Cisco ThousandEyes actively monitors the reachability and performance of thousands of services and networks across the global Internet, which we use to analyze outages and other incidents. The following analysis is based on our extensive monitoring, as well as ThousandEyes’ global outage detection service, Internet Insights.
Outage Analysis
Updated October 31, 2025
On October 29, Microsoft Azure Front Door (AFD) experienced a widespread service disruption when a configuration change caused nodes across the global fleet to fail to load properly. Starting around 3:45 PM (UTC), services experienced failures that Microsoft addressed by rolling back the problematic configuration.
This analysis explores how ThousandEyes monitoring data revealed the cascading impact of configuration failures in cloud infrastructure—and why geographic redundancy couldn't protect against this type of outage.
Explore the outage within the ThousandEyes platform (no login required).
The Initial Problem and Challenge to Redundancy Strategies
Before diving into what happened on October 29, it's important to understand how cloud resilience typically works and why this incident was different.
Cloud architectures are built with redundancy at every layer. Services deploy across multiple availability zones or regions, creating physical and logical separation with different power supplies, network paths, and hardware clusters. This geographic redundancy provides powerful protection against infrastructure failures. If one availability zone loses power or hardware fails, traffic automatically routes to other, healthy zones.
Configuration failures, however, represent a fundamentally different type of risk. When every node globally receives its operating instructions from the same configuration management system, and those instructions become corrupted, geographic redundancy provides no protection. The fault domain—the set of components that can fail together—isn't bounded by geography. Rather, it's the configuration system itself, that all infrastructure shares.
Think of it this way: You can have servers in ten different countries, each with independent power and networking. But if they all receive their operating instructions from the same source, and those instructions become corrupted, all ten locations can be impacted despite being geographically redundant.
This distinction between infrastructure failures and configuration failures would prove critical to understanding the October 29 incident.
A Scattered Pattern Emerges
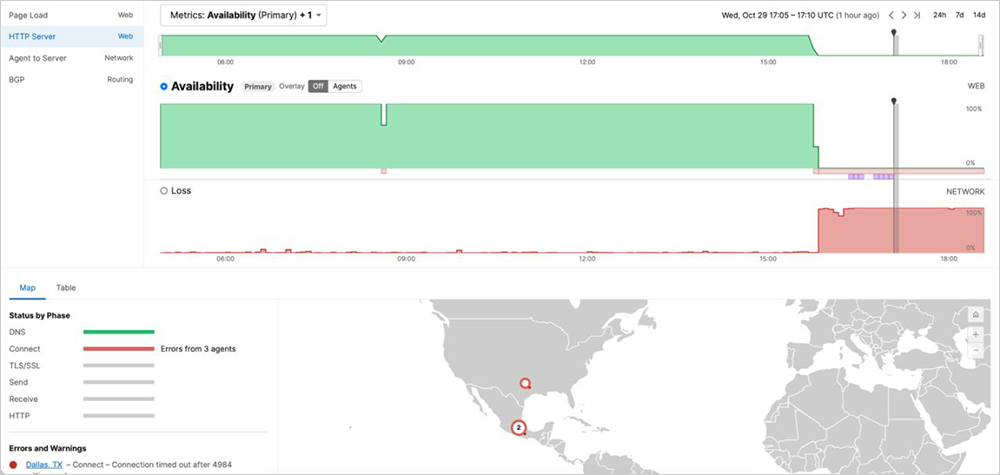
Beginning around 3:45 PM (UTC) on October 29, ThousandEyes monitoring detected failures across services relying on AFD, Microsoft's global edge and application delivery platform. The geographic distribution of the failures provided a first and critical diagnostic clue.

Unlike other cloud outages that often have clear regional boundaries (like an AWS availability zone failure or a submarine cable cut affecting a region), this incident showed seemingly randomized impact. Some tests in Asia-Pacific succeeded while nearby locations failed; some tests in the Americas failed while others succeeded. There appeared to be no geographic logic behind which locations were affected.
This lack of regional patterns presented immediate significance. Infrastructure incidents like power outages, network partitions, or hardware failures almost always show geographic clustering because they affect all services in a physical location together. The scattered distribution here suggested something different: a problem affecting individual nodes regardless of their physical location.
