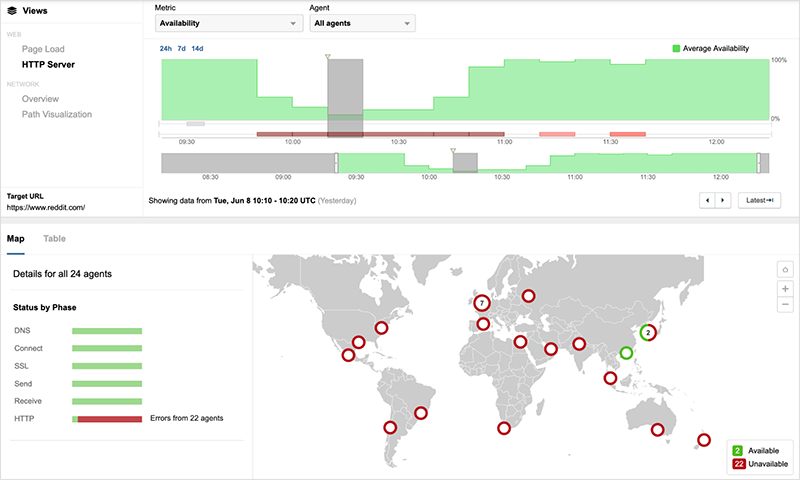
Beginning at 9:50 UTC, vantage points around the globe connecting to www.reddit.com were unable to access the site, instead receiving 503 service unavailable errors until Fastly’s service was restored nearly an hour later.
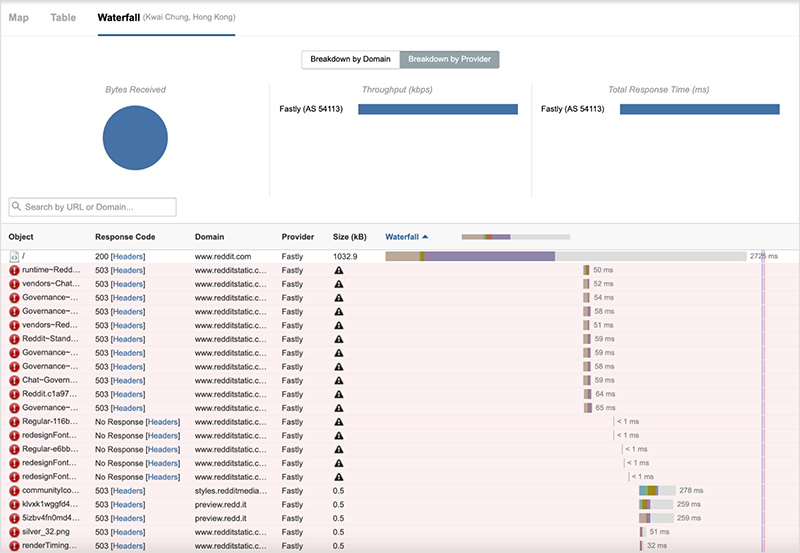
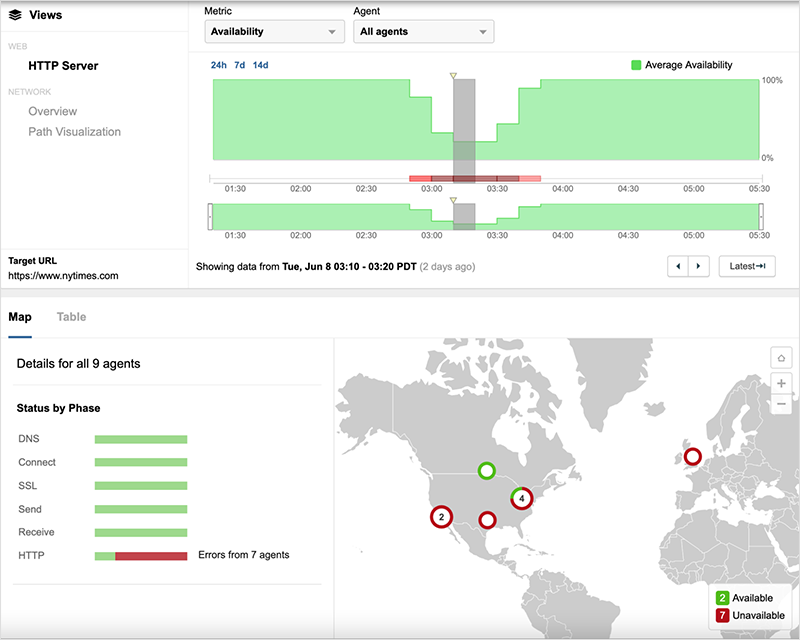
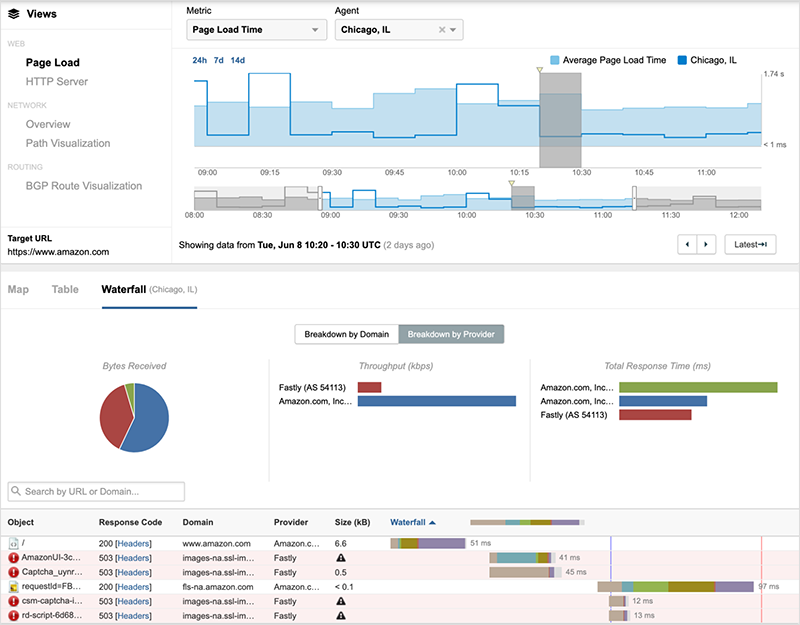
While figure 3 appears to show some availability throughout the outage, a waterfall view of site components loading for