This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for firsthand commentary.



Internet Outages & Trends
Having a complete understanding of the situation and associated service delivery chain is crucial for effective incident response, as any missing information can lead to misdiagnosing the problem.
To assure quality digital experiences, one strategy, of course, is to use system logs, context, and triangulation to try to de-risk the “unknowns” that can degrade or take out your networks, applications, or services.
In the past fortnight, engineering and ops teams at OpenAI and PlayHQ seem to have encountered some of these unknowns.
OpenAI appeared to live-test an unknown by manually diverting traffic from a degraded infrastructure cluster to a healthy cluster—which did not completely work as intended. PlayHQ, meanwhile, appeared to have seen an unknown issue that had been dormant since January suddenly impact application availability.
On a related note, this fortnight, Microsoft revisited Azure problems caused by cable cuts in Africa. In Microsoft’s case, their issues related to an apparent “known unknown”—what might happen in a perfect storm if all four redundancy options they had in place were out simultaneously. Given the anomalous nature of that occurring, this would have remained a “known unknown” in their operational environment for some time until the cable cuts happened. What’s interesting, though, is what they did to find extra capacity for their South African sites when they sought to mitigate capacity concerns.
Read on to learn about these and other recent incidents, or use the links below to jump to the sections that most interest you:
ChatGPT Outage
On April 10, at around 11:00 AM (PDT) / 6:00 PM (UTC), users of OpenAI’s ChatGPT reportedly started to see errors due to a problem with one of the service’s clusters. According to OpenAI, the root cause was traced to a control plane service for one of the ChatGPT clusters, which experienced memory exhaustion and consequently degraded.
To address the problem initially, OpenAI engineers manually redirected traffic away from the affected cluster to a healthy one, which required scaling up that cluster to meet the increased traffic. However, even with scaling, it appeared that the second cluster was unable to handle the number of requests to its control plane service, resulting in continued degradations.

Explore this outage further in the ThousandEyes platform (no login required).
ThousandEyes initially observed page load times for ChatGPT reducing from an average of 972 milliseconds to 299 milliseconds and a corresponding reduction in the number of page objects being loaded, suggesting page-related problems. When looking at the construct of the page load, ThousandEyes observed that the improved page load times all encountered 403 Forbidden errors, suggesting OpenAI’s backend understood the requests being made but was unable to process the request to the resource.

ThousandEyes observed a significant increase in page load times, which appeared to coincide with OpenAI redirecting traffic to a different cluster. In some cases, the normal wait time of 126 milliseconds jumped up to 3100 milliseconds, which could have caused timeouts in some cases, although these appeared to result from rate-limiting being applied to reduce inbound traffic volumes to the second cluster. This is consistent with OpenAI’s observation of “a large portion of requests to OpenAI fail[ing] with 500 & 503 error codes.”
Although page timeouts were observed, it seemed that some users would have been able to access certain parts of the service, as some parts of the pages appeared to be still loading. This indicates that during the mentioned period, some aspects of the system appeared to be responding and functioning normally, which suggests that the issue was related to the backend load rather than a complete functional failure.
The issue was ultimately mitigated by increasing the available memory on the Kubernetes control plane and rebalancing traffic.
There are a couple of lessons to take from this.
First, this wasn’t a redundancy issue. The shifting of traffic between clusters occurred manually, not automatically, when engineers were alerted to an unexpected increase in errors, which led them to make the redirection to the second cluster, and then initiate rate limiting and redistribution on their own. In my opinion, because the circumstances were different from those that would trigger a normal redundancy response, the second cluster’s ability to meet the additional traffic may have been largely untested.
On the user-facing side, this is an example of contextual signals at work. Given the intermittent nature of the issue, simply retrying may have been enough to resolve the problem for some users. Additionally, reconnecting or connecting from a different location e.g. using a VPN might have helped in communicating with the ChatGPT service from a different location, potentially connecting to a different cluster.
