


This is the Internet Report: Pulse Update, where we review and provide an analysis of outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read our full analysis below or tune in to our podcast for first-hand commentary.
Internet Outages and Trends
Before we dive into this week's highlights, we take a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (January 30-February 13):
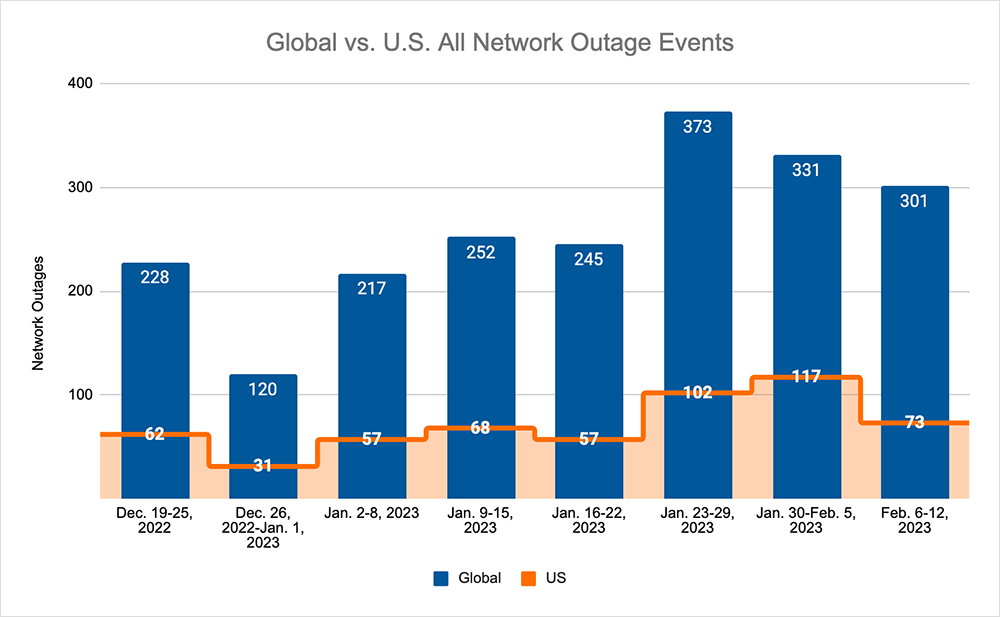
- Global outages trended down, dropping initially from 373 to 331, an 11% decrease when compared to January 23-29. This downward trend continued with global outages dropping from 331 to 301, a 9% decrease compared to the previous week.
- This pattern was not reflected domestically, initially rising from 102 to 117, a 15% increase when compared to January 23-29. This was followed by a drop from 117 to 73, a 38% decrease compared to the previous week.
- U.S.-centric outages accounted for 30% of all observed outages, which is larger than the percentage observed on January 16-22 and January 23-29, where they accounted for 26% of observed outages.
Notable Outages
We ended our last installment of the Weekly Pulse with the network configuration change by Microsoft on January 25 that caused application reachability issues globally.
But it wasn’t the only incident caused by a configuration change to occur in that timeframe. We also observed similar incidents at both Cloudflare and Slack.
Cloudflare
On January 24, less than 24 hours before the Microsoft incident, around 4:55 PM UTC, several Cloudflare services experienced two hours of downtime after a code deployment accidentally overwrote some service token metadata before it was recognized and rolled back.
