This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
We often encounter (and analyze) incidents where work in one part of an app or service has an unanticipated flow-on impact. These incidents underscore the importance of understanding the entire service delivery chain in order to be aware of every dependency and interconnection, helping you keep impact and footprint to a minimum.
Having a detailed grasp of all dependencies is particularly important when making manual changes. Organizations today normally rely on highly automated change processes; teams are technology-assisted to begin with; and deployment and rollback may occur with little, if any, human intervention. However, there will always be exceptions where changes need to be made manually, outside of the standardized, automated change process. These manual changes require special care, and can be especially challenging because they require engineering teams to understand the intricacies of change processes, without the usual automated deployment checks and balances to assist them. Mistakes may be more likely to happen, perhaps causing an outage or service disruption.
We saw this play out this past fortnight, as a manual TLS/SSL certificate change by Microsoft introduced the type of error that an automated system would probably have detected and prevented.
Read on to learn more about this outage and other recent incidents, or use the links below to jump to the sections that most interest you.
SharePoint Online and OneDrive Outage
On July 24, Microsoft experienced an issue that impacted connectivity to SharePoint Online and OneDrive for Business services. First observed around 19:05 UTC, it appeared to impact connectivity for users globally.
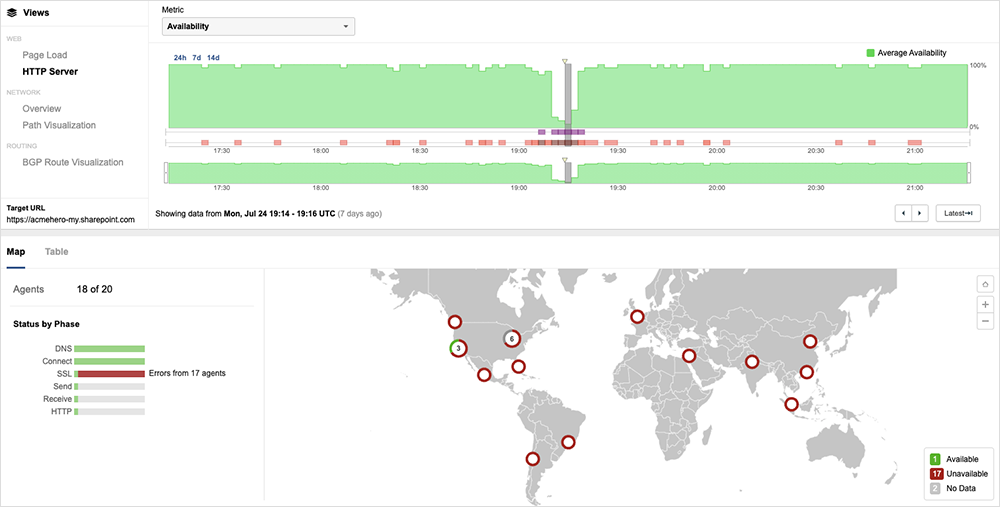
Users encountered a certificate error when attempting to access SharePoint Online and OneDrive due to an erroneous change in the SSL certificate that prevented the establishment of a secure connection to the services.
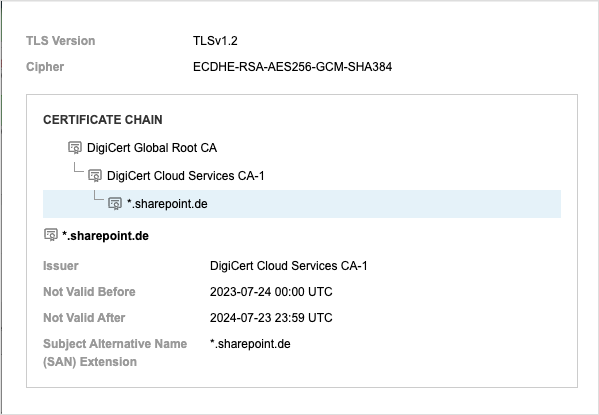
Approximately ten minutes later, at around 17:15 UTC, it appeared to be replaced with a valid certificate, and SharePoint and OneDrive service reachability was restored for most users by around 17:20 UTC. Around 21:34 UTC, Microsoft announced that the outage was the result of a configuration issue and had been resolved.
A curious aspect of this outage is that it seemed to be triggered by a manual change. Generally speaking, a majority of outages today appear to be triggered by unexpected conditions encountered during the operation of automated change or deployment processes. Detection and rollback are also often automated.
There were likely specific and valid reasons that Microsoft engineers manually replaced the certificate. However, with manual updates, having checks and validations in place to guard against human error is especially important. Microsoft likely had such processes in place, and it’s not clear how the erroneous change made it through, but events like these are good reminders for organizations to make sure they have strategies in place to help catch issues like a domain name mismatch.
The incident (and others like it) also highlight how important it is to have a certificate that’s valid in all aspects (with valid credentials, a correct domain name, etc.), as well as appropriate change verification steps. Every component in an end-to-end service delivery chain, and the teams and individuals responsible for those components, need to work in sync to maintain the service’s availability. Any deviation from standard operating procedures and documented change processes, can introduce risk. It only takes a degradation or outage in one component to have a flow-on impact, potentially taking out the entire service. Given this reality, some teams may choose to invest in tools that provide them visibility and early warning into things like soon-to-expire certificates—or put other strategies in place to guard against such issues.
Slack Outage
Slack experienced a “systemwide” issue on July 27 that left some users unable to send or receive messages for just under one hour. The issues occurred very early in the North American morning—just after 2 AM PDT—which would suggest system work was intended to happen outside of U.S. working hours (though it would have been mid-morning for parts of Europe).