Outage on unpkg CDN
An outage occurred around 8:00 AM (UTC) on April 12 that affected several websites using unpkg, a free content delivery network (CDN) for npm packages that is powered by Cloudflare. The sites experienced a 520 error from Cloudflare, which is a general response that typically occurs when the origin server can't complete a request due to protocol violations, unexpected events, or empty responses. Broadly speaking, this type of error usually happens when a program, cron job, or resource is taking up more system resources than it should, causing the server to fail to respond to all requests properly.
It appears that one workaround suggested for impacted developers was moving to jsDelivr, another open-source CDN for GitHub and npm, to keep their sites running. To use this workaround, developers would need to understand their end-to-end service delivery chain, allowing them to identify where a problem lies in the various components of a system, who is responsible for fixing it, and whether alternatives or backup options exist.
Unpkg came back online around 1:00 PM (UTC) after Fly.io, the service that unpkg's origin server uses for auto-scaling infrastructure, deployed a fix to recover the affected sites.
H&R Block Outage
Last fortnight, we touched on the U.S. tax season and the special attention likely being paid to ensure systems could handle any last-minute rush of filings on Tax Day. On that final April 15 deadline day, a subset of users of H&R Block’s "desktop" thick client saw 502 errors when trying to retrieve certain information from H&R Block’s servers. A 502 error typically suggests a bad gateway, meaning that the server, acting as a gateway or proxy, received an invalid response from an inbound server while trying to fulfill the request.
H&R Block acknowledged the issue, noting the problem was “preventing some desktop software users from e-filing their returns.” However, “online clients and clients working with [H&R Block’s] tax professionals virtually or in person are not impacted,” the company said. The issues appeared to be resolved after about four hours, according to status updates H&R Block posted on X.
A news report noted a flow-on impact to some users, who had “repeat pending credit card charges for multiple filing attempts.” The same report said H&R Block “received about 2000 inquiries related to the technology outage.”
The fact that this issue appeared to be confined to thick clients may indicate a problem with the client software itself, such as an expired token or a configuration bug. The root cause is unclear; particularly on Tax Day, it’s easy to imagine there may be code freezes and other mechanisms in place to prevent eleventh-hour system issues.
Impacted users had a few alternative options available. They may have been able to switch to a browser-based version of the software, where they could re-enter all their data and then file. They could also choose to print out a copy of the tax return at home and file it at a post office, though that would mean doing so without completing a final validation against the IRS system.
Revisiting West Coast of Africa Cable Cuts
Microsoft recently released an “incident retrospective” where they provided detailed information about the recent damage to subsea cables, how that impacted Microsoft’s network capacity and services, and what measures they took to address the issue.
The report confirmed ThousandEyes’ observations and analysis of the disruption, and it also provided some additional details about the steps they took.
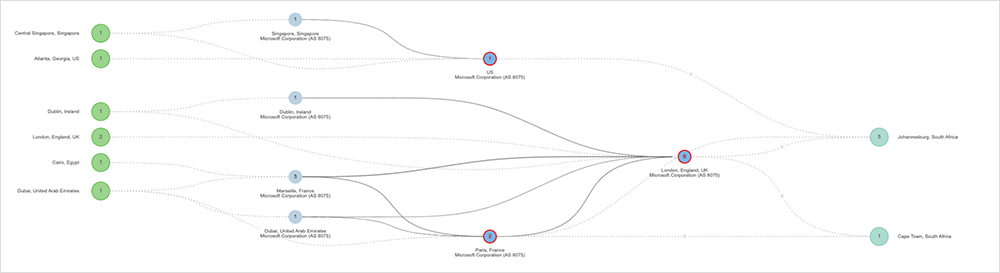
Multiple concurrent subsea cable cuts off the west coast of Africa impacted Microsoft Azure and Microsoft 365 services in the region. While many customers use local instances of their services within the South Africa regions, some services rely on API calls made to regions outside of South Africa. The reduced bandwidth to and from the South Africa regions impacted these specific API calls, resulting in service availability and/or performance issues. Customers began to experience network latency and packet drops as a result of reduced capacity.

The retrospective shows that after Microsoft's mitigation efforts and the end of the business day in Africa, network traffic volume reduced and congestion began to ease, resulting in a reduction of loss. However, Microsoft took additional action: shifting capacity from Microsoft's Edge in Lagos to increase headroom for South Africa by essentially switching the optical wavelengths off the branch, allowing the capacity to be used for other traffic.
