This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
When an update or maintenance work doesn’t go as expected, a rollback and revisit is required. The question then becomes how “take two” lands: Will it be a case of “second time’s the charm” or a situation where “lightning does, in fact, strike twice”?
Engineering teams would generally expect the first option; after all, when something goes wrong, they learn from it and factor that into a second attempt and/or future decision-making when it comes to similar work. As a result, the re-try will likely run much more smoothly in most cases.
While another outage might still occur during this “take two,” the impact is usually nowhere near as severe as the first time around. Teams are generally more sensitive when applying a change a second time, and more likely to stop work at the smallest sign of trouble.
Slack recently experienced a pair of disruptions that may illustrate this take two scenario: a longer disruption resulting from a routine database cluster migration, followed by a much shorter outage a few weeks later that also involved database work, potentially indicative of related work that went more smoothly.
Read on to hear more about what happened at Slack, and also explore recent disruptions at X (formerly Twitter), Discord.io, and Wellington Hospital—or use the links below to jump to the sections that most interest you.
A Pair of August Slack Outages
A fortnight after a “routine” database cluster migration clashed with a scheduled job that required database capacity to complete—causing a two-hour degradation—Slack experienced another database-related incident, though with a much shorter 17-minute duration.
This August 17 issue manifested to users as messages not being sent and threads failing to load.
According to the official explanation from Slack, an “indexing change caused a higher than expected level of requests to our database. The resulting high load errors were responsible for the impacted users' inability to load messages and channels.”
Slack recognized the issue relatively quickly—likely they observed the degradation conditions develop as they undertook the indexing work and reversed the changes to resolve the issue. Engineers “then deployed a fix to prevent this from reoccurring in the future.”
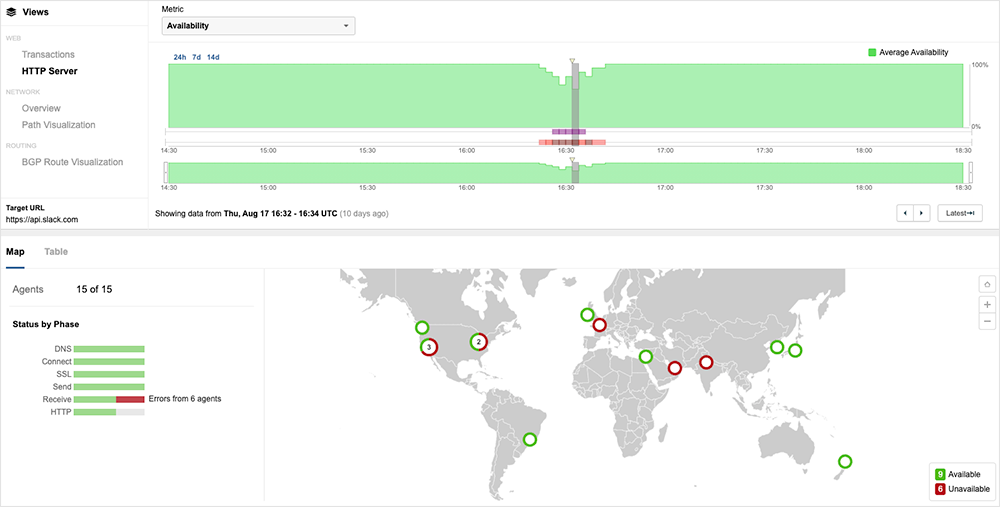
ThousandEyes observations of the incident, and of Slack’s servers, showed a clear “step pattern” emerge as the indexing change was first applied, which is indicative of a load situation developing. At first, only a handful of servers were impacted, but that grew to dozens and eventually over 100. As more servers were impacted, the load on the remaining servers increased. This only eased when the change was reversed.

The issue impacted user locations globally, but unevenly. Some users would have successfully reached Slack’s servers, while others might not have. ThousandEyes tests showed a variety of end-user experiences: Some users encountered prolonged wait times for Slack content to load, while others couldn’t get a response back from a server at all.
Given that both the August 2 and August 17 incidents involved database work, it’s conceivable they’re in some way connected. However, it’s hard to be definitive as an outside observer of their network and infrastructure. Both disruptions appear to be related to increasing performance: a cluster upgrade and indexing work (likely to make querying more efficient). But again, this could simply be circumstantial.
What’s clear—and this is not just for Slack but any service provider that makes a change that has to be rolled back—is that they’ll have to revisit the work again at some point. It’s of course possible Slack has already done so, and since we’ve observed no unusual or disruptive traffic patterns since August 17, Slack engineers may have managed to re-do the indexing work without issue.
