This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
The last Pulse Update blog discussed lightning in a metaphorical sense, but this week there’s a very real lightning strike to report on. On August 30, a lightning strike reportedly took out a data center that was home to some Azure and OCI servers, with outages lasting between 13 and 46 hours. The lightning caused a voltage fluctuation that led the chiller plant to fail; a combination of technical issues and suboptimal recovery mechanisms meant the primary chillers didn’t restart, and at least one of the redundant chillers also failed.
It wasn’t the only data center to experience issues in the past fortnight: Payments provider Square experienced a facility issue that took payment services out for a day.
Additionally, another outage created days of problems for UK flights when a previously unseen duplicate waypoint name on a single flight plan caused both primary and backup systems to fail.
One thing is clear: In a world that operates at “hyperscale,” the potential for hyperscale-sized problems, is also very real. Such outages can last for a significant amount of time and have major impact. The measure of a good provider—and a well-engineered system—is how well they handle these anomalous conditions and minimize disruption.
Read on to learn more about these recent outages and disruptions, or use the links below to jump to the sections that most interest you.
Oracle OCI, NetSuite, and Microsoft Azure Outages
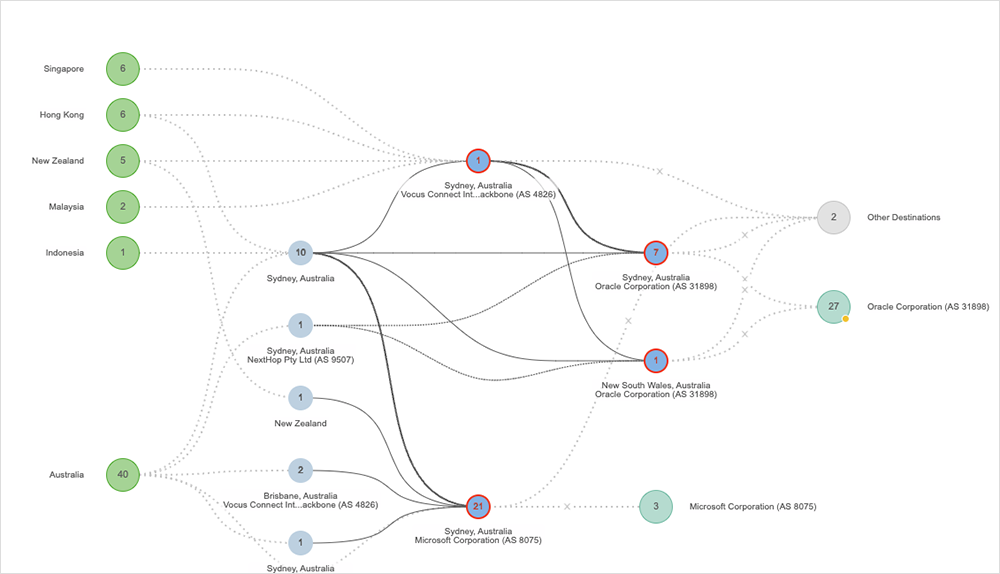
Ten thousand lightning strikes were recorded over a two-hour period in Sydney, Australia, as severe storms hit on August 30. A local data center was one of the buildings impacted by the lighting strikes.
A composite picture across the various post-incident reports has emerged: The lightning strike caused a voltage fluctuation to the mains power feed. That, in turn, tripped safety mechanisms on the facility’s chillers. For a variety of reasons—lack of staff onsite late at night, complex restart procedures, and technical problems with the chillers themselves—not all of the cooling capacity could be brought back online.
From there, ambient temperatures on the data floors rose; servers were either gracefully shut down to prevent damage and reduce load on the functional chillers, or failed due to thermal damage; and recovery was a painstaking process.
The incident was particularly hard-felt because the facility appears to be a shared space, home to Microsoft Azure, Oracle OCI, NetSuite, and others. It took 46 hours to fully recover Azure services. NetSuite access was down for 13 hours. Oracle Cloud Infrastructure took 29 hours to be fully restored. And these are only the services that have published detailed post-incident reports. Other SaaS platforms were also out during the same timeline, likely due to the same data center incident.
Undoubtedly, there are lessons to be learned from an incident of this magnitude. Microsoft, for example, has taken multiple steps already: Temporarily increasing the size of the overnight team and revising its documented emergency operating procedures so that the processes are faster to execute in a large-scale outage event.
Microsoft says it also plans to make more data-driven decisions if a similarly-sized incident occurs in future. One of its lessons learned is that the “sequencing workload failovers and equipment shutdown could have been prioritised differently with better insights.”
When making data-driven decisions, it’s helpful to understand not just the interconnectivity and dependencies of the entire service delivery chain, but also how, where, and what systems operate together. Teams can then apply this insight to restoration process plans, where critical aggregation components can be prioritized to restore some form of services as soon as possible.
UK Air Traffic Control Outage
A post-incident report also sheds light on a major systems failure on August 29 that led to hundreds of flight cancellations in the UK, and a flow-on impact lasting days.