the page shows that even when the root object of the page was successfully received, subsequent components were unavailable and the site could not be loaded.
The NYTimes (www.nytimes.com) in contrast was able to reduce the downtime of its service for most users (despite not having CDN redundancy) by temporarily redirecting users to the site’s origin servers hosted in Google Cloud Platform (GCP).
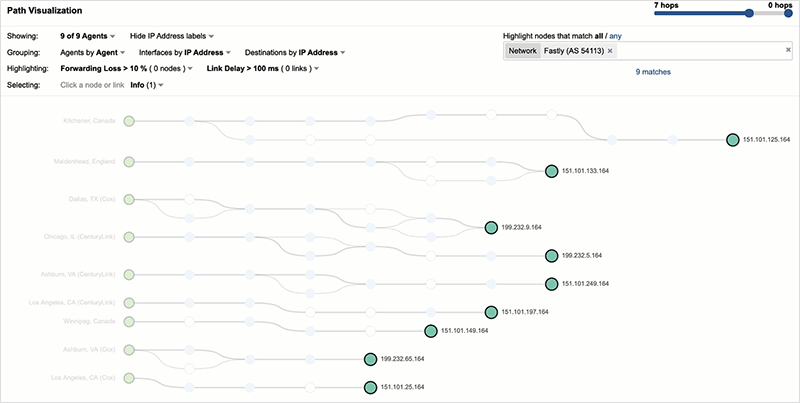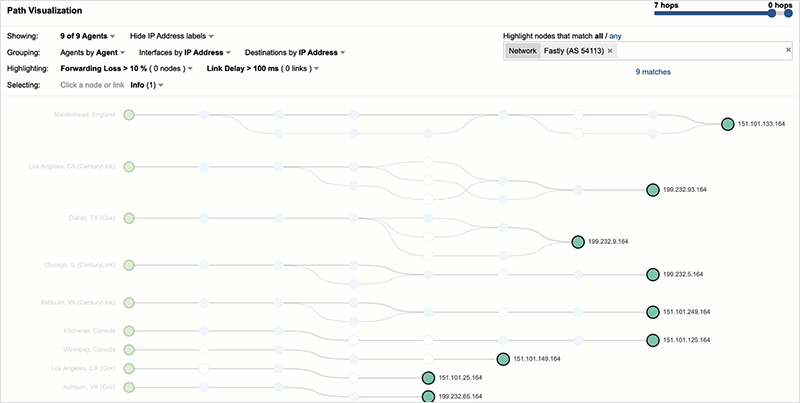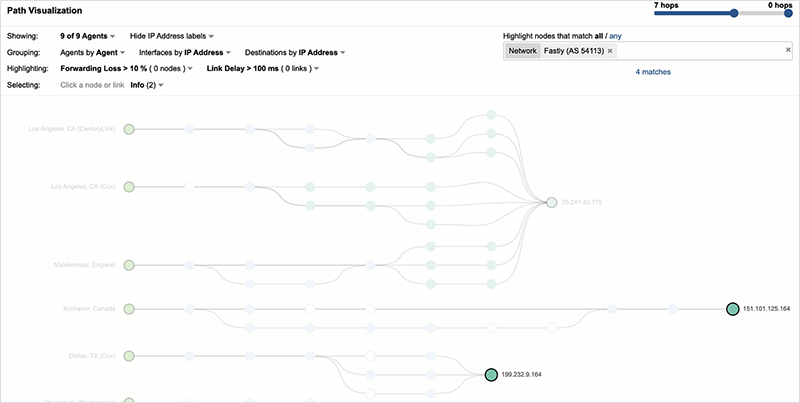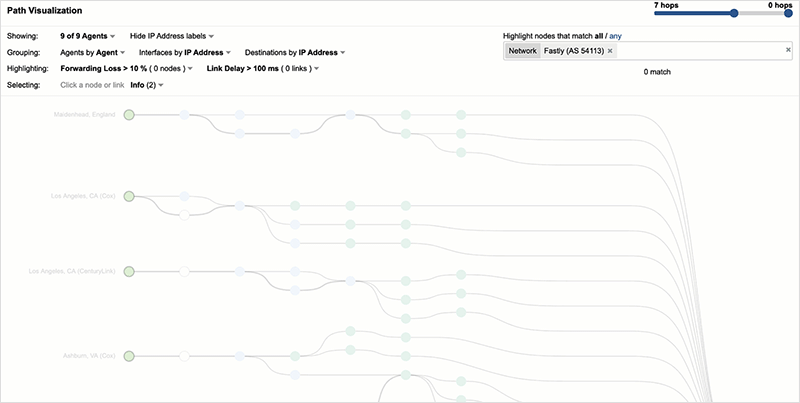
At the start of the outage, as shown in figure 5, traffic destined to the NYTimes site connects to Fastly’s servers.
The NYTimes site was impacted similarly to Reddit initially, with site requests all returning service unavailable errors.
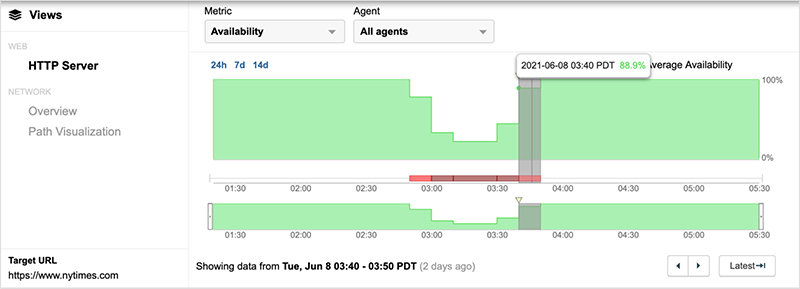
However, at approximately 10:30 UTC (40 minutes into the outage), availability of the service significantly increased—well before Fastly implemented a fix to its service.