This didn't mean that Lagos was completely isolated; it just meant that instead of accessing the Microsoft backbone directly, they used a third-party ISP as the linking capacity between Lagos and the Microsoft backbone, where that ISP interconnected with the Microsoft backbone and bypassed the cable cut. This effectively mitigated customer impact.
It was interesting to see how Microsoft distinguished the characteristics of applications and services and made capacity and redirection plans accordingly. They had robust redundancy plans in place, anticipating that multiple issues could occur. However, in this case, they experienced something of a perfect storm that impacted all four redundancy plans, with capacity cuts on both sides of the African coast, in conjunction with an optical line card failure.
Even then, they were never completely offline and were able to instigate a process and workaround to restore nearly full capacity while repairs were undertaken. They are now looking to build this scenario into future capacity and application plans.
PlayHQ Outage
On April 13, PlayHQ, an Australian sports management company that develops software for managing community sports, experienced a site-wide degradation for about four and a half hours. During the incident, one-third of the users visiting the company’s apps displayed 404 errors, while admin and registration functions were degraded.
According to a company statement, the issue occurred due to a change in mobile apps deployed in January 2024, which were not being cached correctly. The problem remained dormant until April 13 when the defect was triggered by a “perfect storm” situation caused by multiple requests/competitions that led to atypical load.
Sky Mobile Outage
Mobile virtual network operator (MVNO) Sky Mobile experienced an April 11 outage that left users unable to access the Internet or make phone calls over the cellular network. The company acknowledged the issue was affecting its 3G/4G/5G services. While some reports suggested the MVNO had carried out maintenance work the previous day, resulting in connectivity issues for a small subset of users, it appears there is no connection between the two occurrences.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (April 8-21):
-
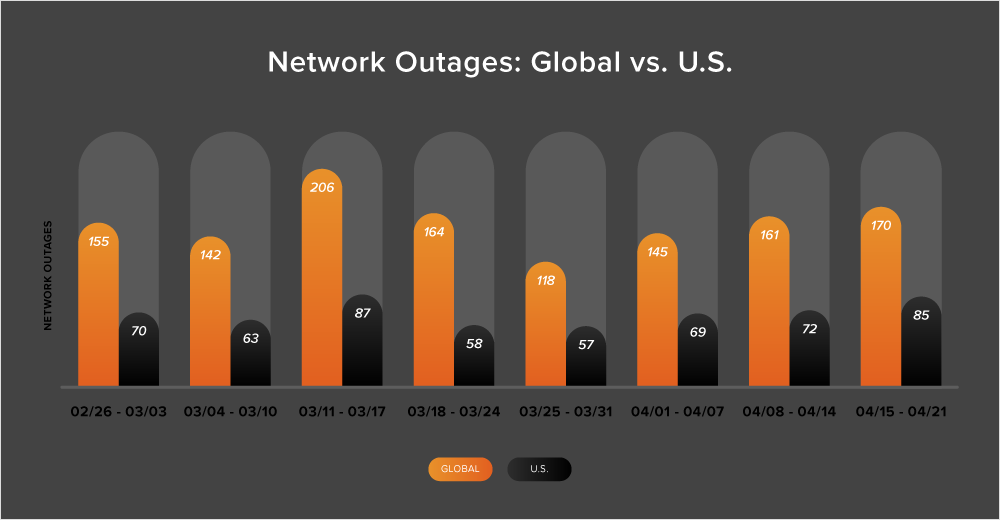
The upward trend of global outages that started in the beginning of April has continued, with the number of outages increasing steadily throughout the month. During April’s second week, outages rose 11% compared to the first week in the month, jumping from 145 outages to 161. This trend continued in the subsequent week (April 15-21), when the number of outages increased by 6%.
-
The United States also saw a rise in outages during the second and third week in April, first experiencing a 4% increase in outages (April 8-14), followed by an 18% increase the next week (April 15-21).
-
Between April 8 and 21, 47% of total network outages were observed in the United States. This continues the now longstanding trend of at least 40% of all outages being U.S. centric.