The root cause was a flight plan processing subsystem that was unable to handle an anomalous condition. The system had processed more than 15 million flight plans over five years, but was asked to approve a flight plan that contained “two identically named, but separate waypoint markers outside of UK airspace.” Waypoints are geographic markers used to aid airspace navigation.
The condition triggered a “critical exception” in the primary system; that led to a backup system being engaged. However, as the backup was a replica of the primary, it encountered the exact same exception, and the backup system shut down too. The system design meant it could not reject the plan outright, but also it couldn’t accept the plan due to the risk of “presenting air traffic controllers with incorrect safety critical information.”
Recovery times were lengthened due to the need to identify the offending flight plan, safely remove it from both systems, and then bring the systems safely back into operation. NATS—the operator of air traffic control services in the UK—said that “steps have been taken to ensure the incident cannot be repeated.” These include automated detections for the specific condition, “enhanced monitoring,” and training engineers and operators in prompt remediation techniques.
Continued investigations are looking into the subsystem design, as well as testing and recovery procedures. The goal of that work is likely to be the introduction of enhanced exception-handling mechanisms to ensure that one errant plan can be recognized and triaged without impacting the rest of the system. Whether that means stopping the system that encounters an error and temporarily re-routing load to the backup system for continuity, or some other mechanism, it could be the subject of future reports.
Mailchimp Disruption
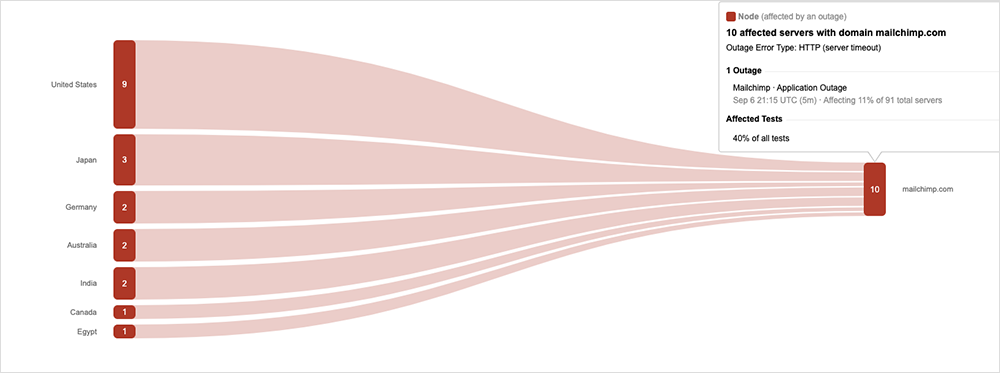
Marketing automation service provider Mailchimp encountered unspecified data center issues on September 6 that impacted its global user base, and also experienced further issues the following day. On both occasions, the explanation was “connection issues,” meaning the incidents could be related, perhaps signalling a configuration change attempt and rollback on a backend system, followed by a second attempt the next day. ThousandEyes’ observations also showed what looked like multiple change attempts on the first day.
The incident manifested as timeouts for users; while they could log in to Mailchimp’s servers, they were unable to complete email marketing campaigns.
Square Outage
On September 8, contactless payments terminal and service provider Square experienced its own backend connectivity issues that led to businesses being unable to process transactions. The “disruption” hit “multiple Square services,” and took 18.5 hours to remediate. And residual effects may have lasted even longer as the 18.5 hour timeframe doesn’t appear to take into account flow-on impacts to funds that were transferring and other payments processing.
Users reported various problems, from terminal connections dropping out, to payments appearing to complete but then not showing up in business accounts. ThousandEyes observed intermittent dropouts and 503 ‘service unavailable’ errors. The degradation pattern suggests the root cause may have been an internal routing or similar backend system.