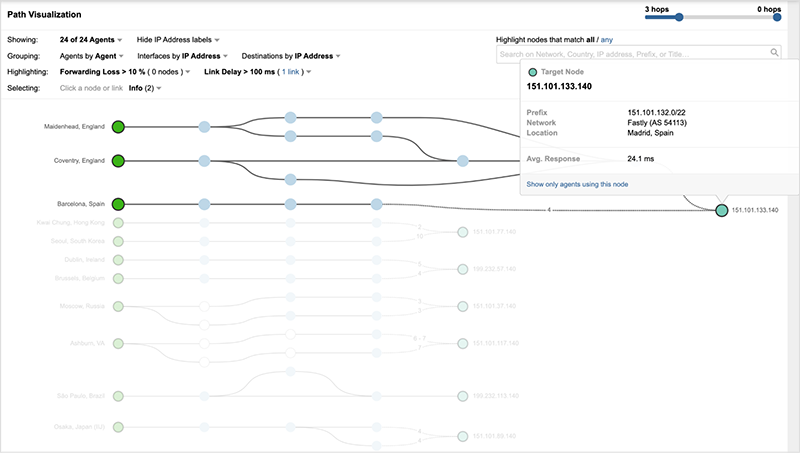
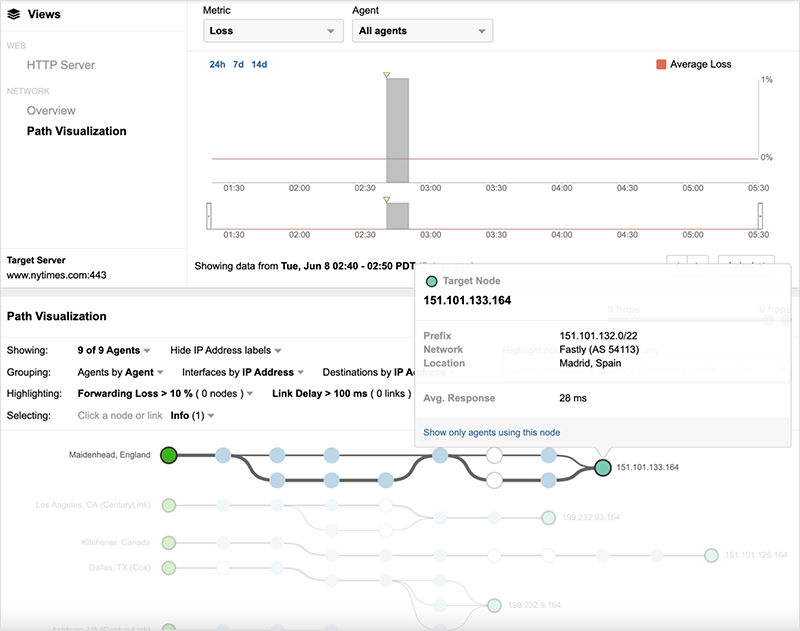
By looking closely at the network path (and destination IP addresses), the cause of the availability increase becomes clear. The same users who are successfully requesting the site are connecting to servers hosted in GCP, rather than Fastly servers. Within the next 10 minutes, nearly all NYTimes users are redirected away from Fastly, and by 10:50 UTC no Fastly servers are in the delivery path. Figure 8 below shows the initial introduction of GCP servers and the progressive redirection over a period of 20 minutes (10:30-10:50 UTC).
By the time of Fastly’s rollout of a fix to its service (just before 10:50 UTC), all NYTimes users are connecting to GCP (see figure 9). Once it became clear that the Fastly service fix was successful, NYTimes users were redirected back to Fastly servers (at approximately 11:30 UTC), returning the site to its pre-outage state.
