This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
In the cloud infrastructure world, redundancy matters. As we’ve previously discussed in the Pulse Update series, it makes sense to architect business-critical workloads to run across multiple AZs or regions as insurance in case IaaS becomes degraded in one location.
However, as businesses have become more cloud-native in their operations, many have found that it’s not always practical to have a backup for every cloud service they rely on. When it comes to central management consoles—for example, the Azure Resource Manager—or to specific apps running on cloud infrastructure, such as a payroll system, it may be impossible to have a redundant option at hand. In those situations, there may be nothing to do but wait for the degraded system to recover.
In such situations, ops teams need patience, but increasingly also assurance. When a cloud-based system starts to degrade, it may coincide with a status advisory from the cloud service provider. The temptation is to self-correlate the two events and wait things out. But how can you be certain that your issues are covered by the active advisory, and aren’t the result of something completely different?
During recent weeks, several incidents occurred that illustrate the themes discussed above. Read on to hear what happened during these disruptions, or use the links below to jump to the sections that most interest you:
Azure Resource Manager Exhausts Capacity, Causing Service Issues
On January 21, Microsoft Azure users were impacted by a degradation of Azure Resource Manager (ARM), the central tool used to deploy, manage, and control Azure-based resources. The root cause, according to a preliminary post-incident report, was a configuration change to an internal Azure tenancy that was one of a handful given preview access to a new feature in June 2020 that unknowingly contained “a latent code defect.” A configuration change in January 2024 appears to have triggered this dormant defect, which reportedly caused ARM nodes to fail on startup. More and more resources were consumed by the failing nodes, exhausting capacity in a number of regions before the issue could be mitigated.
ARM allows for consistent deployment of apps by defining the infrastructure and dependencies in a single declarative template, and so a failure of that stops any scaling or provision of apps, impacting downstream Azure services that rely on ARM for internal resource management, which may have resulted in certain services becoming unavailable.
Due to the relatively complex nature of the issue, it took around 2.5 hours for Microsoft technicians to diagnose it and come up with a mitigation strategy. The total duration of the disruption was around 7 hours. The saving grace for Microsoft was that it occurred on a weekend, reducing the impact on users. However, the critical nature of ARM in Azure operations meant that the users who were impacted could do little but wait for a fix.
Microsoft has pledged several changes, including disabling the aged feature preview and making changes to stop node problems in a single tenancy from leading to the cascading impact seen in this January 21 incident.
Network Issue Leads to Microsoft Teams Service Disruption
On January 26, Microsoft Teams experienced a service disruption that affected users globally. The incident caused issues with core service capabilities, including login, messaging, and calling. Microsoft later identified the cause as “networking issues impacting a portion of the Teams service” that required failover of services to alternative connectivity services. The issues were prolonged in the Americas where failover did not relieve the impact for all users, and it was only through further “network and backend service optimization efforts” that remediation was achieved.
ThousandEyes observed Microsoft Teams service failures that impacted its usability for some users. From our own immediate observations: “No packet loss was observed connecting to the Microsoft Teams edge servers; however, the failures are consistent with reported issues within Microsoft’s network that may have prevented the service’s edge servers from reaching application components on the backend.” ThousandEyes observed these failures starting at approximately 4 PM (UTC) (8 AM [PST]), and they persisted for more than 7 hours before the incident appeared to resolve for many users by 11:10 PM (UTC).

Users reported a range of issues, including login and server connection, frozen apps, message delivery difficulties, missing chat history and image files, and “being left in the waiting room after joining Teams meetings.”
Oracle Cloud Experiences Network Outage
On January 16, ThousandEyes observed an Oracle disruption on the company’s network that impacted customers and downstream partners interacting with Oracle Cloud services in multiple regions, including the U.S., Canada, China, Panama, Norway, the Netherlands, India, Germany, Malaysia, Sweden, Czech Republic, and Norway.
ThousandEyes first observed this incident around 1:45 PM (UTC) (8:45 AM [EST]) and appeared to center on Oracle nodes located in various regions worldwide. Thirty-five minutes after first being observed, all the nodes exhibiting outage conditions appeared to clear; however, 10 minutes later, some nodes began exhibiting outage conditions again. The disruption lasted around 40 minutes in total.
