If there's one thing you can be sure of in the coming year, it's that Internet outages will continue to occur. They're an unfortunate but unavoidable part of today’s interconnected digital landscape and the online services you and I depend on. But what happens when those services go dark?
For many organizations, downtime means damaged revenue, reputation and wasted resources (think hundred person war rooms) responding to incidents. But avoiding or minimizing the impact of these incidents is possible. How? By learning from the experiences of others, which brings us to our rundown of the top seven outages that shook up 2021.
#7: Akamai DNS, July 22, 2021
In late July, Akamai suffered a major outage that resulted in users around the globe being unable to reach their customers’ sites. The outage lasted over an hour and its scope was significant, affecting many websites and applications used in banking, air travel and gaming among others.
Because Akamai DNS is a critical service that directs users to Akamai’s CDN edge, users attempting to browse sites hosted by Akamai received error messages indicating their requested domain could not be resolved to an IP address.
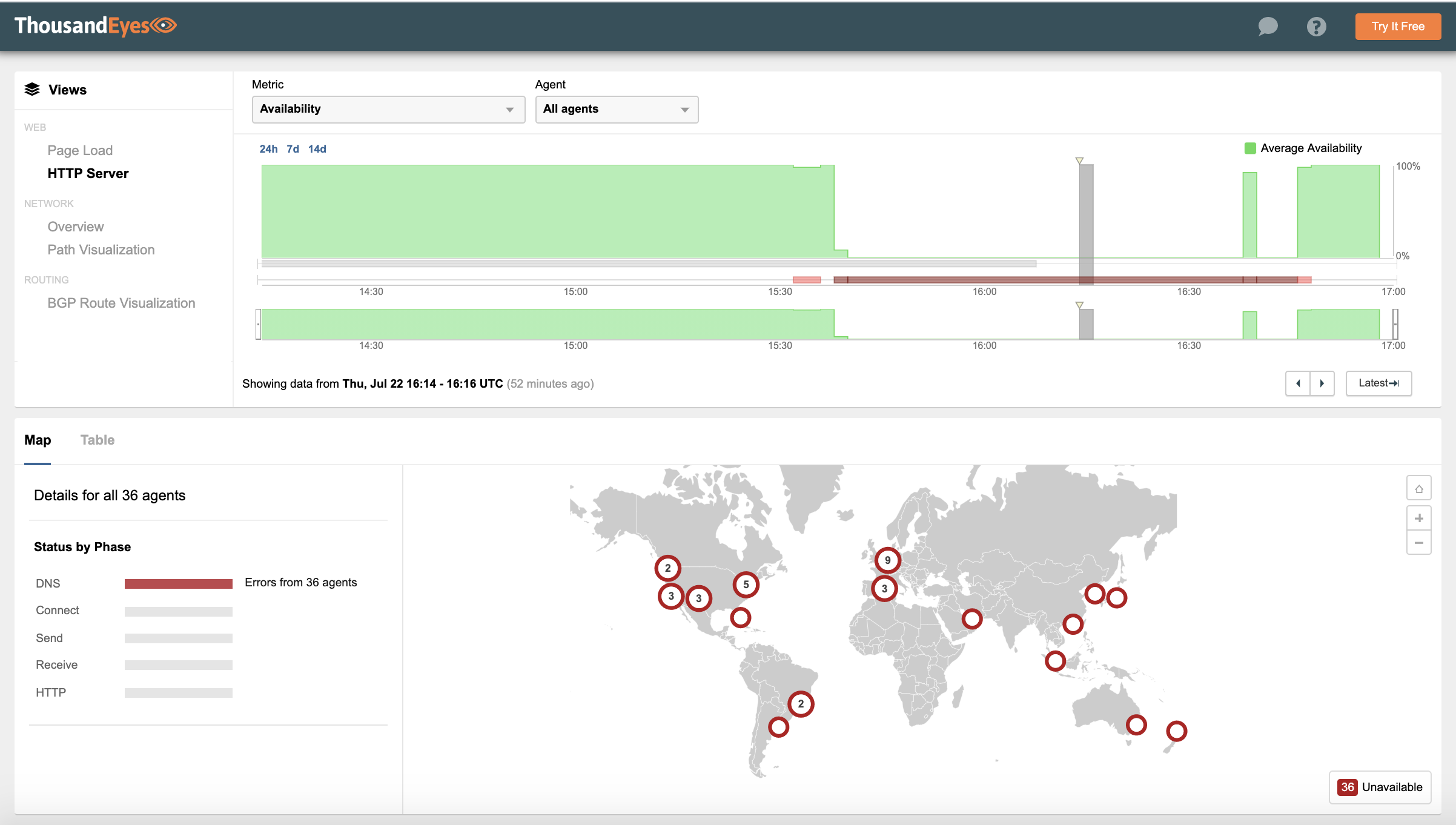
The outage was significant because it affected not only Akamai customers but also those who rely on services served by Akamai. Companies using a multi-CDN approach, like Amazon, were mostly spared the impacts of this incident.