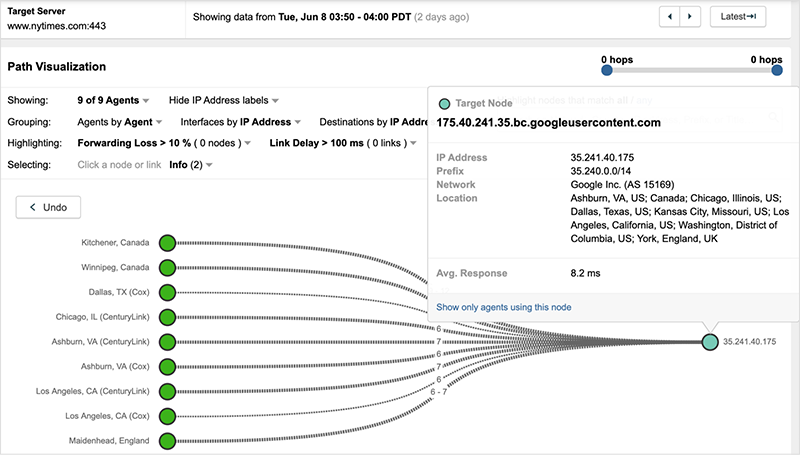
The reason why the remediation steps the NYTimes took had a delayed impact for some users has to do with how the redirection was achieved. To change the server destination for its users, the DNS records for the NYTimes site would need to be updated to remove Fastly (either its IP addresses or CNAME). DNS records are typically cached (either locally, within a client’s resolver, or at a public resolver, such as Google’s 8.8.8.8 service). It may have taken some time for the updated DNS records to both propagate across their nameservers and, depending on the time to live (TTL) value of these records, expire from DNS server caches, which would trigger requests for records with the updated destinations that excluded Fastly.
Despite not having a redundant CDN architecture, the NYTimes site operators were able to lessen some of the impact of the outage on its visitors by implementing a manual update about 40 minutes after its site went offline. While a manual update certainly helped, let's take a look at how sites belonging to Amazon and eBay were able to maintain significantly higher levels of availability by leveraging redundant delivery architectures.
Amazon, the global e-commerce giant uses not one but three CDNs to deliver its site, continuously load balancing traffic across each to deliver the best possible experience to visitors. Amazon has its own CDN service (Cloudfront) that’s part of its AWS offerings, which include DNS, compute, network, and platform services. But rather than rely solely on its own services, Amazon leverages a diverse set of providers (including DNS and CDN services) when it comes to delivering its valuable web properties to users. Besides its Cloudfront CDN, Amazon leverages Akamai and Fastly to host its site. Amazon leverages its DNS service (Route 53) to load balance across each of these providers for its www.amazon.com domain. Even users connecting from the same locations may be directed to different CDN providers within a short period of time. For example, the vantage point below targeting Amazon’s site is directed to a Fastly server just after 8:00 UTC, then is directed to an Akamai server a few minutes later, and less than ten minutes later is switched over to an Amazon server. This active allocation of users across multiple CDN services is part of normal operations for Amazon.
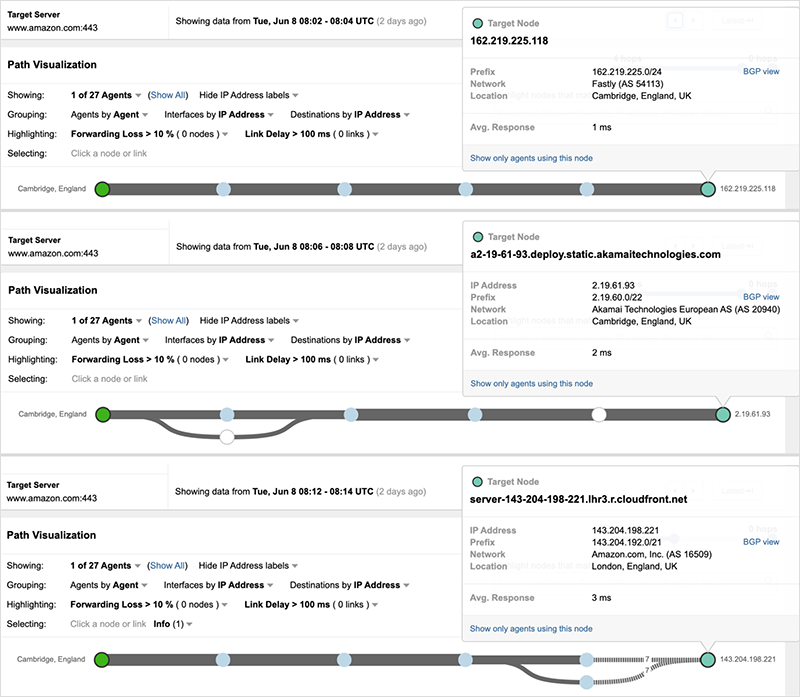
As the Fastly outage unfolded, some Amazon users were intermittently impacted, as Fastly initially continued to remain part of its service delivery (see figure 11).