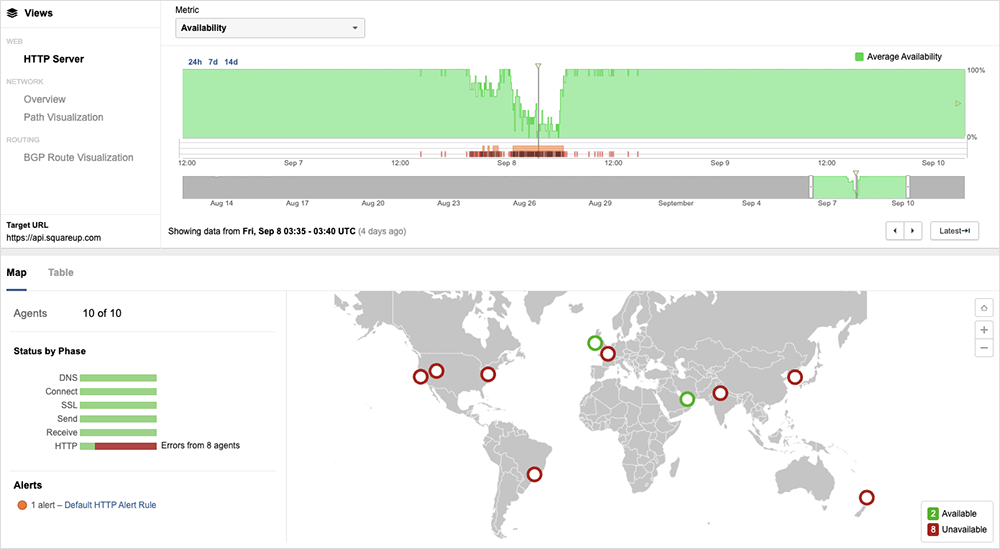
Square’s post-incident report confirms that an issue with the backend system was indeed the cause: “The outage impacted an important part of our infrastructure, known as a Domain Name System, or DNS,” Square noted in the report. “While making several standard changes to our internal network software, the combination of updates prevented our systems from properly communicating with each other, and ultimately caused the disruption. The issue also affected many of our internal tools for troubleshooting and support, making them temporarily unavailable. There is no evidence that this was a cybersecurity event or that any seller or buyer data was compromised by the outage.” This Square outage is somewhat reminiscent of the October 2021 Facebook outage. Though the two outages don’t appear to have exactly the same cause, some of the symptoms seem similar, such as issues connecting to internal tools, and may have contributed to the extended length of the disruption.
The company said it’s taking steps to “help protect against these types of issues in the future and to provide better communication during any sort of disruption.” These steps include deploying a new set of firewall and DNS server changes to guard against the same issue happening again, instituting further “operational measures” to “limit the risk of future outage,” expanding offline payment capabilities, and also providing faster communication about Square’s current health via a variety of channels.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (August 28-September 10):
-
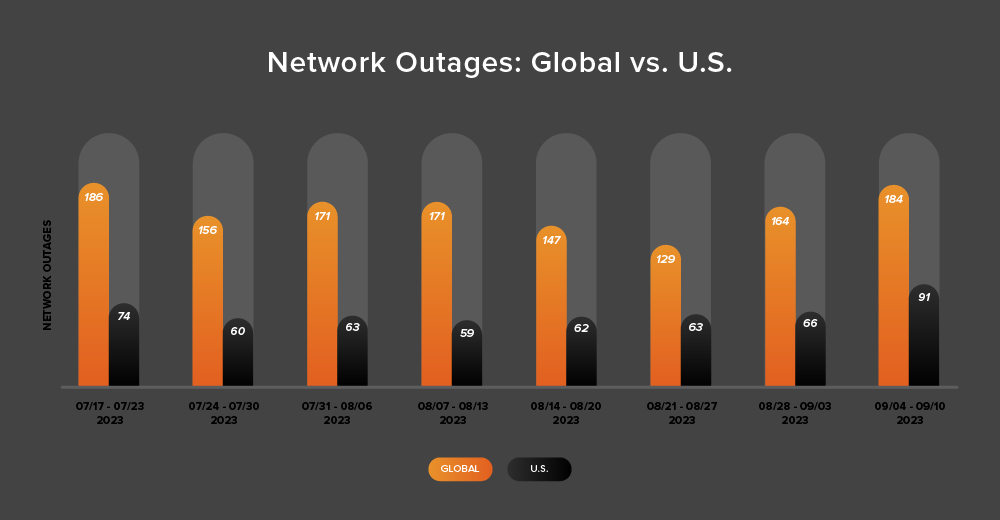
While the Northern Hemisphere summer technically isn’t over until the autumnal equinox on September 23, with the school year starting, for all intents and purposes the main summer season has come to a close. The end of the summer season coincided with an upward trend in global outages over the two-week period from August 28-September 10. During this period, outages initially rose from 129 to 164, a 27% increase when compared to August 21-27. This was followed by a 12% increase the following week, with observed outages rising from 164 to 184 (see the chart below).
-
U.S.-centric outages reflected the same pattern, with an upward trend over the same two-week period. Initially rising from 63 to 66—a 5% increase when compared to August 21-27, they again rose from 66 to 91 the next week, a 38% increase.
-
U.S.-centric outages accounted for 45% of all observed outages from August 28-September 10, which is the same percentage observed between August 14-27. This percentage makes sense: Even though the global outage numbers rose from 129 to 184, a 43% increase for this period, they didn’t increase by the same percentage as U.S.-centric outages over the two-week period, which rose from 63 to 91—a 44% increase. By contrast, the previous two-week period saw global outages drop from 171 to 129, a 25% decrease, while US-centric outages rose from 59 to 63, a 7% increase. This also continues the trend of U.S.-centric outages accounting for at least 40% of all observed outages—which has been the case since April except during July 31-August 13.
-
Looking at total outages in the month of August, global outages rose from 691 to 727, a 5% increase when compared to July. This pattern was not reflected in the U.S., with outages dropping from 308 to 288, a 6% decrease. This downward trend reflects patterns observed in previous years across the Northern Hemisphere summer.