


There’s a saying that “good things come in threes.” Some believe the reverse also holds true. After this recent two-week period, Microsoft may be a convert to that theory.
In the first of three incidents, Microsoft 365 desktop users were unable to authenticate and sign into services (although its web and mobile versions of Microsoft 365 were spared). The problems started around August 20, although it was not until August 24-25, depending on which part of the world you’re reading this from, that authentication issues impacted a large number of users. Japan, in particular, was hard-hit, while others in the region experienced some impacts as well.
ThousandEyes observed connection failures and timeouts as users on Windows machines tried to authenticate unsuccessfully with Azure Active Directory.
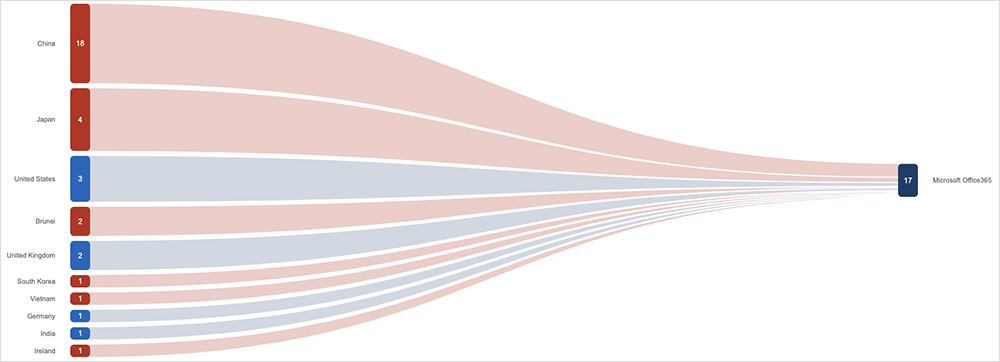
The root cause appears to have had nothing to do with Microsoft, and everything to do with a third-party security plug-in. “The Microsoft Azure AD WAM [Active Directory Web Account Manager] plug-in [was] removed as a side effect of a remote scan performed by a vulnerability assessment software provided by Tenable, a third-party provider. The plug-in facilitates the authentication of desktop applications,” Microsoft said in an advisory note.
More simply put, a vulnerability scan apparently uninstalled the desktop authentication client used to connect to Microsoft 365 services. Microsoft and Tenable eventually patched the plug-in, but the impact on customers had already been felt.
Fortunately, the impact was limited to a specific configuration of enterprise systems. It required desktop use of Tenable and Microsoft 365. In addition, an article in Tenable’s online community advised that customers “with scanners on custom feed schedules or in ‘air-gapped’ environments were most at-risk.”
The second incident to impact Microsoft services was similarly unusual. Azure users running Ubuntu 18.04-based virtual machines, with an automatic patching feature of the operating system called “unattended upgrades” enabled, received the following response: “systemd version 237-3ubuntu10.54.” This would have manifested as DNS resolution errors for backend systems, which was reflected in ThousandEyes’ outage map.
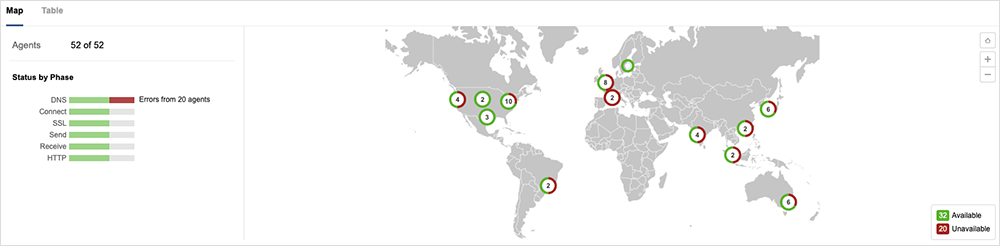
Microsoft said that a “combination of different Canonical Ubuntu updates led to a race condition, which manifested in DNS failures for Ubuntu 18.04 (bionic) Azure VMs.” An Ubuntu bug report confirmed the bug caused “a widespread outage … on Azure instances. Instances could no longer resolve DNS queries, breaking networking.”
In a post-incident report, Microsoft indicated it would review the ability for customers to have unattended upgrades enabled for Azure VMs. “When users opt into unattended updates [sic], they agree to receive updates from Canonical immediately after it is published. Considering their criticality, security updates do not go through our SDP [safe deployment] process, however, we are reviewing this process in the medium term to ensure that we minimize customer impact during incidents like these.”