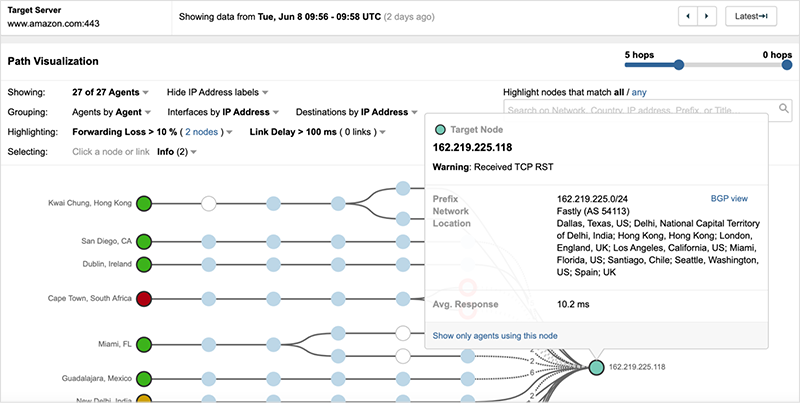
However, at approximately 10:16 UTC, Fastly was no longer in the direct delivery path. Similarly to the NYTimes site, this remediation would have been achieved by no longer inserting Fastly into its DNS responses.
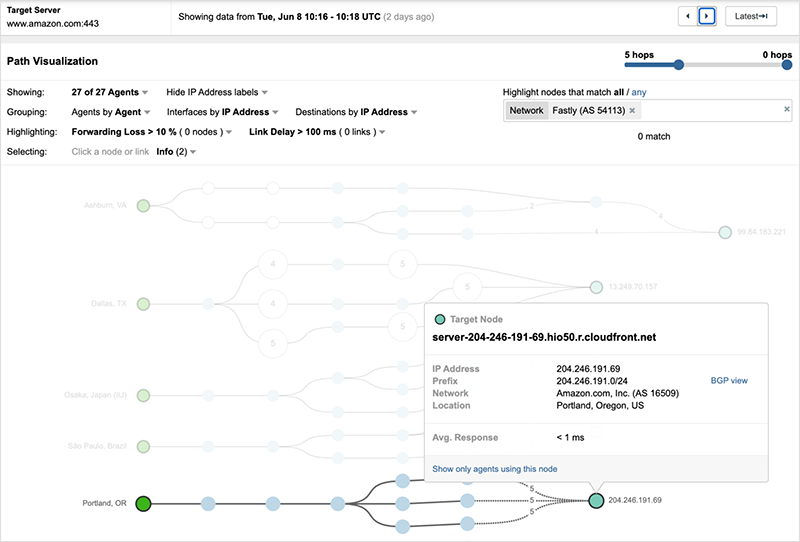
But removing Fastly as an initial edge server did not fully resolve issues for Amazon users, as Amazon also load balances its site components across multiple CDN providers, including Fastly. As seen below in figure 13, even after 10:16 UTC, page load issues remained for users directed to Fastly for web objects critical to load the site.
Amazon eventually steered users to site components hosted by its own CDN and others, such as Akamai and EdgeCast. By approximately 10:40 UTC, site loading issues would have been resolved for most Amazon users.
eBay experienced a similar issue with site component delivery impacted by Fastly, even though its site is initially served by Akamai.
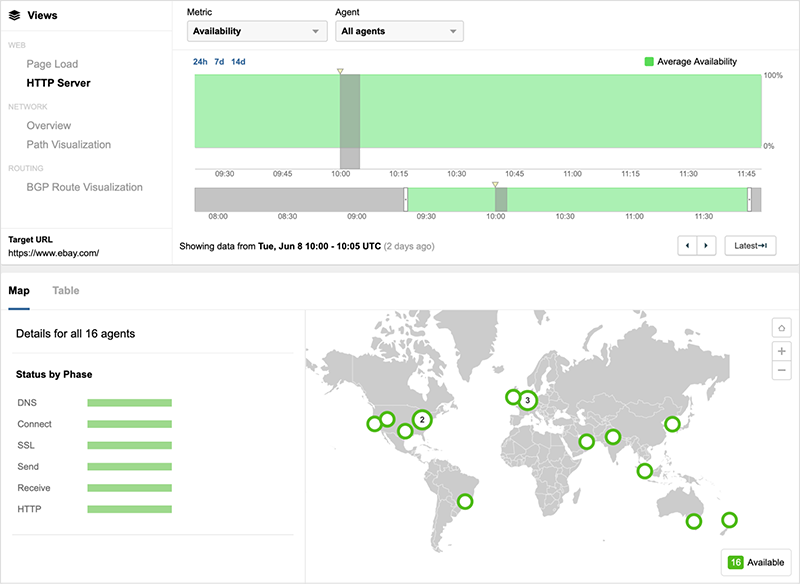
Looking strictly at edge server availability, it appears that eBay was not impacted by the outage; however, in looking at the waterfall view of site components loading for some users, we can see that only the root object (delivered by Akamai) is successful, and subsequently content hosted by Fastly is preventing successful page load.