This brings us back to the point mentioned at the beginning of this blog: Generally, when providers are forced to roll back a change, and then they revisit it a few days or a week later, they have a higher chance of getting it right. Or, if it goes wrong a second time, they’re more alert to the potential for issues and can commence a rollback faster.
Slack is a case in point: Even if the two database-related incidents aren’t linked, the company was likely focused on the potential for a change to cause an issue, and for the need to quickly trigger a rollback. For the August 17 issue, this could be why rollback and recovery can be counted in minutes and not hours.
X Disruptions
X, formerly Twitter, experienced a bug on August 22 that made the content of images uploaded before 2014 disappear. The issue reportedly affected “old posts that came with images attached or any hyperlinks converted through X’s built-in URL shortener.”
The company confirmed that weekend work—presumably maintenance of some sort—caused the bug. “No images or data were lost,” X said in an official support post, adding the bug had been fixed but that it would take a few days for the issue to be fully resolved.
In the week following this work, there appeared to be only small iterations and “blips,” none of which appeared to significantly impact the user population. However, on Saturday, August 26, at around 11 AM UTC, a pattern of outages began to appear. Initially, the outages were short, lasting between 4 to 8 minutes. These brief outages continued throughout August 26, with errors initially observed as server timeouts turning into HTTP 503 service unavailable errors—indicative of back-end connectivity issues. On August 27, around 12:30 AM UTC, two extended periods of disruption were observed, the first lasting around 38 minutes in total and the second 61 minutes.
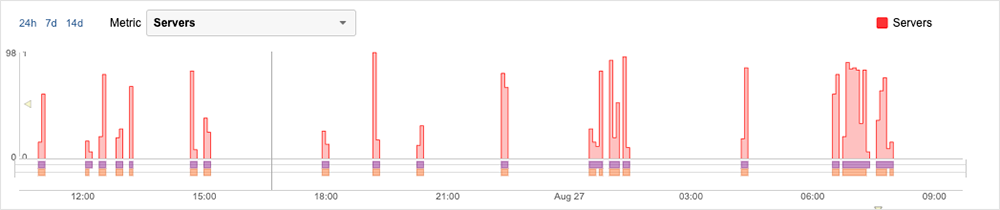
Drilling into these extended periods, a similar pattern became apparent: Both disruptions featured an increase in page load time that showed an initial wait time while the page waited either to be redirected or retrieve some content. In some cases, this content simply timed out; meaning the page was unable to connect to the content. However, during these periods of disruption, the main response observed was HTTP 503 errors. Upon inspection, it could be seen that after the request for the content following a waiting period, the system would return a standard error 503 response.
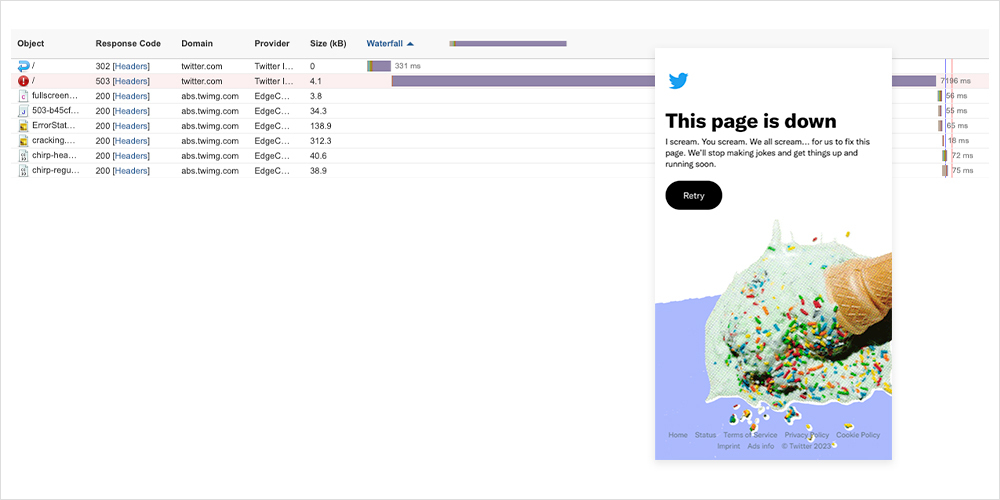
Despite what looks like a lot of disruption across the weekend, it did not appear to have a significant impact on the end user, according to anecdotal reports. The minimal end-user impact may have resulted from the timing of the disruption, which took place during off hours. This timing, in turn, may point to both disruptions being caused by planned maintenance or engineering-related activities. While there’s no direct correlation between the previous weekend's work and the events of the following weekend, the fact that they both appeared to be focused on linking and connectivity to backend content and resources may mean that the second weekend’s outages were caused by a continuation of the work that had started the previous weekend.