A brief post-incident report notes that an issue was identified “after a change was made to a service that manages our internal system communication. This resulted in degradation of Slack functionality until the change was reverted which resolved the issue for all users.”
During the incident, users may have found it difficult to recognize or diagnose from a customer-facing perspective because everything would have “looked right.” Users could still connect, their availability status was correct, and they could read messages in Slack and even think they’d responded.
However, everything wasn’t normal. It appeared that their replies weren’t actually being sent. While things looked ok on the frontend, the backend components of the system could not be reached. This is a common outage pattern observed consistently with app outages.
Like the SharePoint and OneDrive outage discussed earlier, this Slack outage appears to be a second case of a change being made to a particular component of an app in isolation, without visibility into how that might impact end-to-end service delivery.
Starbucks App Outage
On July 20, Starbucks sent a push notification through its app notifying customers their “order is ready”—whether they’d ordered a coffee or not.
The glitch caused some confusion among customers, though we also suspect it might have triggered a surge in coffee demand as well.
The mass push notification coincided with a partial app outage that affected one specific portion of the Starbucks app’s functionality: the order ahead and pay feature. However, it’s unclear if the outage and mistaken push notification are related. Certainly, the push notification issue suggests there was active work on the messaging portion of the app. You’d also expect some sort of acknowledgement notification to be a function of the order ahead and pay feature, which was impacted by the outage. As Starbucks attempted to fix the outage, it’s possible that a change was introduced or a test message was mistakenly pushed to production, which may have been the erroneous “order is ready” notification.
Again, as demonstrated by the SharePoint and Slack disruptions, every piece of the service delivery chain has a critical role to play.
NASA Communications Outage
Finally, NASA experienced a communications outage with the International Space Station (ISS) on July 25 that impacted command, telemetry, and voice communications. The incident represented the first time backup communications had to be switched on.
The root cause of the issue was reportedly a power outage stemming from upgrade works in the building housing Mission Control at NASA’s Johnson Space Center in Houston. The outage appeared to solely impact the communications only, which essentially means that this was a ground-only issue, most likely only impacting local connections into Mission Control.
While we don’t normally discuss space comms in this blog, this outage reinforces a theme that we often emphasize: the importance of robust failover processes. Whether serving users in space or a bit closer to home, it’s vital to understand the what and why of any issues that may occur in order to quickly ascertain and action the most appropriate plan or process.
NASA maintains a backup control center; however, during the July 25 outage, the flight controllers stayed at Mission Control in Houston as it appeared that the lights and air-conditioning were still operating. This potentially points to quick identification of the cause and confidence in resolution time. NASA noted that they would try to better understand what happened and glean any resulting lessons.
As we’ve discussed in previous blogs, while it’s difficult to plan for every possible scenario, understanding what worked and what didn’t work when an outage occurs can be used to improve systems and processes, reducing the likelihood of the issue recurring. For example, in this case, in addition to their backup control center, NASA may also consider providing separate and/or backup power sources for their communication system.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (July 17-30):
-
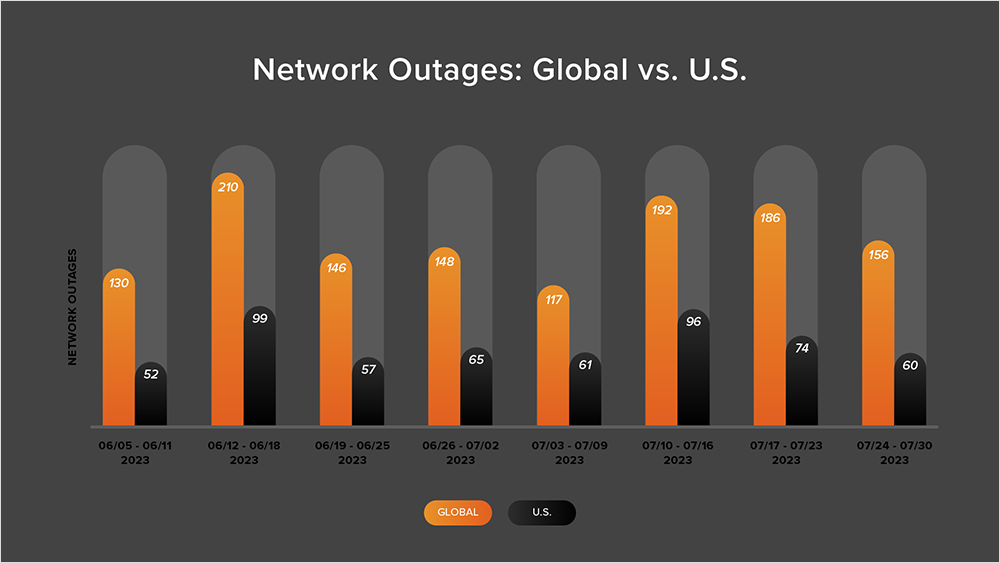
Global outages trended downwards over this two-week period, initially dropping from 192 to 186, a slight 3% decrease when compared to July 10-16. This was followed by another drop from 186 to 156, a 16% decrease compared to the previous week (see the chart below).
-
This pattern was reflected in the U.S., where outages initially dropped from 96 to 74, a 23% decrease when compared to July 10-16. U.S. outage numbers then dropped from 74 to 60 the next week, a 19% decrease.
-
U.S.-centric outages accounted for 42% of all observed outages from July 17-30, which is somewhat smaller than the percentage observed between July 3-16, where they accounted for 51% of observed outages. While this was a drop, it continues the trend observed since April, in which U.S.-centric outages have accounted for at least 40% of all observed outages.