The third incident for Microsoft flew largely under the radar. A power outage caused by regional wildfires triggered a loss of power to the 10+ facilities that power its West US 2 cloud region. However, as we’ve seen many times before, backup systems (the UPS and generators) may have failed to kick in or could not carry additional load at two of these facilities, leading to a disruption to services.
The two facilities that went offline housed “a number of storage and compute scale units,” Microsoft said in a post-incident report. That led to issues with a range of storage and database-oriented Azure services.
From ThousandEyes’ observations, it appeared Microsoft was able to load-balance and reroute customer resource requests to other (online) storage infrastructure in different regions to offset customer impact. We observed little direct customer impact caused by this incident aside from some increased latency.
Internet Outages and Trends
Looking at global outages across ISPs, cloud service provider networks, collaboration app networks, and edge networks, over the previous two weeks we saw:
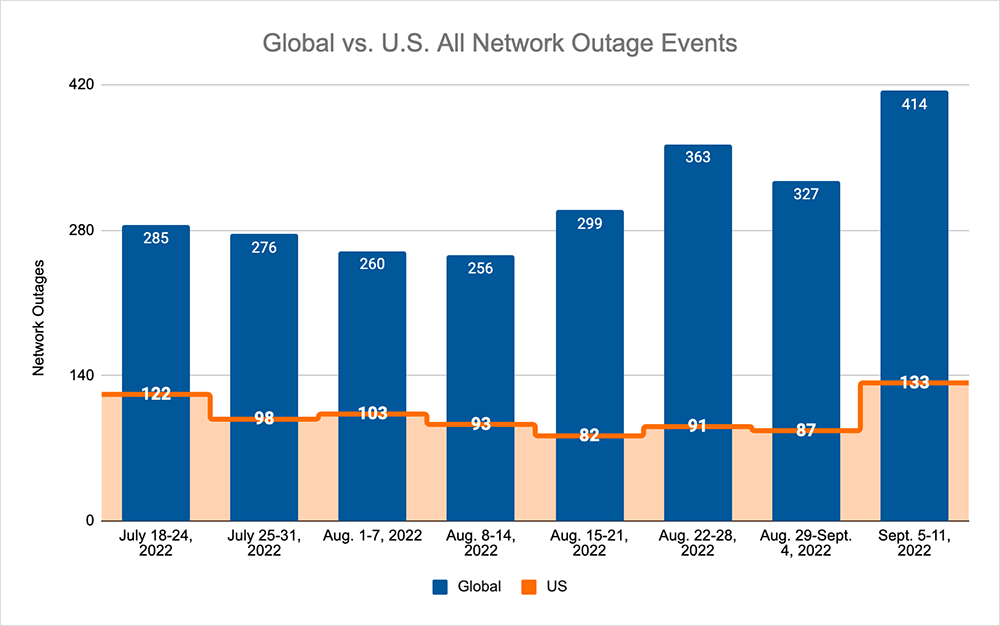
- Global outages initially dropped from 363 to 327, a 10% decrease compared to August 22-28, before rising the following week, where we observed a rise from 327 to 414, a 27% increase when compared to the previous week.
- This pattern was reflected domestically, with an initial drop from 91 to 87, a 4% decrease compared to August 22-28, before rising from 87 to 133, a 53% increase from the previous week.
- US-centric outages accounted for 30% of all observed outages, which is a larger percentage than observed in August 15-21 and Aug 22-28, where they only accounted for 26% of observed outages.
A pair of non cloud-related outages or post-incident actions are also worth touching on.
First, Starlink is reported to have suffered a global outage on August 30 for about three hours. Users also reported degraded speeds as the low earth orbit (LEO) satellite broadband service came back online. It appears there was no official confirmation or post-incident report.
There was also a report that Rogers Communications in Canada will split its wireline and wireless networks as part of ongoing action stemming from a July 8 outage that impacted more than 12 million users. It’s become common for subscribers of Rogers’ wireline services to have a cellular backup service for continuity purposes. This would not work, however, if the wireline and wireless networks are interdependent.
The fact that these networks will now be separated is a positive. It shows Rogers has done its investigative analysis, accepted they have single points of failure, and are now using the data and information to take action and eradicate those single points. This is exactly what you want every network operator or cloud provider to do after an incident: establish visibility or close visibility gaps into their infrastructure, identify areas for optimization or improvement, and action them. You really can’t ask for more than that.