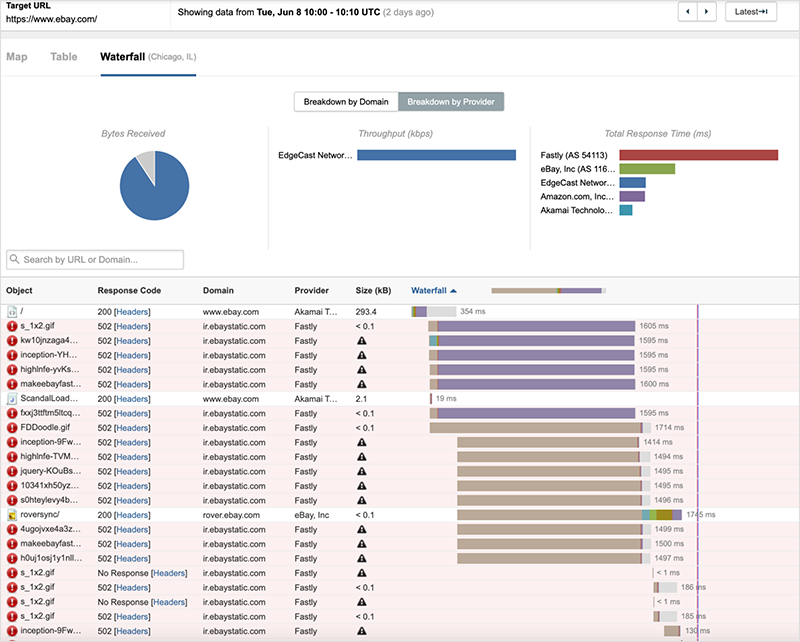
eBay appeared to have resolved this issue for most users by approximately 10:40 UTC by leveraging Akamai and other services.
Lessons and Takeaways
While the Fastly outage was broad and significant, not every site using Fastly experienced severe effects from it. Its customers leveraging multiple CDNs were only partially impacted and eventually were able to fall back on other providers. Customers using Fastly as their sole CDN, were taken offline completely, and although we know some customers were able to redirect users to their origin servers, the manual process meant further delay in getting their users able to access their sites.
CDNs are critical infrastructures for delivering web content, and ensuring that your sites and applications are continuously up and running (and performing at optimal levels) requires careful consideration of how they factor into your digital delivery.
This outage was an important reminder on the need for redundancy for every critical site dependency. Here are some takeaways from this outage and its customer impact:
- Diversify your delivery services—just as redundant DNS is best practice, two or more CDNs should be considered to ensure optimal delivery and to reduce the impact of any one CDN experiencing a disruption in service.
- Have a backup plan for when outages (inevitably) happen—and be sure you have visibility into early warning indicators of issues, so you know when you may need to activate your backup procedures.
- Understand all of your dependencies—even indirect, “hidden” ones. For example, if you rely on external services for site or app components, be sure to understand their dependencies, such as DNS, hosting, etc. so you can ensure they are also resilient.
Continuously evaluating the availability and performance of your site delivery will ensure you have proactive awareness of potential issues and enable you to respond quickly to resolve them.
To learn more about weathering outages, check out our eBook, “Outage Survival Guide.” To stay up-to-date on the latest Internet outage intelligence, be sure to subscribe to our podcast, The Internet Report.




