This is the Internet Report: Pulse Update, where we review and provide an analysis of outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read our full analysis below or tune in to our podcast for first-hand commentary.
Internet Outages and Trends
Looking at global outages across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks, we saw:
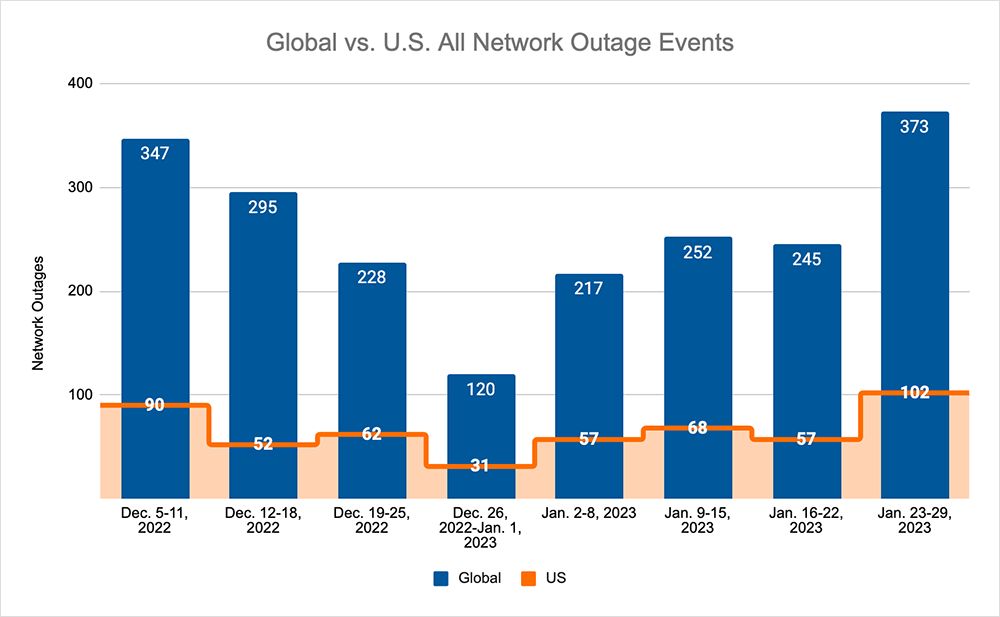
- Global outages initially trended down, dropping from 252 to 245, a 3% decrease when compared to January 9-15. This was then followed by a return to the upward trend observed since the beginning of 2023, with global outages rising from 245 to 373, a 52% increase compared to the previous week.
- This pattern was reflected domestically, initially dropping from 68 to 57, a 16% decrease when compared to January 9-15. This was followed by a rise from 57 to 102, a 79% increase compared to the previous week.
- U.S.-centric outages accounted for 26% of all observed outages, which is smaller than the percentage observed on January 2-8 and January 9-15, where they accounted for 27% of observed outages.
January Outages
We often talk about how individual applications interact with networks or behave when encountering different network conditions. That often leads to a discussion about application monitoring and testing to counter, or at least anticipate the effect of, anomalous conditions on certain routes.
Throughout January, we’ve observed several outages and disruptions that both reinforce this need, while also posing challenges when it comes to setting up appropriate monitoring.
On January 19, a range of web-based applications went down, including Pinterest, Jenkins, Cash App, Reddit, and PayPal. History dictates that there’s usually a common element when so many applications have problems at once, and monitoring telemetry quickly tells the story: a global issue with Fastly’s content delivery network (CDN). However, it was nowhere near the scale of a similar incident from 2021 (see our Fastly Outage coverage); this time, it was quickly detected and corrected by Fastly, with a declared outage duration of six minutes.
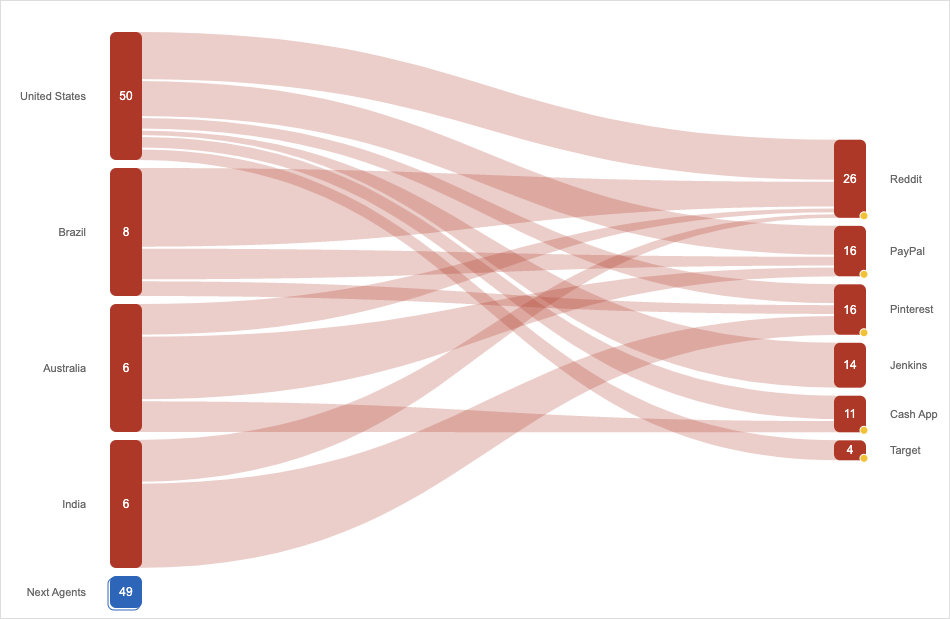
According to the Fastly status page, the disruption was attributed to a “configuration change [that] was deployed, which impacted performance to global CDN delivery. Fastly Engineering reverted the change, resulting in immediate recovery.” Network and application telemetry and monitoring clearly worked well on both the Fastly and customer sides. As we’ve discussed previously in our Fastly Outage Analysis, customers with redundant CDN infrastructure may have been able to avoid any impact entirely; although, we also know this level of redundancy often isn’t cost-effective.