Understanding the Failure Modes
When examining the technical details of failed tests, two distinct trends emerged:
Some tests were canceled within approximately 10 milliseconds of connection attempts. This "immediate cancellation" response is significant because it indicates connections were being actively refused or reset at the edge, rather than timing out due to routing issues or failing due to backend problems.

Other tests took longer to fail, timing out after several seconds or returning HTTP 503 Service Unavailable errors. These server-side error responses indicated that requests were reaching AFD's edge infrastructure, but the edge nodes themselves were unable to successfully process and complete the requests.

The presence of both immediate cancellations and longer timeouts suggested different failure states across AFD's infrastructure. Some nodes were actively rejecting connections, whereas others appeared to attempt processing before ultimately failing.
What the Pattern Told Us: Narrowing the Fault Domain
Before drawing conclusions about what was likely causing these failures, it's important to understand what the observed patterns appeared to rule out. Based on the geographic distribution and failure mode trends, one could deduce that this was:
- Inconsistent with regional infrastructure issues: The scattered global distribution—with no geographic clustering of failures—was not consistent with patterns typically seen in power failures, network partitions, or data center issues that are typical causes of regional outages. Infrastructure problems affect all services in a location together and establish clear geographic boundaries.
- Not primarily a network transport issue: While some service disruptions manifested as DNS resolution failures and connection problems, the specific trends observed suggested this was not a systematic network transport issue, as the reachability to Microsoft's edge infrastructure (AS 8075) was intact. The DNS and connection failures appeared to be symptomatic of AFD's application-layer problems—as opposed to systematic routing, peering, or connectivity issues affecting the network path itself.
- Occurring at the edge rather than backend: Tests were failing immediately at the first point of contact with AFD infrastructure, before requests could even be routed to origin servers. This pattern suggested the failures were happening at the edge nodes themselves rather than in services behind AFD.
- Different from typical capacity degradation: Healthy services experiencing capacity problems typically show gradually increasing response times, intermittent 502/504 errors, or queue delays. The immediate connection cancellations and resets observed here indicated that nodes were not overloaded but rather, were refusing connections outright.
When you observe these characteristics together—scattered global distribution, application-layer failures at the edge, and immediate connection refusals—the evidence points toward a problem with how the edge nodes themselves were operating. This suggested a configuration issue that might have been affecting individual nodes' ability to process traffic correctly.
Comparing to October 9: Different Patterns, Different Problems
This wasn't the first Azure Front Door configuration incident in October 2025. Just three weeks earlier, on October 9, AFD experienced a different outage that Microsoft attributed to erroneous metadata propagating through the system. (To learn more, listen to our overview on The Internet Report podcast.)
ThousandEyes monitoring of the October 9 AFD incident revealed distinct patterns:
- Geographic concentration: Europe and Africa were primarily affected.
- Regional boundary: The outage impacted about 26% of AFD infrastructure in those specific regions.
- Clear fault isolation: Other regions remained largely unaffected.
The October 29 incident looked completely different:
- Global distribution: Failures were scattered worldwide.
- No regional boundary: Individual nodes failed agnostic of location.
- Node-level granularity: Physical neighbors of affected AFD points of presence remained healthy.
These differences in failure characteristics would prove diagnostic. The hallmarks of the October 9 incident suggested a regional metadata or control plane issue that respected geographic boundaries. Evaluation of the October 29 incident traits continued to point to a global configuration push that caused individual nodes to fail based on their local state and create a scattered pattern across the entire fleet.
Understanding where these characteristics diverge also helps explain why geographic redundancy could limit the October 9 impact yet not provide protection during the more recent incident.
Microsoft's Response and Confirmation
Microsoft began initiating rollback procedures around 4:00 PM (UTC). Recovery occurred progressively over the following hours as configurations were reloaded, and traffic was rebalanced globally across nodes.
Microsoft's preliminary incident report confirmed what the monitoring data suggested, indicating that an inadvertent configuration change triggered the problem.
