


Demand for cloud and next-generation wireline and wireless services is driving the rollout of hundreds of millions (to even billions) of dollars in investment in both lit and unlit fiber capacity. As more telecommunications infrastructure—particularly deep fiber—is deployed, networks are expanding in size and complexity. With an increase in links, connections and interconnections, there are more potential points of failure or breakage. One might, therefore, reasonably anticipate an increase in outages occurring in the future.
We’re already seeing this play out with cloud service providers (CSPs), which are increasingly marketing their growing telecommunications networks and partnerships for additional capacity access as a point of differentiation.
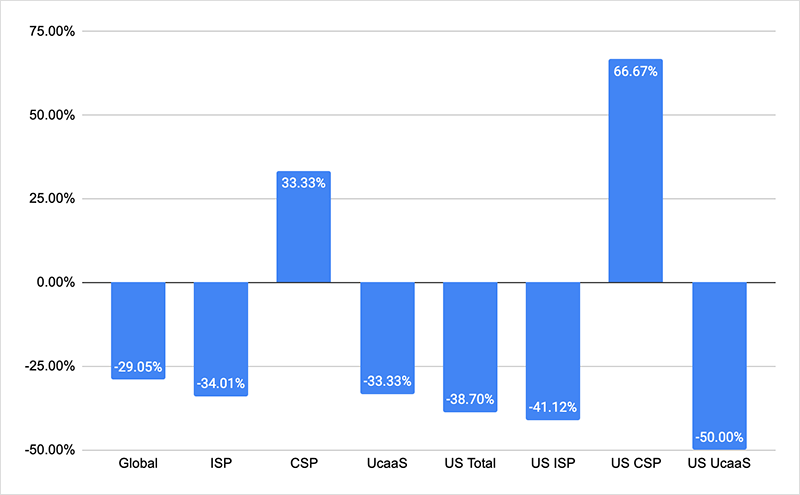
Despite this push for capacity, we have seen a 66% increase in the number of CSP network outages in the US since the beginning of October. Yet, there were no substantial public-facing glitches.
So what exactly are we looking at?
Many CSP “outages” this week exhibit the behavioral characteristics of maintenance work, which are notably short in duration and with limited to no public impact felt. The maximum outage duration was 25 minutes, but the average was only 3 to 4 minutes long.
Despite having some of the characteristics of planned maintenance, the causes of these outages could just as easily have been from unscheduled outages that, due to the way the network is architected and managed, are picked up and remediated much faster.So, a series of three-to-four minute outages could also lend itself to automated corrective action taking place: the kind of action that could be attributable to a software-defined network (SDN) with self-healing capabilities.
Scale Challenges
It comes as no surprise that investing in networks is the single most effective way to reduce the impact of network-related downtime. And this is exactly what the CSPs are doing. CSPs are growing the reach and depth of their network infrastructure and have an expanding cable footprint in the world.
While this means more interconnection points and more dependencies, they are architecting their networks to be software-defined, with multiple diverse routes for failover and resiliency, and automatic triggers to move traffic around scheduled or unscheduled issues.
As network architectures become more software-defined, we won’t necessarily see fewer outages; in fact, it potentially increases the risk with the added requirement behind aspects such as configuration changes, software and patch updates, etc., but we will more often see the “blast radius” (the impactable area) for these outages drastically reduced. Where outages are highly localized, segmented far away from the core and lower in duration because they are easier to work around.
While CSPs are in investment and network scale-out mode, we expect to see a continuation in the volatility of their weekly outage numbers—and a mid-term trend towards more outages occurring. If I look at the number of CSP outages on a yearly rather than weekly basis, I see something in the region of a 280% increase in terms of absolute numbers, and this has been a trend as we’ve progressed across 2021.
This is not an indictment of some relative instability of CSP networks over any other type of network, or of one type of provider being more adept at network management than another. It’s simply a by-product of the surging footprint of CSP networks, which requires more maintenance (resulting in more scheduled outages) and introduces more potential points of failure or dependency (resulting in more unscheduled outages).
But as these networks continue to be built out and bedded down, and the self-healing aspects of network monitoring and management are optimized, it may be that these outages can be better managed to a point where they are barely perceptible—even less so than they already are.








