This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
Simple front-facing customer experiences that we’ve become so accustomed to today often mask considerable complexity on the backend. The service delivery chain of technologies powering the frontend often comprises a mix of on-premise assets, cloud services, containers, and APIs.
We often talk in this series about the flow-on impact that a degradation or outage at just one of these components can have. Depending on the architecture of the app and resilience of the backend, an incident in one part can be routed around in the best case scenario, or take down critical systems for hours in the worst case.
This fortnight, we saw some issues emerge due to backend changes: a data center plant upgrade that took out banking and telephony services for hours, and a backend hardware replacement that disabled interbank transfers.
Other examples of recent backend issues included a fault in Google Cloud’s private cloud connectivity and a potential issue in Microsoft’s cloud-based SQL infrastructure. These are symptomatic of a broader pattern emerging in the cloud outage space: the majority of outages occur in the service infrastructure layer, where the customer-facing impact can be sizable.
Read on to learn about these recent outages and degradations, or use the links below to jump to the sections that most interest you.
Equinix Chiller Upgrade Leads to DBS, Citibank Outages in Singapore
Major Singaporean banks DBS and Citibank, along with cellular telco redONE, experienced outages after a chiller upgrade at an Equinix facility did not go as planned.
The outages started in the afternoon of Saturday, October 14, and services did not fully recover until the following morning. The Monetary Authority of Singapore (MAS) has reportedly asked them to conduct a detailed investigation.

A composite picture of the root cause has emerged across news reports. Cooling systems at an Equinix data center were either offline or degraded due to upgrade work, leading to raised temperatures in some data halls, and a shutdown of IT equipment. Both banks reportedly activated backup sites but were unable to fully recover services.
redONE, the impacted telco, said it sent engineers to site “immediately,” but the restoration process “took longer than what was initially expected.”
From redONE’s statement, it appears possible that they did not activate their backup options as quickly as they could have due to their belief that the primary site would be recovered faster than it actually was. It’s our best guess that the banks may have faced a similar situation.
Depending on the particular situation, it may be the right call to simply wait for resolution, rather than activating backup or secondary sites—especially if the issue is expected to resolve faster than it’ll take to launch the backup. Other times, quick action to switch to a backup system is necessary. Quick identification of the issue’s cause can help companies determine whether it’s best to wait or not.
Google Cloud VMware Engine Issues
Customers of Google Cloud VMware Engine experienced nearly three hours of downtime during the October 18 business day due to the “loss of multiple VPC peer circuits” in a Sydney, Australia, data center that hosts the australia-southeast1 zones (collectively, a “region” in Google parlance).
The issues started at midday local time on the Australian east coast and were resolved at 2:58 PM local time on Google’s end, though the cloud provider noted that “some customers may have experienced residual impact beyond the resolution time” due to the outage duration.
The incident manifested to customers as “connectivity issues for stretched clusters in the affected region.” Stretched clusters are private cloud resources that operate across two of the four zones in the region. Customers also experienced disconnections of hosts in vCenter and/or a loss of connectivity between their private cloud and on-premises environments.
According to the post-incident report, services were restored after Google brought up a backup transit link that restored connectivity between stretch sites, and customer connections were migrated across.
Microsoft Exchange Experiences Disruption
On October 11, some users of Exchange Online experienced issues with “sent” emails not actually being sent. Microsoft acknowledged “an issue causing delays receiving external email messages in Exchange.” They also noted that impacted users may be served a "451 4.7.500 Server busy" error message, according to a screenshot of the incident report from the Microsoft Admin Center that one user shared on Reddit. ThousandEyes observed timeouts in its own tests; users could hit “send” on messages, and they appeared to complete as normal, only to then hang behind the scenes. At the time of writing, Microsoft is still investigating if the degradation was related to issues in part of the backend SQL infrastructure underpinning Exchange Online.
Outage Impacting Japanese Banks
An “interbank data communications system” used by a number of Japanese banks experienced a two-day outage starting the morning of October 10, the worst in 50 years of system operation. The glitch reportedly delayed between 1.4 million and 2 million outbound remittances.
The outage occurred after “relay computers” connecting the system to banks were replaced, leading to fee processing errors that the new machines could not handle. As with the Singapore banks mentioned above, a post-incident report is being prepared for Japan’s Financial Services Agency.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (October 9 - 22):
-
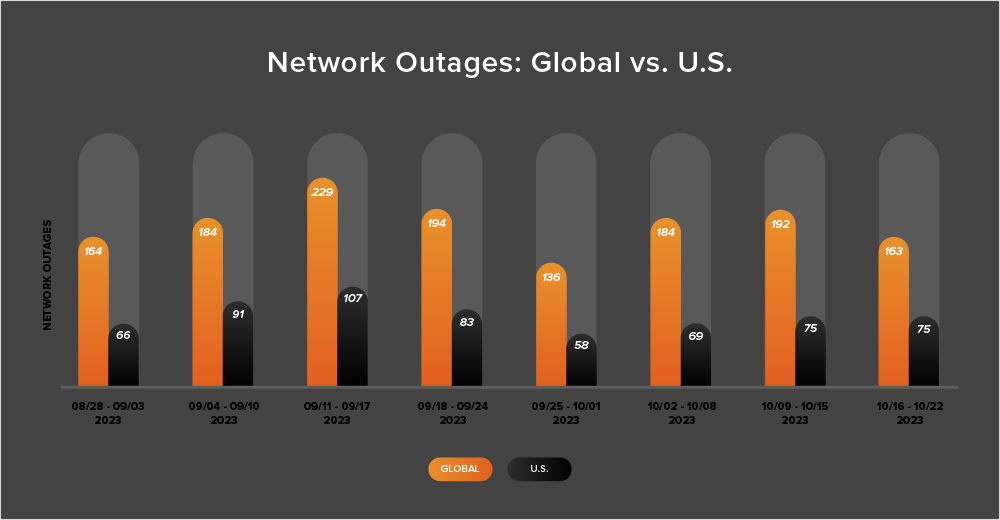
Over the course of the two weeks from October 9 to 22, outages rose slightly and then fell significantly. First, during the week of October 9-15, the number of global outages increased from 184 to 192, which represents a 4% rise in comparison to the prior week (October 2-8). The following week, observed outages dropped 15%, declining from 192 to 163, as depicted in the chart below.
-
U.S.-centric outages didn’t reflect the same pattern. They instead rose and then plateaued, initially increasing from 69 to 75—a 9% increase when compared to October 2-8. The next week (October 16-22), outages remained at the same level, 75.
-
From October 9 to 22, U.S.-based outages accounted for 42% of all observed outages, a return to the trend observed almost every fortnight since April 2023 in which U.S.-based outages accounting for at least 40% of all observed outages in a given two-week period. The prior fortnight (September 25 - October 8) had seen a brief departure from this trend, with the percentage dropping to 38%