#6: Comcast, November 9, 2021
In early November, Comcast experienced two separate outages affecting its network backbone, impacting millions of subscribers. The first outage occurred at night and affected the San Francisco Bay Area for approximately an hour and forty-five minutes. The second happened in the early morning and affected Comcast customers for over an hour in multiple cities across the U.S.
#5: Akamai Prolexic Routed, June 16, 2021
For those living in Australia and other countries in the Asia-Pacific region, you may remember June 16 as a particularly frustrating day. That is when Prolexic Routed, Akamai’s DDoS mitigation service, experienced a service disruption that rendered some of its customers’ websites unreachable for varying lengths of time.
To protect its customers against DDoS attacks, Prolexic Routed sanitizes incoming traffic by advertising customer prefixes (with permission) before handing it over to their networks. The cause of this incident was an inadvertently exceeded routing table limit. The outage lasted for over four hours, although it was most severe during the initial few minutes. Different services experienced different impacts based on location, time of day and pre-established back-up plans. Some services had failover systems that allowed them to quickly recover connectivity, in some cases, within minutes.
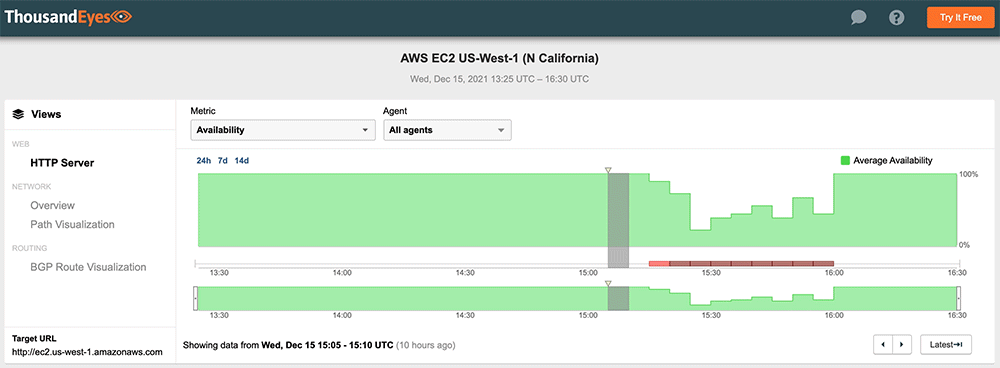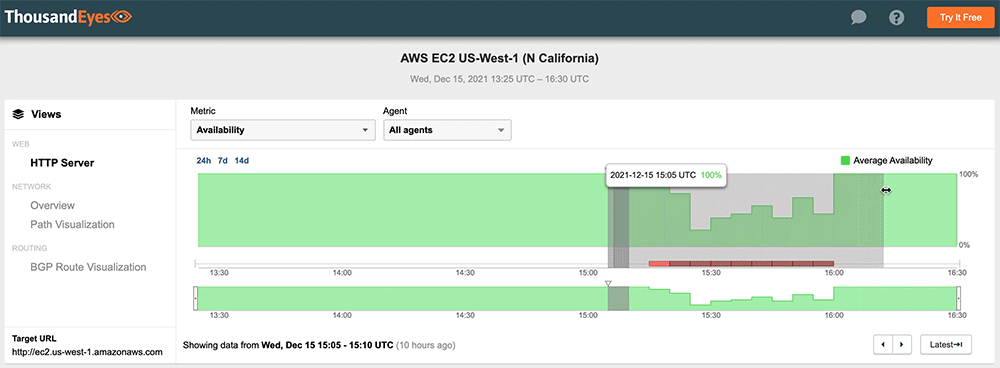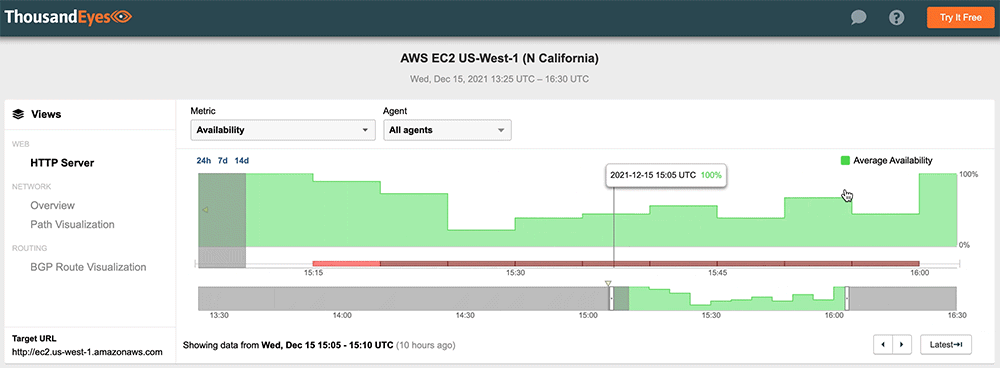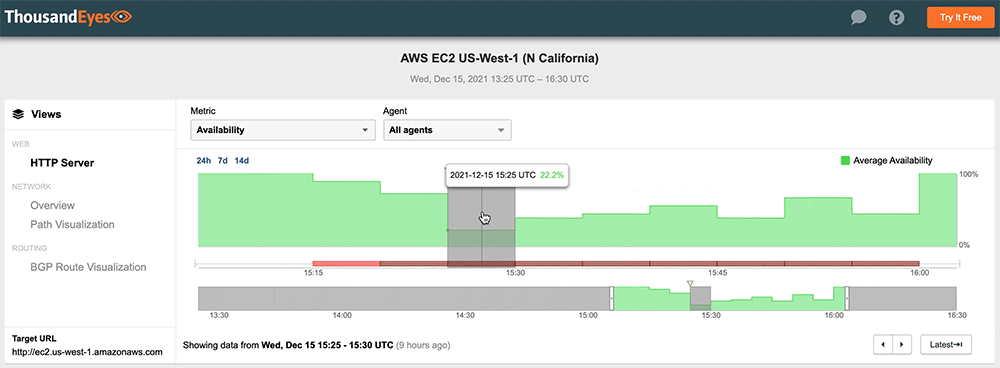
#4: Amazon Web Services, December 15, 2021
A brief Amazon Web Services (AWS) outage affected services and applications in US-WEST-1 and US-WEST-2 regions. The incident lasted approximately 45 minutes but occurred at the beginning of the workday for the West Coast, disrupting the access to authentication and collaboration platforms that rely on AWS, including Okta, Workday, and Slack. AWS confirmed ThousandEyes' observation that network connectivity issues were responsible, namely due to traffic loss caused by congestion.
