


Welcome to another week of the Internet Report. UCaaS outage numbers almost doubled this week, continuing a trend observed over October. As in past weeks, much of this appears to be maintenance related and is not causing any major customer-facing impacts. It’s clearly in the interest of the UCaaS providers to keep it that way. Enterprises view collaboration apps as the most critical application type for hybrid work success. Outages typically occur outside of business hours and do not coincide with any wide-scale user impact reports, indicating that any interruption was negligible.
Total outage numbers increased for the third successive week, increasing 17% from the previous week. This was reflected domestically with outages observed in the U.S. increasing by 16% compared to the previous week. However, as opposed to the previous week's upward trend observed across the total outages, this increase reversed a three-week downward trend for outages observed across the U.S.
The largest increase in outages observed globally was seen across the ISPs, which also experienced a 17% increase in outages when compared to the previous week. In addition to the increases observed, there was also a shift in the “day of the week” where most outages occurred. Over the past month, this has predominantly been a Tuesday, but last week the day of the week where we observed the most outages shifted to a Friday. The Tuesday prominence we observed over the past few weeks matches a pattern of engineering and maintenance exercises, timed to have minimal impact to both the users.
Of course, in many cases you can’t plan for an outage, and the sole fact the day of the week that experienced most outages moved to the end of the week doesn’t necessarily reflect a permanent change, nor does it imply that the potential impact of inconvenience is any greater. But it may indicate that outside of the “unscheduled” outages, the new global 24x7 world in which we are operating may lead to a leveling across the days of the week, as more operators look to leverage more of an automated DevOps approach to this exercise.
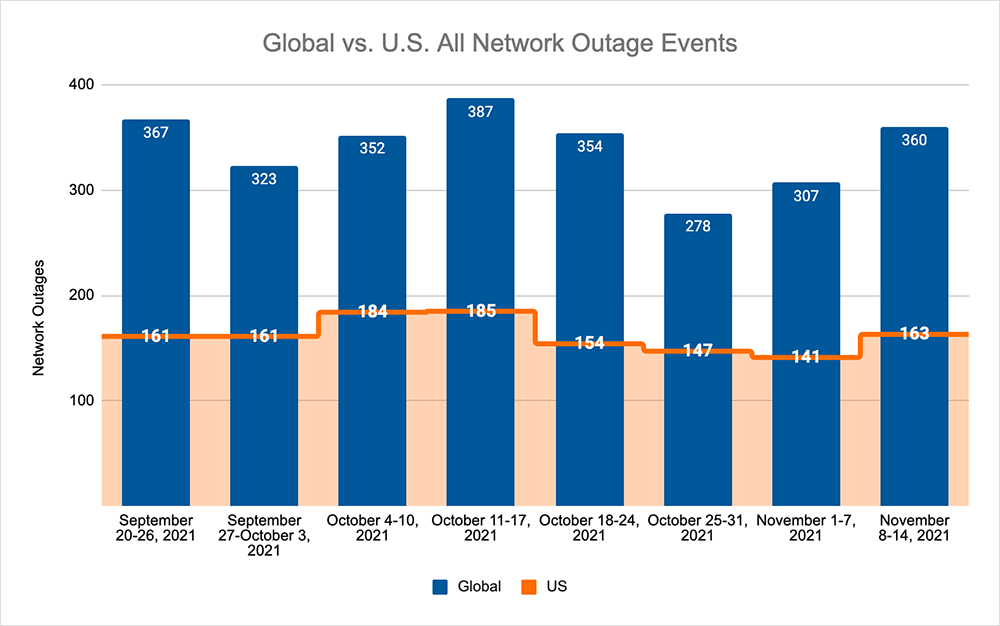
One of the major ISP outages of note observed last week was Comcast Xfinity, which had a distributed impact across a number of U.S. states. Technically, it comprised two outages: the first centered on Comcast backbone network in California, while the second was more widespread with users in Illinois, New York, Pennsylvania, Virginia and other regions impacted.
Outages like this one further highlight the need for reliable information resources that are available in a timely manner.
In the early part of an outage, unofficial sources are often the only ones with any information. We tend to see company social media pages and sentiment-based outage tracking websites cited or used as confirmation sources at this time. The provider’s official outage status page may show no reported issues, or it may take them an hour or more to acknowledge any problems exist, either on their official status or through their social media channels.
The result is often frustration on the consumer side. They can’t find official information, only rumor and speculation. End customers—whether business or consumer—initially may find it difficult to establish if the issues they’re seeing are limited to their own machine, or are the result of something bigger. A range of businesses and other organizations also become collateral damage, when products and services they offer fail because, at some point, whether through a direct or third-party relationship, their service requires use of the connectivity or rails that are out of action. These organizations also pay for lack of communication by the provider involved.
So what can be done?
If you’re experiencing problems and you are unsure of the root cause, and/or your own provider or the application you’re trying to use isn’t showing any issues on its official status page, you can now use Internet Outages Map to check the status independently.
The map is powered by the same collective intelligence data set behind ThousandEyes Internet Insights™ and is based on billions of ongoing measurements across thousands of global vantage points.
As of last week, we added application outages, providing the first live view of business-critical SaaS applications and Internet outages based on actual performance data.
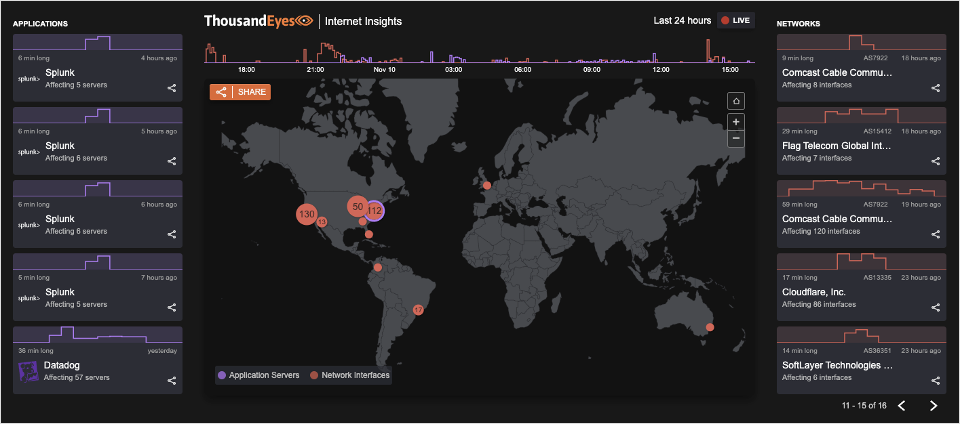
For businesses, this data can help to correlate user-specific issues to broader application issues. Response teams or internal service owners can then escalate to the SaaS provider, potentially before the provider even acknowledges the issue publicly.
Businesses may also wish to add a crosscheck with Internet Insights into the responsibility assignment matrix they use when faced with a potential outage incident. My preferred approach is to apply a RACI model (responsible, accountable, consulted and informed) which can be used to define the roles and responsibilities of people both internally and externally. Providing a clear and concise reporting structure. Ensuring that everyone has the correct focus and visibility when an issue, such as a potential outage, arises. Visibility is, after all, a key input to understanding how to react to or escalate a potential issue.









