ThousandEyes provides unmatched visibility across the Internet, helping organizations around the world see, understand, and improve digital experiences everywhere. Our global vantage points are an important part of how we deliver this unique view into the digital supply chain. We have three types of agents—Cloud Agents, Enterprise Agents, and Endpoint Agents. In this blog, we’ll examine how our team approaches the location selection and deployment of new Cloud Agents to ensure they collect quality data for our customers.
When we consider adding a new Cloud Agent vantage point, we know that we can’t just deploy it anywhere. We need to ensure that the quality of the data that we collect meets certain standards to ensure customers receive a strong signal that represents what users in that area experience. Whether it’s in the cloud or in physical networks, we focus on highly available and reliable sites that can consistently provide the data our customers need. One of the key areas that we focus on is the quality of the network our Cloud Agents reside on.
To achieve the level of quality our customers demand, we perform extensive validation tests using the ThousandEyes application itself. We perform validations over a long period of time prior to releasing new Cloud Agent vantage points so that we can catch patterns that may be intermittent or cyclical.
These tests fall into two categories: Agent-to-Agent (A2A) and Page Load tests. For both IPv4 and IPv6, we utilize both Transmission Control Protocol (TCP) and User Datagram Protocol (UDP) A2A tests from and to seven different locations spread around the world and five Page Load tests targeting five major websites that vary depending on the geographic region.
On A2A tests, we look for routing issues, packet loss, high latency, and high jitter. For Page Load tests, we also look for high Domain Name Service (DNS) time, high Secure Sockets Layer (SSL) time, and high wait time, among other things. We compare these results to our baselines and address outliers with our vendors. We also look at the path visualization and network information to make sure that we are covering the network paths we expect.
With these validation tests, it is common to find routing issues to a specific region or location, router misconfigurations, and other issues that need to be addressed before we can release a new vantage point to our customers. We work with Internet and service providers around the globe to address issues both at our sites as well as larger routing issues—some of which have gone unreported until ThousandEyes develops a presence in those areas and generates this data.
Recently, we launched ThousandEyes Cloud Agents in all currently available AWS Wavelength Zones. Because this was our first deployment in what was a relatively new service for Amazon Web Services (AWS), we did extensive testing over many weeks to ensure the network quality was in line with what our customers would expect. From that testing we identified an issue with Route53—Amazon’s DNS service—affecting most of the AWS Wavelength zones based in us-east-1. We were seeing DNS times spike every few minutes on all the Page Load tests against multiple disparate major websites, and each showed the same issue.
Figures 1–3 below show some examples of the test results that we were able to share with AWS. They show intermittent Page Load spikes against multiple major highly available websites, which can indicate a systemic problem.
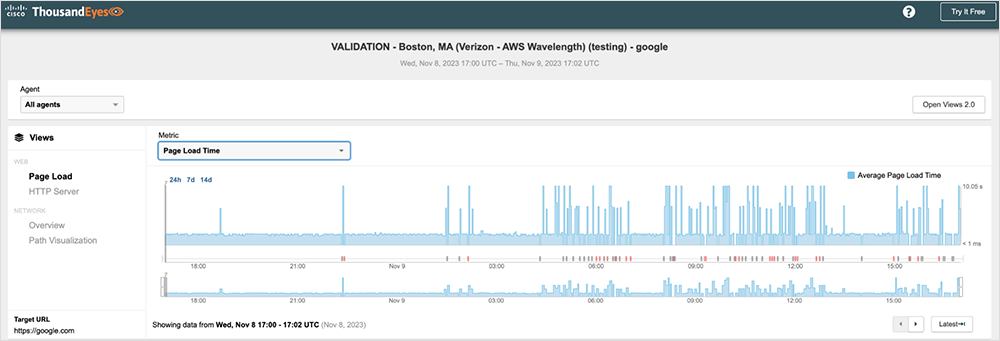
Explore an interactive view in the ThousandEyes platform (no login required).
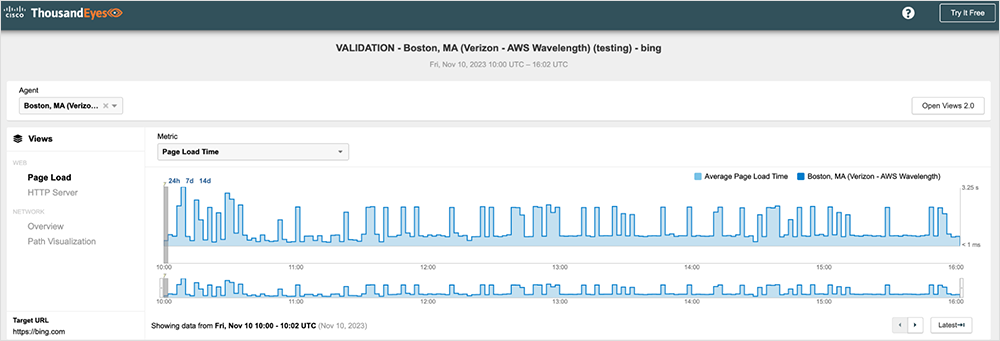
Explore an interactive view in the ThousandEyes platform (no login required).
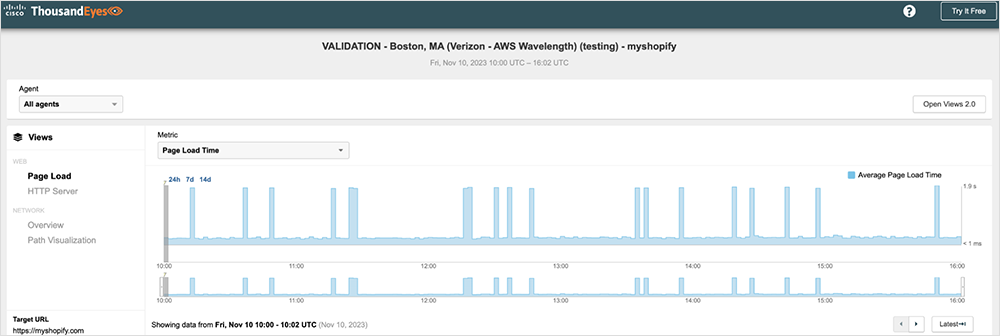
Explore an interactive view in the ThousandEyes platform (no login required).
We worked closely with the AWS Wavelength team to troubleshoot, diagnose, and ultimately solve the issue. The root cause of the DNS time spikes turned out to be a misconfiguration in Route53. Once AWS resolved the problem, we were able to release those Cloud Agents to our customers.
While we were not the first to deploy network observability in the AWS Wavelength zones, we were able to discover and fix a DNS problem that no one else had uncovered, working closely with the Wavelength team at AWS to drive towards a resolution that would improve the quality of service for our customers, for AWS Wavelength itself, and for any other organization using AWS Wavelength.