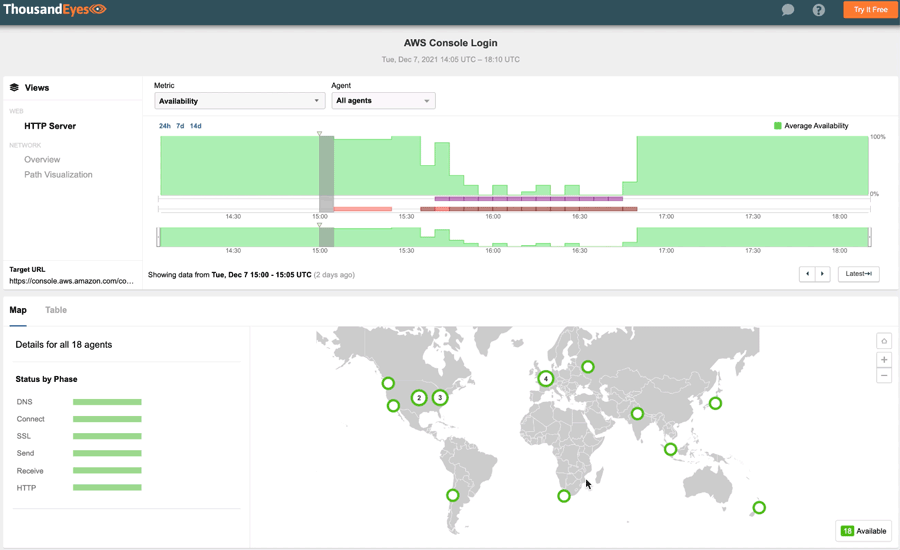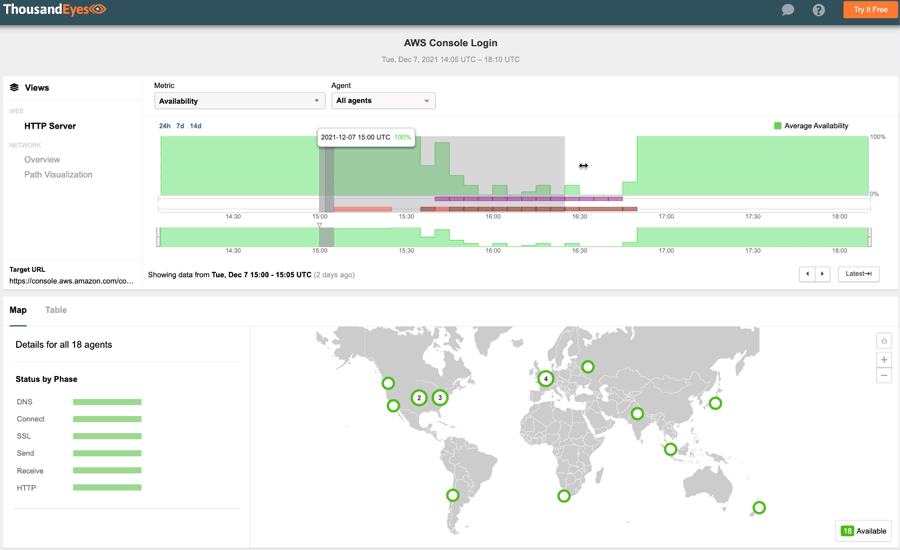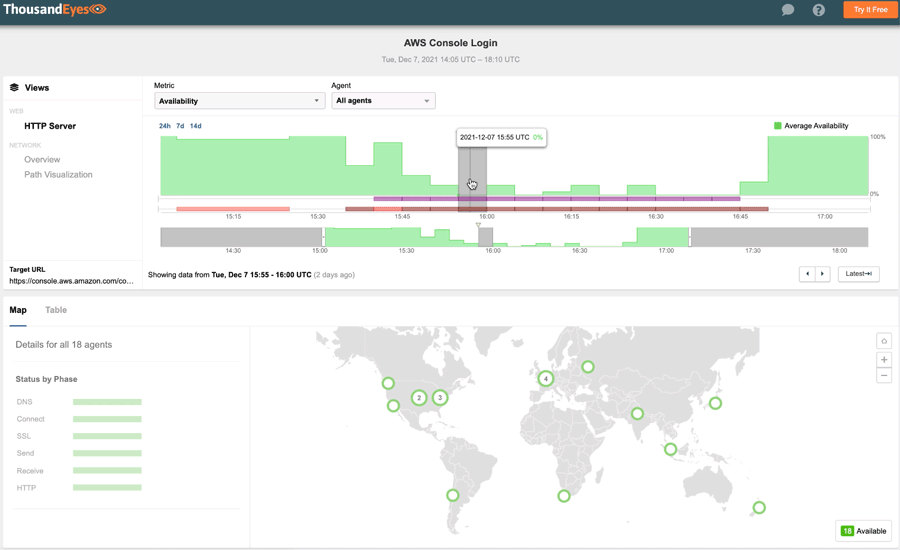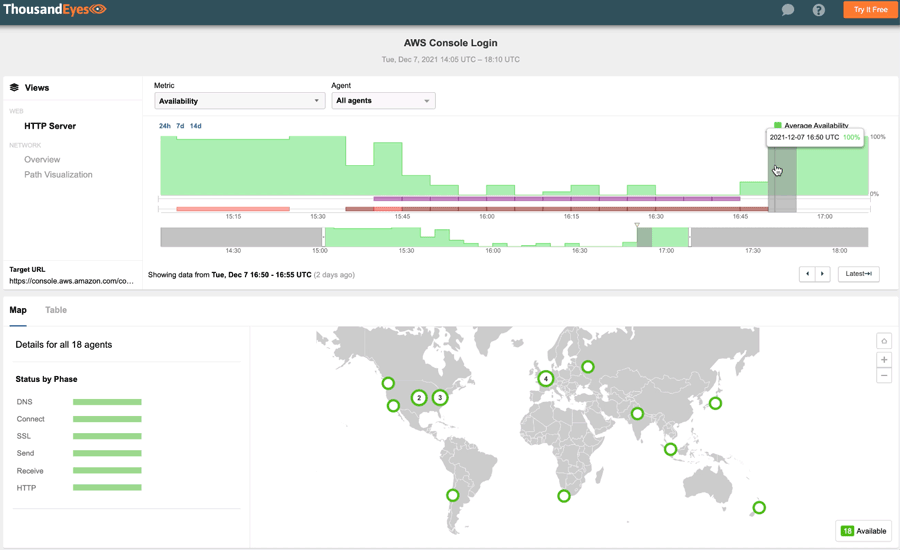
#3: Amazon Web Services, December 7, 2021
AWS, the largest cloud-computing service provider in the U.S., had an even bigger outage in early December. Lasting for over an hour, the disruption caused user-impacting issues across several key services, including AWS Console, Amazon Prime Now, and Amazon Pharmacy. It also impacted many services that rely on AWS, such as consumer IoT devices such as Roomba and Ring. Major streaming services like Disney+ and Netflix were also impacted.
Notably, this outage had a significant effect on the applications and services of its corporate customers, leaving many anxious IT professionals to wait for more than an hour for the vendor status page to reflect the reality of the incident.
#2: Fastly, June 10, 2021