The report validated the key observations from ThousandEyes:
1. A configuration change was pushed to AFD's global control plane.
2. This configuration caused nodes across the fleet to fail to load or operate correctly.
3. The fix required rolling back to the previous working configuration.
4. Recovery involved progressive restoration across individual nodes.
Microsoft's incident report also noted specific mitigation steps including failing the Azure Portal away from AFD at 5:26 PM (UTC) to restore management access—thus addressing the "bootstrap problem" where the primary tool for managing Azure infrastructure was itself affected by the AFD failure. At 12:05 AM (UTC) on October 30, Microsoft confirmed mitigation of AFD impact for its customers.
The report explained why issues persisted intermittently for hours: Microsoft specifically noted that as recovery continued, some requests might still land on unhealthy nodes, leading to intermittent failures or reduced availability. This phased, node-by-node restoration process was necessary to prevent overwhelming newly recovered nodes with traffic surges.
The Cascading Impact: When Dependencies Fail Together
What made this incident particularly impactful wasn't just the AFD failure itself, but also the cascade of services that depended on it. Microsoft's incident report listed affected services including Azure Portal, Microsoft Entra ID (identity and authentication), App Service, Azure SQL Database, Container Registry, and many others.
Since the outage also impacted the Azure Portal, engineers couldn't fully rely on the portal (their primary management interface) to help them diagnose and mitigate the issue. Microsoft's report confirmed they had to fail the portal away from AFD to restore full management access for response teams.
The incident report also revealed secondary effects. As unhealthy nodes failed and dropped from the routing pool, their traffic was redirected to remaining healthy nodes. This sudden traffic surge stressed many surviving nodes, causing further latency and errors even for connections reaching ostensibly "healthy" infrastructure.
This is why recovery processes for this type of outage require careful orchestration. Microsoft's phased recovery approach was necessary to avoid overwhelming nodes as they came back online. During this extended restoration period, user requests could still randomly land on nodes that hadn't been fully restored, resulting in intermittent errors even as overall service health improved.
Key Takeaways: Lessons for NetOps Teams
This incident revealed several important characteristics of distributed infrastructure, shared dependencies, and incident response strategies for enterprise network operations (NetOps) and infrastructure planning teams:
- Failure Patterns Are Diagnostic: Geographic distribution and timing of failures provide important clues when troubleshooting incidents. Observing where failures occur, when they started, and how they propagate helps narrow the investigation. Assessing the combination of regional pattern, failure mode (timeouts, resets, errors), and network location (DNS, edge, backend) where delivery chain problems manifest helps systematically rule out potential causes. No single observation definitively identifies root cause, but comprehensive visibility across the service delivery chain enables faster fault domain identification and more effective response.
- Hidden Dependencies Create Cascading Failures: This incident exposed how many critical services, including Azure's own management tools, are dependent on AFD. When AFD failed, these dependencies created a cascading effect that extended far beyond AFD's direct customers. Microsoft's report also revealed how technical dependencies amplified the impact: Failing nodes created traffic surges on healthy nodes, which then struggled under the unexpected load. Understanding these dependency chains—both architectural and operational—is critical for risk assessment and incident planning.
- Configuration Is a Critical Fault Domain: When infrastructure fails, fault domains are typically bounded by geography—if a data center loses power, typically only services in that data center are affected. But when configuration fails globally, the fault domain spans the entire fleet regardless of geographic separation. Modern cloud architectures have redundancy at every infrastructure layer: multiple data centers, availability zones, regions, and network paths. Yet a flawed configuration pushed globally can affect every redundant node simultaneously, making geographic redundancy ineffective. This highlights why robust configuration management, staged rollouts, and rapid rollback capabilities are essential—geographic redundancy alone cannot protect against configuration failures that propagate globally.
Previous Updates
[October 29, 2025, 12:30 PM PDT]
Starting at around 15:45 UTC on October 29, Cisco ThousandEyes began observing a global issue affecting Microsoft Azure Front Door (AFD), the content delivery network (CDN) that serves as the entry point for many services such as Microsoft 365 and Azure cloud management portals. ThousandEyes detected HTTP timeouts, server error codes, and elevated packet loss at the edge of Microsoft's network, preventing successful connections to affected services and frequently timing out or returning service-related errors. The outage is still ongoing.
Explore the outage within the ThousandEyes platform (no login required).