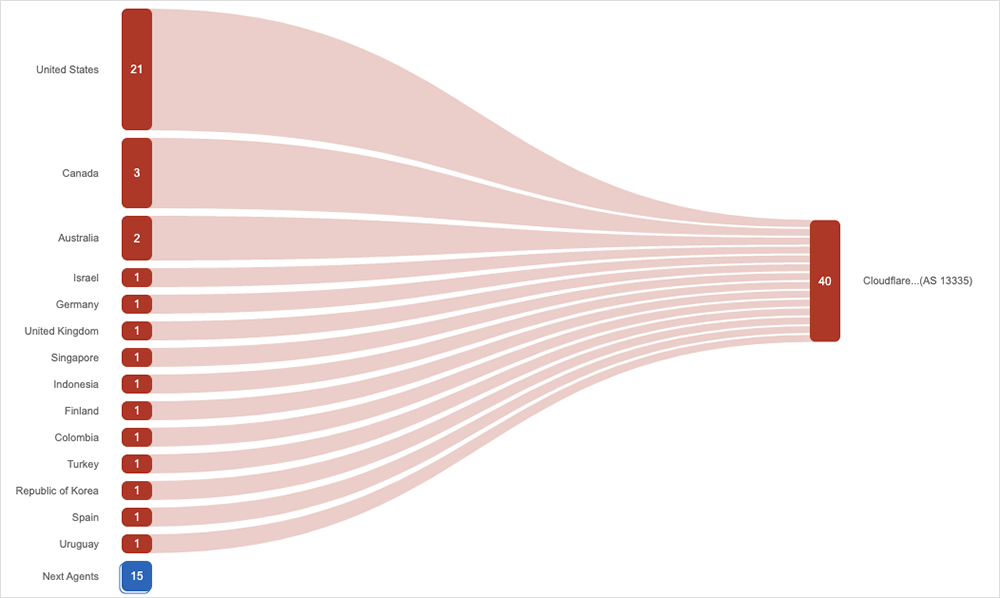
Service tokens “allow automated services to authenticate to other services,” Cloudflare said in its detailed post-incident report:
“Customers can use service tokens to secure the interaction between an application running in a data center and a resource in a public cloud provider, for example. As part of the release, we intended to introduce a feature that showed administrators the time that a token was last used, giving users the ability to safely clean up unused tokens. The change inadvertently overwrote other metadata about the service tokens and rendered the tokens of impacted accounts invalid for the duration of the incident.”
Two accounts where service token metadata was overwritten belonged to Cloudflare itself. These accounts powered other Cloudflare services. When the accounts couldn’t be authenticated, the errors started.
A manual restore of the service token values resolved the issue for the impacted Cloudflare accounts. However, the rest of the impacted accounts (those using Cloudflare service tokens for external services) had to be restored from backup later.
Slack
On January 25, Slack users were unable to load messages or threads, preview files, or send messages for a 26-minute period. Users may have been alerted to the issue because they were sent email notifications about the presence of new messages that hadn’t shown up in the application itself.
Similar to the Microsoft and Cloudflare incidents, this issue was also traced to a configuration change that impacted usability. “We traced this issue to a recent internal change and started reverting it immediately. Once this was reverted, the issue was resolved for all impacted users,” Slack explained.
Finally, on Feb. 2, we also saw a configuration change and rollback impact 911 services in part of Canada for two-and-a-half hours. The cause was reportedly a configuration change made in preparation for adding an extra digit to phone numbers in the region, which did not go as expected.
Microsoft
On February 7th, Microsoft experienced a second outage that closely resembled the previous January 25th outage in terms of global reach and duration. The main portion of both incidents lasted around 1.5 hours, with the February 6 outage first observed around 3:55 AM UTC and mostly resolved by 5:35 UTC. Like the January 25 outage, it also impacted customers in various regions across the globe, including North America, Europe, and Asia.
However, there were some key differences between the two events.
Unlike the January 25th outage, the February 7 incident appeared only to impact access to Microsoft Outlook services. Additionally, it did not appear to be network-related, as no significant packet loss, latency, or unusual routing behavior was observed during the incident.
The outage manifested in users' inability to send, receive, or search for emails, with connections timing out or receiving HTTP 500 service unavailable error messages. The bulk of the incident lasted approximately one hour and 39 minutes, although residual access issues could be seen for around the next four hours. Microsoft confirmed that a change to some of their Outlook systems had contributed to the outage and undertook targeted restarts to parts of their infrastructure impacted by the change to restore service to their users.
Square
On February 6th, Square was impacted by a global issue that left merchants unable to process or accept payments. It took a little over four hours to resolve the issue completely. The timing of the event largely impacted regions such as Oceania, where it’s reported that small businesses like cafes could not accept contactless payments during the morning rush.
The outage, however, breaks with the change-and-rollback pattern seen elsewhere in the past fortnight. You can read Square’s post-mortem of the incident here.
Comcast
Finally, there was an hours-long outage that impacted some Comcast customers on Super Bowl Sunday. On February 12, people in Philadelphia’s Fishtown and Kensington neighborhoods experienced Xfinity service interruptions ahead of the big game where the Philadelphia Eagles were set to face off against the Kansas City Chiefs. Comcast reported that they were able to restore cable access for a majority of customers before kickoff.
Comcast attributed the outage to vandalism, noting that a fiber optic cable was found severed in the Kensington section.








