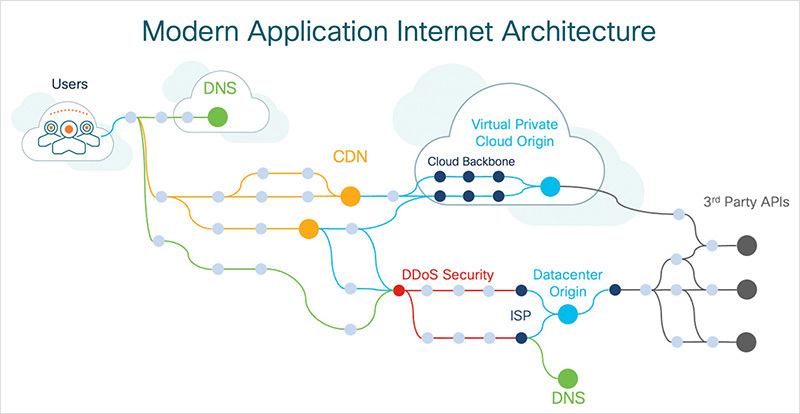
Even the most straightforward application today can be remarkably complex, interlacing several major components in its path to the end user. On its way to delivering digital services to your customers or employees, applications will traverse a modern app architecture that—at a minimum—depends on the Internet and DNS to get started, CDNs and data centers to push and pull information, DDoS mitigation services for security, and third-party networks for a host of microservices. All of which need to function seamlessly to deliver the quality experience that keeps employees productive and customers satisfied.
Dependencies in Unknown Places
Over the next three years, developers will create 500 million applications, according to market researchers, though not all will be consumer-facing. Furthermore, these future apps will be increasingly multifaceted and have more dependencies on APIs than ever before. To put this into perspective, consider that an application today uses an average of 15 APIs, and the average enterprise manages 367 APIs.
Learn more in our eBook "Overcoming API Complexity: How to Assure Modular and Distributed Applications"
But the challenge moving forward for digital businesses is not simply a matter of API quantity. Apps also work with APIs spread across multiple environments, with hybrid, multi-cloud, and inter-data centers becoming the industry norm. Moreover, the ways in which end users gain access to these environments have also grown more diverse and global following the onset of the pandemic and the rise of hybrid and remote work.
With so many factors at play, understanding app dependencies has become a top concern among technical professionals. But dependency awareness is only the first step in a sequence of operational processes that have reformed to address issues affecting end users in a cloud-native world, such as service delivery slowdowns due to suboptimal edge routes.
Show Me the Evidence
Gone are the days when “find-and-fix" was a feasible operational process for network and application delivery optimizations. Little by little, organizations have opted to trade some visibility and control over their IT environments in favor of faster app development with greater resiliency and lower hosting costs. As a result, today’s digital business cannot simply see inside or take control over the networks and infrastructure that belong to the external providers they depend on for service delivery.
In its place is a more modern operational approach known as “evidence-and-escalate.” It is grounded in the principle that troubleshooting issues with cloud and other third-party providers can be much more effective when IT teams proactively bring forward performance data that isolates and visualizes where issues within the providers’ infrastructure are causing disruptions.

Global Visibility Down to the Local Level
ThousandEyes helps digital businesses see, understand, and improve the quality of digital experiences to keep employees productive and customers satisfied. ThousandEyes Cloud Agents are pre-provisioned and distributed globally across hundreds of cities—from San Francisco to Tokyo—to help you troubleshoot service delivery issues down to the local network. Cloud Agents also provide excellent vantage points for instant insights into multi-cloud infrastructure.
With ThousandEyes, your digital business can get end-to-end visibility into the fast-growing parts of your network—the ones your enterprise does not own—as if it were your own. The result: lower meantime for troubleshooting your application delivery issues with less finger-pointing. ThousandEyes customers hold power in their ability to show time-frame-specific and interactive data about service delivery performance to vendors via ShareLinks™—streamlining the elevation process with one click. And with easy integration with AppDynamics, you can eliminate visibility gaps to delivering optimal digital experiences.

Want to see a use case and demo? Sign-up and view our ThousandEyes webinar “Assuring Modern Cloud Architectures for Optimal Application Delivery.” In it, presenters Ian Waters, Senior Director of EMEA Marketing, and Tim Hales, Senior Solutions Engineer, walk you through a real-life threefold latency dilemma that occurred following a ThousandEyes customer’s network migration from their data center to AWS. How was the problem isolated, escalated, and resolved? You will have to watch the webinar to find out.
Making Fast Sense of Complexity
How ThousandEyes capabilities improved our customer’s outcomes is no secret, though. Operationalizing our monitoring solution, they made sense of the complex web of Internet dependencies affecting their application delivery fast. They then resolved the issue with the certainty that only baseline performance data and hop-by-hop path visualization can provide.









