


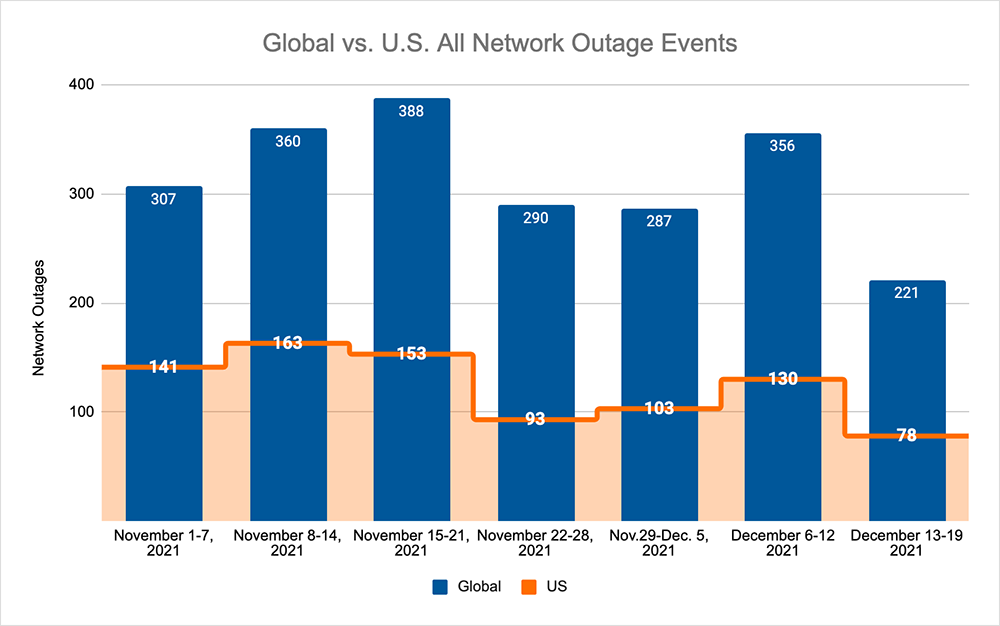
Last week on the Internet, we saw another rise in outage numbers across ISPs, CSPs and UCaaS providers. This week, the outage numbers are lower again. Total global outages recorded a 39% decrease when compared to the previous week, which was mirrored domestically where we observed a 40% decrease in outages when compared to the previous week. That seems likely to continue into the New Year as the brief change window between Thanksgiving and the end of the calendar year wind-down expires, and most companies head into change freeze territory again.
The one complication to this, for some IT and network teams, will be ongoing attempts to patch or otherwise mitigate against the critical Log4j vulnerability. Evidence of specific outages resulting from that emergency work is anecdotal right now, and it isn’t obvious in the outage statistics. However, it is somewhat of an unknown quantity, and it could have an impact going into the year-end period.
For the second week in a row, there were also specific CSP problems to highlight.
An AWS incident on December 15th at 7:15 am Pacific time impacted the US-WEST-1 and US-WEST-2 regions, and the reachability of multiple business-critical applications like Okta, Workday and Slack for up to an hour. ThousandEyes observed packet loss within AWS’ network during the incident, and AWS confirmed that network connectivity issues were responsible for the disruption.
Not long after, ThousandEyes observed an incident impacting users globally leveraging the Azure Active Directory (AD) service. The outage, lasting around 1.5 hours, was first observed at 4:50 pm PT and appeared to impact users around the globe signing in to Microsoft services, such as Office 365. During the outage, authentication requests returned HTTP 503 Service Unavailable errors. Microsoft announced that it had mitigated the issue by rolling over to redundant infrastructure at around 6:25 pm PT, which cleared the issue and restored service availability.
But for the purpose of this blog, I want to focus on the AWS incident and particularly the official explanation:
“The issue was caused by network congestion between parts of the AWS Backbone and a subset of Internet Service Providers, which was triggered by AWS traffic engineering, executed in response to congestion outside of our network. This traffic engineering incorrectly moved more traffic than expected to parts of the AWS Backbone that affected connectivity to a subset of Internet destinations. The issue has been resolved, and we do not expect a recurrence."
From this, it is clear that engineers saw some congestion issues coming in from a downstream service provider. They performed “traffic engineering,” a process to select the paths to carry the traffic, to mitigate it, which appeared to put too much load onto their backbone network, which subsequently caused congestion within their own internal network and temporarily made some services unreachable.
Of course, with TCP retransmission, congestion also then becomes a self-fulfilling prophecy: TCP will naturally retry to send packets, and you quickly get a build-up of traffic that can compound any congestion.
But more than that, this incident shows the effect of the real change in application usage and work patterns that has occurred over the past two years.
As hybrid work arrangements have become standard, we’re now living in a global 24x7 world, where overlapping time zones mean the availability and performance of applications is critical all of the time, not just in more traditional standard business hours.
In our own observations, we see people are active and online for more hours a day. That greatly diminishes the traditional out-of-hours early morning window that would once have been a relatively safe time to perform engineering work.
There really is no “safe” time for this work to happen anymore, and that is going to push network engineering teams to use visibility and intelligence more to inform any changes they want or need to make.
For example, through understanding what paths, nodes or locations are directly affected, it may be possible to mitigate or route around an incident by temporarily impacting performance for a single country or availability zone, if it means keeping the majority of customers—particularly those in (extended) working time zones—online and productive.
On that note, this is the final Internet Report: Weekly Pulse for 2021. The next installment, including a wrap-up of the year-end period, will be published in mid-January. Thank you for your support this year and enjoy the holiday season.