Fastly suffered a massive outage that impacted 85% of its service globally in June. A latent software bug triggered the hour-long outage when a customer performed a routine update to their CDN configuration. Those attempting to reach impacted sites or applications would have likely received a HTTP 501-service unavailable error.
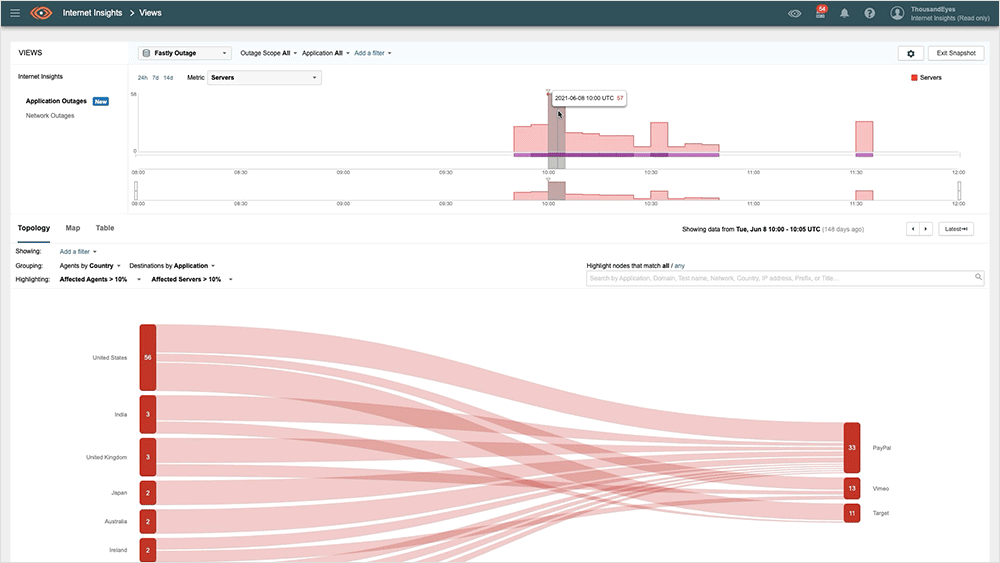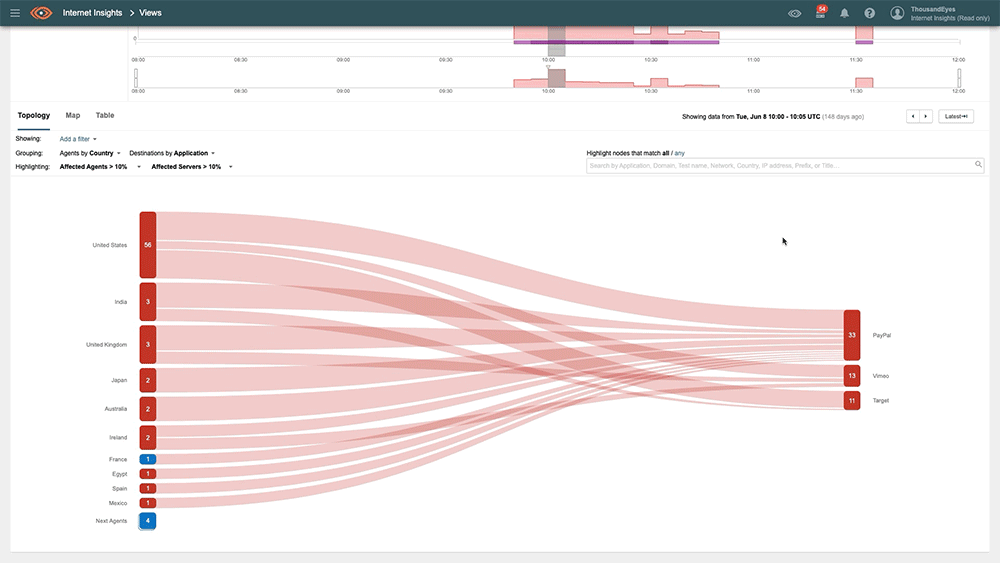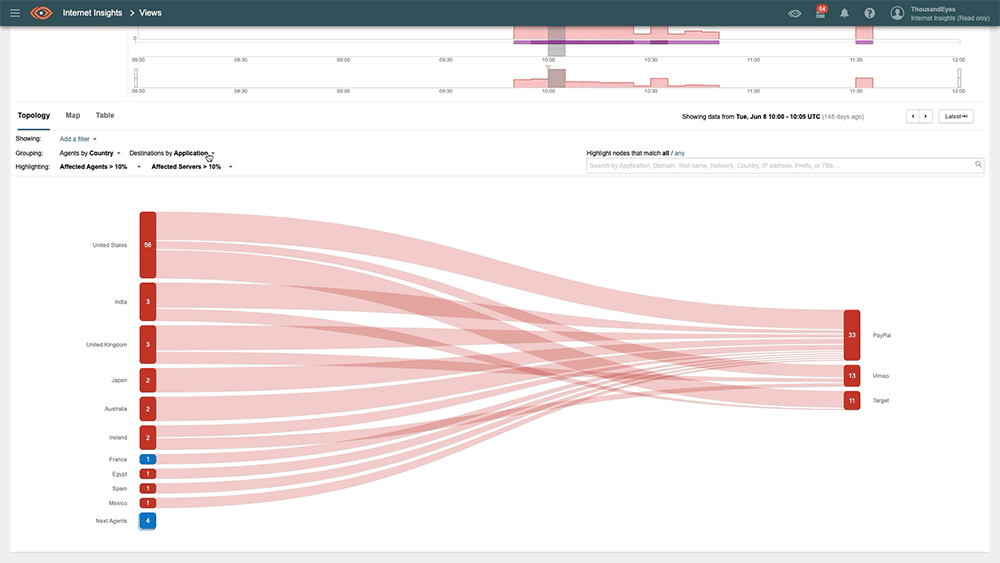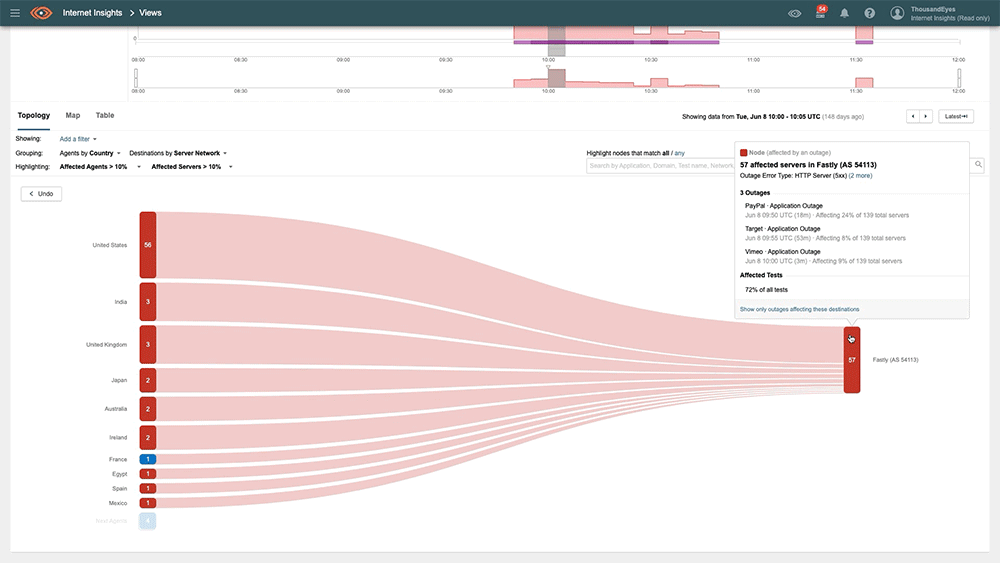
This outage affected many large websites, including Reddit and the NYTimes. Even Amazon and eBay were affected to some degree as they leveraged Fastly's services. Notably, the outcomes for each of these media and ecommerce providers differed significantly despite the source of the incident being the same.
#1: Facebook, October 4, 2021
On October 4, Facebook, Instagram, and WhatsApp unexpectedly went dark. The outage impacted hundreds of millions, if not billions, of users worldwide. And there were also reports of issues with services providers affected because of Facebook's weighty Internet traffic volume.
