


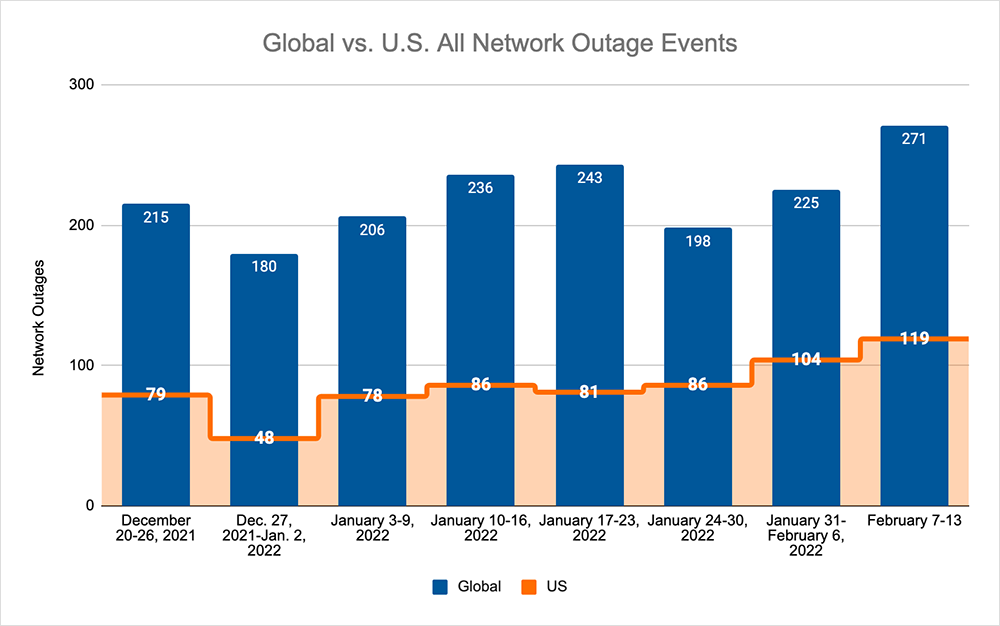
The upward trend observed in late January continued this week, with the total number of outages globally rising from 225 to 271, which is a 20% increase when compared to the previous week. It is also the highest number of outages in a single week observed this year to date. This was reflected in this week's U.S. figures, where we observed a similar upward trend—with outage numbers rising from 104 to 119, a 14% increase when compared to the previous week. With global outage numbers increasing by a larger magnitude than the domestic numbers, U.S. outages only accounted for 43% of all observed outages, which is a 3% decrease compared to the previous week.
While there were no major or significant outages last week, there was a disruption in Europe related to a service update by Microsoft that appears to have taken the Microsoft 365 admin portal offline for several hours on February 3.
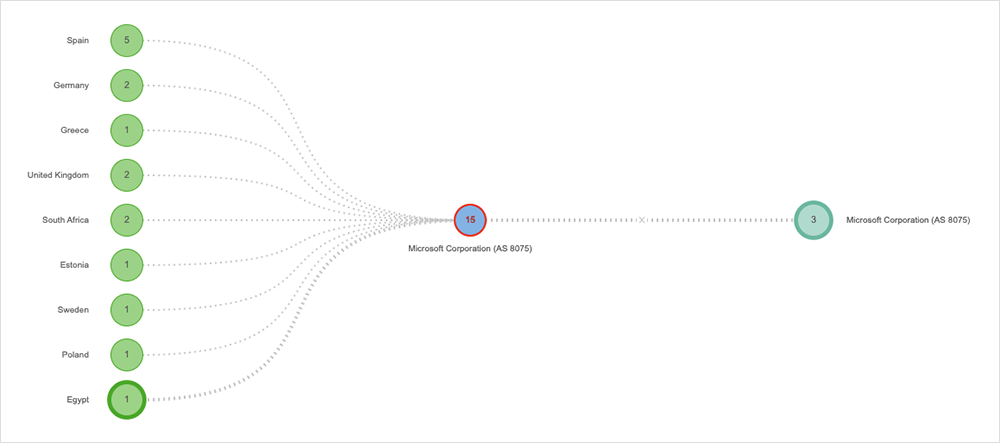
Once identified, the service update was rolled back by Microsoft engineers, and the affected infrastructure was restarted. In an effort to accelerate the recovery, Microsoft then reportedly redistributed user traffic across “healthy infrastructure,” in addition to rerouting some traffic to additional, healthy infrastructure to help expedite remediation time for users.
The impact was limited to the admin portal. As such, Microsoft 365 end users would likely not have seen or experienced any problems, and even administrators may have had workarounds, such as logging in via Azure.
Notably, this incident highlighted a recurring issue in outage scenarios: they’re just difficult to diagnose in the early stages, with official status updates often lagging a bit behind the user-facing impact. Independent monitoring and intelligence services remain a practical go-to.
Administrators are naturally doing more of this diagnosis work. Cloud services are pervasive. As more business-critical workloads are run out of the cloud and application traffic is routed over the public Internet, more organizations are exposed to chains of third-party services and interdependencies.
Of course, things will inevitably break. It’s how prepared we are when we encounter an outage scenario that determines how well we come out the other side: with our internal “license to operate” in the cloud intact or in tatters.
There are many different ways that cloud and infrastructure teams insulate themselves against the potential for downtime.
We’ve touched briefly on monitoring and intelligence, but to reinforce the point: administrators need a complete view of their end-to-end service delivery chain to understand the broader impact of an outage and how users are experiencing the issue. You have to know who is responsible to chase for rectification and communicate transparently with your users what’s wrong and when it might be fixed.
Methodologies and practices, such as site reliability engineering (SRE), may also help insulate an organization from the effect of an outage, or at least mitigate against its effects. In the age of agile software development and DevOps, more software updates are pushed to production more often. Even with the best QA baked into developer pipelines, unforeseen breakages and dependencies on third-party APIs are always a threat.
Take it from Google: “million-to-one chances happen all the time.”
But even smaller organizations find themselves in much the same boat: the complexity of the environments used to serve business applications and data is now enormous, especially when compared to their relative organizational size.
The challenge for smaller organizations is that the negative impacts of an outage may be harder to ride out. Larger enterprises have larger teams and bigger budgets. They have the means for industrial-scale responses: to run multi-cloud or single cloud but in multi-region setups, and can, for example, route around an issue located within one region or one cloud. Even when all mitigation options are exhausted, you’d expect most big enterprises to be able to ride out the impacts of an outage.
Previous research by the insurance marketplace Lloyd’s supports this: it shows that businesses outside the Fortune 1000 “would carry 63% share of economic losses” from a major cloud meltdown. This is based on a rather extreme scenario that took out crucial cloud infrastructure for days, but it highlights the issue of insulation, and in particular that the cost isn’t evenly spread.
None of this is discouraging smaller companies from being in the cloud or embracing cloud-based services, of course, and they do so in large numbers and mostly with a good understanding of the risks. Their mitigation mix will simply look different to larger organizations.
That being said, the ongoing asymmetry between large and small business’ response is driving the emergence of some interesting experimental business models, such as downtime insurance, that might help insulate businesses from lost revenue or other incurred costs. Like all emerging areas in technology-related fields, only time will tell as to their efficacy, relative to other available options.
Realistically, the fundamentals of dealing with the risk of an outage are unchanged.
The best way to insulate oneself against the impact of outages is real-time visibility of what is happening on the Internet at any given moment, in-depth visibility into the end-to-end digital delivery of applications and data, and a regularly tested “digital disaster recovery” and business continuity plan.