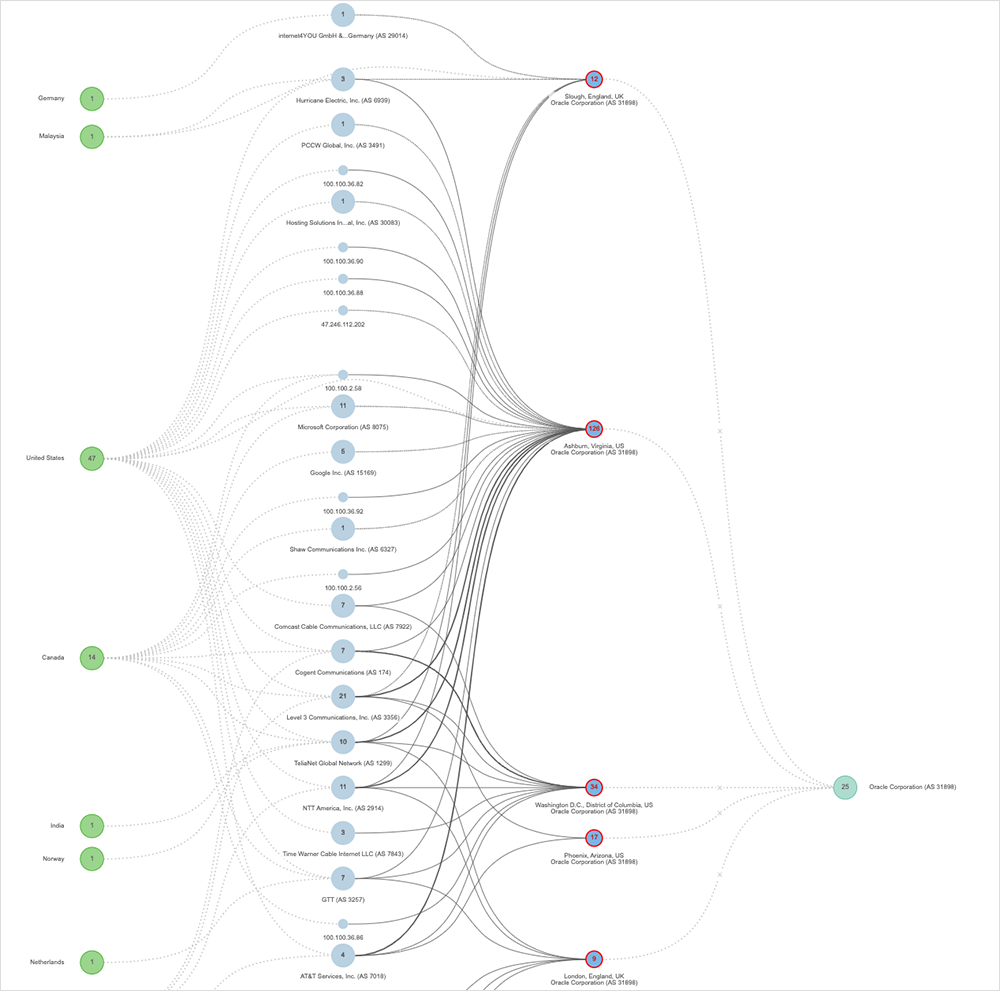
The issue seemed to impact a large number of data center sites and downstream services, such as NetSuite. Oracle didn’t appear to release an official status advisory or explanation. During the incident, ThousandEyes observed 100% packet loss on affected interfaces. The incident appeared to coincide with—or occur in reasonably close proximity to—a security patch released by the vendor. They could be related, but there’s nothing in ThousandEyes observations or data that definitively links the two occurrences.
Jira Users Encounter 503s and Other Errors
Users of Atlassian’s Jira saw 503 service unavailable messages and other errors for about 3.5 hours starting 6:52 AM (UTC) on January 18. The issues impacted “Jira Family” services, including Jira Work Management, Jira Software, and Jira Product Discovery.
According to Atlassian’s post-mortem report, the incident was caused by “a scheduled database upgrade on an internal Atlassian Marketplace service [that] resulted in degraded performance for that service.” This degradation issue caused an increase in back pressure, leading to requests timing out across Jira products and impacting user experiences.