Discord.io Outage
Discord.io, a third-party service for crafting custom invitation URLs to Discord servers, has taken itself offline “for the foreseeable future” following a data breach. The incident occurred on August 14, and the service has been offline more or less since, with the company explaining the decision was made “after confirming the content of the breach.” It could take some time to resurrect, as this is conditional on a “complete rewrite of [their] website's code, as well as a complete overhaul of [its] security practices.”
It isn’t overly unusual for a company to pull its systems offline after a cyber incident; it happened to Western Digital and payroll and HR platform provider SD Worx a few months ago. Nor is a complete reconstruction of affected systems or infrastructure unusual: Maersk took this step following NotPetya.
Wellington Hospital Outage
We noted in July that in outage-land, sometimes “when it rains, it pours.” That observation was made in connection to an Azure outage that occurred while capacity was still being brought on to deal with the effects of an earlier incident.
Add the recent experience of Wellington Hospital in New Zealand to this. An August article sheds light on the compounding factors that contributed to Wellington Hospital’s June outage. Its systems went down when its data center chillers failed. This would ordinarily have been recognizable through a cloud-based services hub, which unfortunately was out at the same time.
We’ve covered before the catch-22 of redundant systems: You need them, but what level of redundancy is cost effective, compared to the risk of multiple systems going out at once? Odds are, of course, that a handful of organizations will experience a “perfect storm” of failures at some point in their existence.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (August 14-27):
-
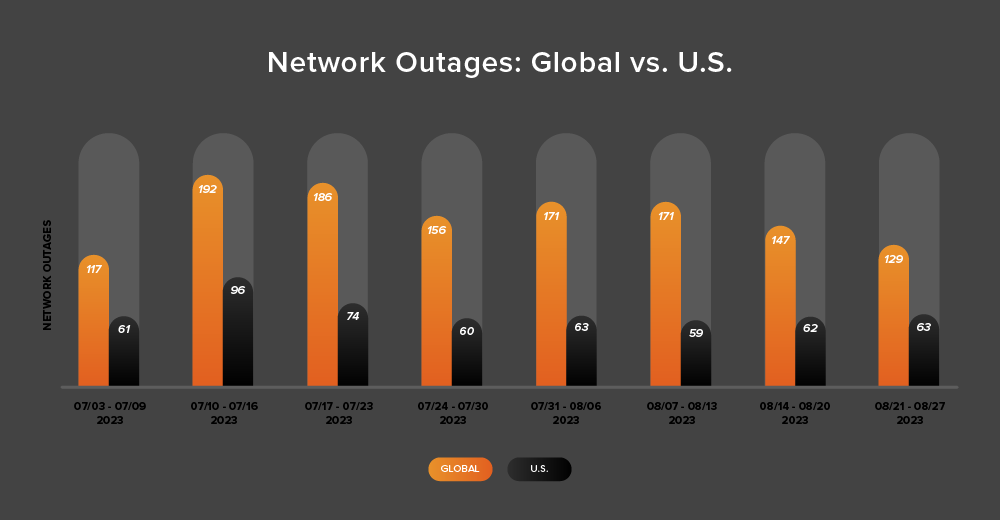
Global outages exhibited a downward trend over this two-week period, initially dropping from 171 to 147, a 14% decrease when compared to August 7-13. This was followed by a 12% decrease the following week, with observed outages dropping from 147 to 129 (see the chart below).
-
In contrast, U.S.-centric outages showed a slight upward trend over the same two-week period. Initially rising from 59 to 62—a 5% increase when compared to August 7-13, they again rose slightly from 62 to 63 the next week, a 2% increase.
-
U.S.-centric outages accounted for 45% of all observed outages from August 14-27, which is somewhat larger than the percentage observed between July 31 and August 13, where they accounted for 36% of observed outages. This change is expected given the decrease in global outage numbers and the rise of U.S.-centric outage numbers over the two-week period. However, it’s worth noting because it represents a return to U.S.-centric outages accounting for at least 40% of all observed outages—a trend seen consistently since April except during July 31-August 13.