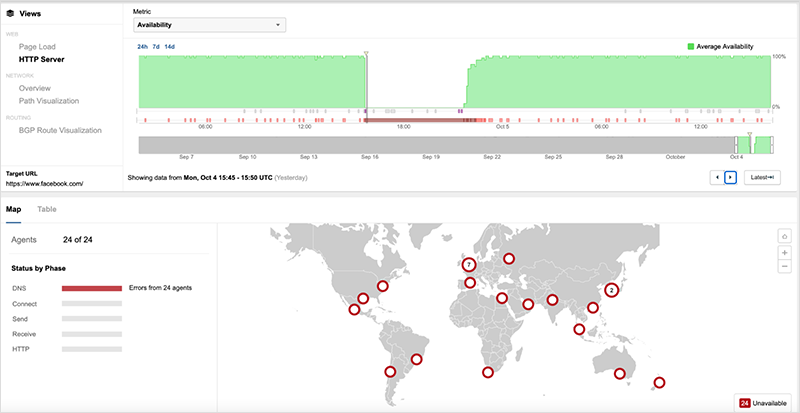
Service was restored to all three messaging platforms seven hours later, raising several questions about how it occurred and why it took so long for the social media company's highly sophisticated network operations team to resolve the issue. The outage was a significant disruption in terms of breadth and duration. It was also a big hit financially. According to Forbes, the outage reportedly resulted in some $60 to $100 million in lost revenue and a $47.3 billion drop in total market cap.
Takeaways for a More Resilient 2022
There are a few recurring lessons we can learn from these outages, which include the following:
Use practical design for redundancy. Consider leveraging more than one provider for critical services such as CDN and DNS.
Understand how your service delivery chain functions. The service delivery chain can rely on multiple dependencies to operate, so understanding all of your dependencies, even indirect or "hidden" ones along with external services, is critical.
Ensure proactive visibility into your sites, apps, and key dependencies. Doing so will provide you with the most efficient approach to identifying when a service issue has occurred and what strategy to execute to mitigate the incident with the least impact on your users.
Build out a contingency playbook. Even if you've implemented best practices and redundant service architectures, you may still encounter unforeseen failures. By having a backup plan to address failure scenarios, you can minimize downtime and performance degradation of your services.
While outages are unavoidable, there are tactics you should have in your toolbelt to get through them unscathed. With these outage learnings, we hope that operations teams can develop better identification processes, redundancies and failover systems to manage and minimize downtime in 2022.





