


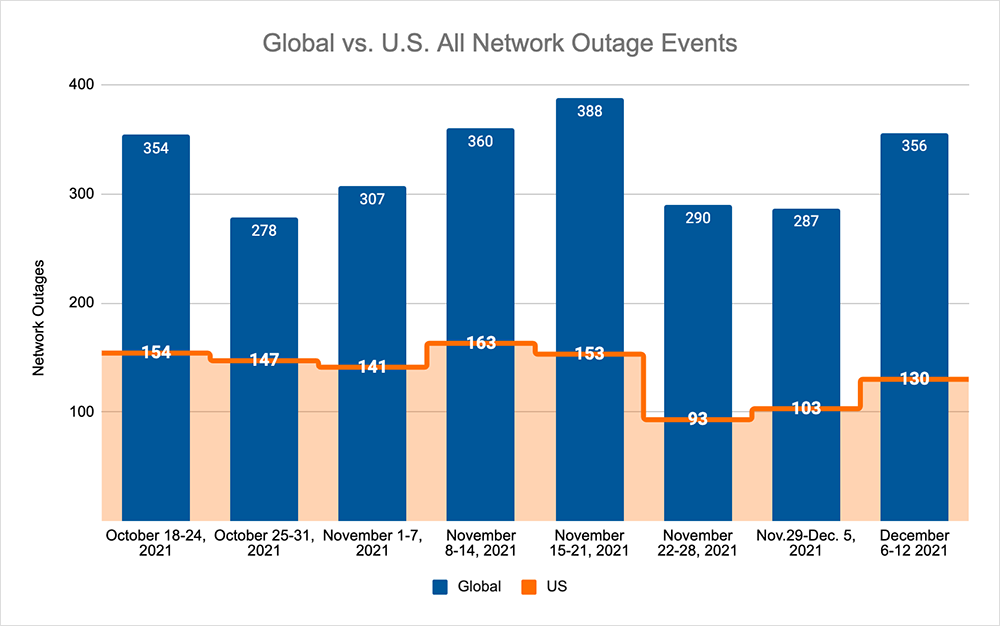
This week marked the return of Internet outages after a fortnight-long hiatus due to the Thanksgiving holiday and the lifting of network change freezes that appeared to be in effect during the period.
Across the board, we saw increases in our tracking of outage numbers, with global total outages increasing by 24% compared to the week prior. This was reflected domestically, where outages increased by 26% relative to the previous week and increased by 40% compared to the Thanksgiving holiday week, which is in line with what we expected following what looked to be an enforced quiet period.
This week, we also saw the first major outage in a number of weeks as Amazon Web Services (AWS) experienced problems with some of its services, which were impacted by network congestion in the US-EAST-1 region, resulting in latency and failures in accessing services.
US-EAST-1 is traditionally important to the technical operation of many AWS services, and in this event, as with others before it, we observed broader impacts to users in EMEA and APAC, even though the incident took place in North America.
A detailed analysis of the outage can be found in the ThousandEyes blog, but it’s worth unpacking a few things about this.
Firstly, AWS’ cloud services operate as a full-suite; that is, multiple layers of services can be stitched together to power a workflow or to create an entirely new product or service. AWS uses APIs to connect all of the different services in the platform together, allowing information to be exchanged between all these underlying services so that the overarching system can function.
Each of these underlying services and APIs represent critical interdependencies—that is, if one breaks, it can have a cascading effect on others, while also rendering the overall system unusable. As my colleague Angelique Medina told Reuters, “AWS's complex services are often built on top of its own more basic services. One problem that crops up with a basic function like networking can cascade through services that depend on it.”
According to Amazon, it was an automated activity to scale capacity of one of the AWS services hosted in the main AWS network that triggered the event. This resulted in wide scale congestion on the AWS internal network, which in turn impacted multiple APIs connectivity performance. This broke the connective tissue between critical parts of various services. The individual services themselves remained online, but network connectivity issues prevented some AWS service access, including management functions (e.g., scaling EC2 or S3) for some users.
That then broke a lot of customer-facing things. As CBNC noted, “robotic vacuum cleaners couldn’t be summoned. Whole Foods orders were suddenly cancelled. Parts of Amazon’s mammoth retail operation slowed to a standstill.”
What appeared to tip end users over the edge, however, was that the AWS Service Status page showed no specific issues for nearly an hour.
Regular readers of this blog may recall that we’ve previously covered the topic of service status pages, specifically that problems experienced by users may not be reflected in official status updates, or may only be reflected after an extended period of disruption.
I don’t intend to repeat much of that, but suffice to say our advice is still the same: having your own independent visibility into the formation of issues is substantially valuable in outage scenarios. Anyone that had independent monitoring in place could have been well ahead of those relying on the official AWS status page in this instance.
Generally speaking, users can sometimes feel that vendor-specific status pages aren’t updated in a timely fashion. Status pages also only provide a limited view—not the complete service delivery chain, which is needed to understand the broader impact and how users are experiencing the issue. Ultimately, this is why the onus is on users to have an independent holistic view of all of the elements and interdependencies required for end-to-end delivery of their product or service.