ThousandEyes data shows that Jira services were back to normal operations by 10:30 AM (UTC). ThousandEyes observed certain functions/services as being unresponsive, indicative of a backend issue like the one Atlassian reported.
Sage Outage Impacts South Africa
On January 24, an issue appeared to prevent some Sage customers in South Africa from accessing the Sage Business Cloud Payroll Professional service. However, it appeared that customers who were already logged in could still use the service as expected. There’s no indication if this was at an authentication level, but the fact that if users were logged on, the service appeared to be operating normally may indicate that it was a failure at this foundation step. From ThousandEyes’ observations, no network-specific conditions appeared to coincide with the outage.
Red Hat Experiences Four Search-Related Incidents
Red Hat experienced four search-related incidents in January on January 3, January 15, and January 17, with the most recent happening on January 25. That outage affected multiple subdomains. The search function on any website is a single point of aggregation—a centralized function users and services leverage to determine how to navigate to specific parts of the site that match their interests. If this search function is unresponsive or fails, then navigating the site can become problematic. The issue’s recurrent nature suggests that the team may have been trying to improve or resolve a prior issue. All of Red Hat's subdomains appeared reachable; it seemed that users only experienced the issue when trying to execute the search function.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (January 15-28):
-
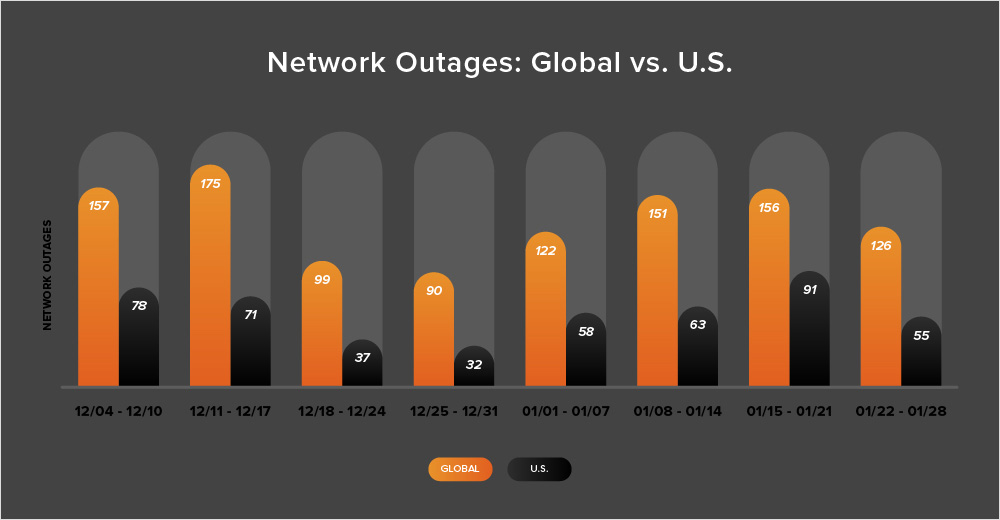
As we approach the end of January, the number of global outages initially continued increasing before dropping by 19% in the month’s final full week (January 22-28). This is the first week outages have decreased in January; during the month’s first three weeks, outages rose by 36%, then 24%, and finally 3%.
-
The United States appeared to follow a similar trend, with observed outages increasing for most of January and then decreasing toward the end of the month. In January’s first three weeks, U.S.-centric outages rose 81%, 9%, and 44%, respectively. However, during the month’s final full week, U.S.-centric outages decreased by 40%, with the number of outages dropping from 91 to 55.
-
Over the past two weeks, more than half of all observed outages (52%) occurred in the United States. This continues a trend seen consistently since April 2023 (with only a few exceptions), in which U.S.-centric outages account for at least 40% of all observed outages in a given two-week period. It’s also worth noting that 52% is the highest percentage observed in 2024 and also far exceeds the 2023 monthly average (37%). However, despite this high percentage of U.S.-centric outages from January 15-28, most of the outages observed appeared to be of reasonably short duration and contained. In other words, they didn't appear to have a radiating effect that would have resulted in an increase in global outage numbers.