January has also seen a string of incidents where applications showed susceptibility to disruption over certain networks but not others.
On January 17, a subset of Microsoft 365 users in the Eastern U.S. reported application accessibility issues. In a Twitter post from Microsoft, it appears they opened an investigation; although after an hour, it was clear this wasn’t a run-of-the-mill application issue. “Our telemetry indicates that the Microsoft-managed network environment is healthy. The issue appears to be limited to a specific local ISP,” Microsoft tweeted. Customers, meanwhile, started using their own telemetry to locate the source, with several recognizing Verizon as the common denominator. While not naming the ISP, Microsoft said that a combination of restarts and traffic rerouting on the ISP side resolved the application accessibility problems.
It’s unclear exactly what went wrong on the ISP side; however, it’s worth pointing out that this situation has happened before. In Australia in 2021, satellite Internet users could not access Microsoft 365 services for a number of weeks. The confusing part about this is that the disruption appears to have been specific to an individual application, while other applications appeared to be unaffected. It was eventually pinpointed to a routing issue in the network operator’s core. One possible theory is that the characteristics of Microsoft 365, and the way those characteristics respond and interact to different network configurations and conditions, could have been a contributing factor. One clue may be in the way the application responds to limited bandwidth connections—for example, by adjusting its packet size or using IP fragmentation. There’s a possibility that network configuration combined with specific application characteristics when interacting with that infrastructure led to these issues.
Elsewhere, on January 18, customers of digital payment service Zelle had issues with transactions disappearing from Bank of America accounts. Zelle attributed the problems to something on Bank of America’s side. “The Zelle app and network are up and running,” it tweeted. “We are aware of an issue that is impacting Bank Of America customers when sending and receiving payments.” The bank confirmed an unspecified issue on its end that resulted in a “delay in posting Zelle transactions.”
It’s worth also touching briefly on a couple of other incidents.
FAA Outage
On January 11, U.S. airspace was temporarily closed when the Federal Aviation Administration’s Notice to Air Missions (NOTAM) system went down. The ground stop—the first of its kind since 2001—impacted about 11,000 flights. The initial explanation was that a “damaged database file” caused the issue. How the file was damaged was explained officially a week later: “Contract personnel unintentionally deleted files while working to correct synchronization between the live primary database and a backup database.” It has since been reported that the IT contracting firm has had its access revoked.
No doubt there will be a much more detailed post-incident investigation into the NOTAM system and its apparent fragility. That being said, these kinds of incidents are challenging to plan for with such mission-critical systems. There’s often not a “good time” to take the system down for testing. That being said, disruption or outage risks may be mitigated by discovering and mapping out key system dependencies, which could lead to a faster diagnosis of issues if and when something does go wrong.
Microsoft Outage
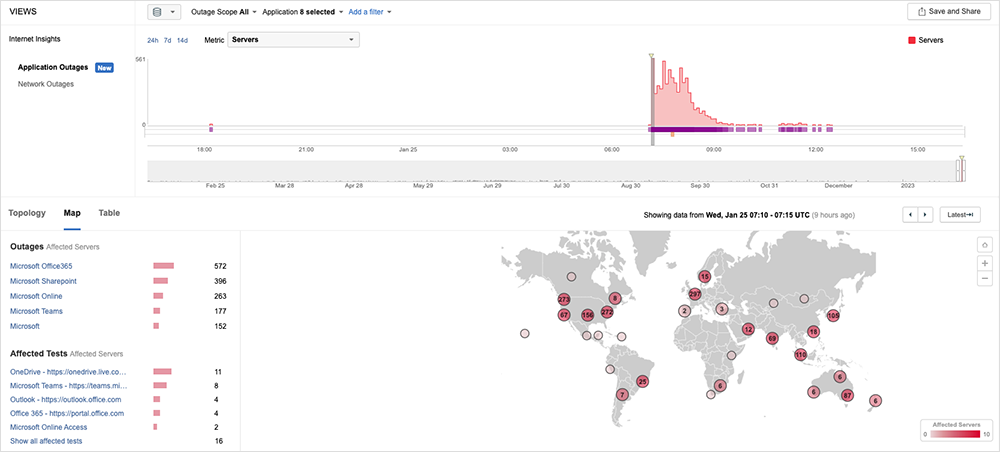
Returning to the theme of configuration changes that didn’t go as expected, on January 25, Microsoft experienced a significant disruption that impacted connectivity to many of its services, including Azure, Teams, Outlook, and SharePoint.
It was first observed around 2:05 AM EST, and it appeared to impact connectivity for users globally. Around 3:15 AM EST, Microsoft tweeted that they had identified a potential issue within the network configuration. Around 4:26 AM EST, Microsoft tweeted that they had rolled back the network configuration change and were monitoring the services as they recovered.
The bulk of the incident lasted approximately 90 minutes, although residual connectivity issues were observed over the next five hours. As we’ve discussed before, the time of day that the outage occurs has a direct bearing on how widely felt the impact is, and because this issue occurred overnight EST, it impacted the end of the business day in Asia and the start of the business day in Europe.
Microsoft has since released its preliminary findings suggesting this incident was the result of a planned change to update the IP address on one of their WAN routers. Inadvertently, the command issued to the router resulted in all the Microsoft WAN routers recomputing their adjacency and forwarding tables. It would then appear as a consequence of this re-computation process, the routers were unable to correctly forward packets traversing them, which manifested itself as packet loss and connectivity issues.