


This is the Internet Report: Pulse Update, where we review and provide an analysis of outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read our full analysis below or tune in to our podcast for first-hand commentary.
Internet Outages and Trends
Before we dive into this week's highlights, let’s take a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (February 13–26):
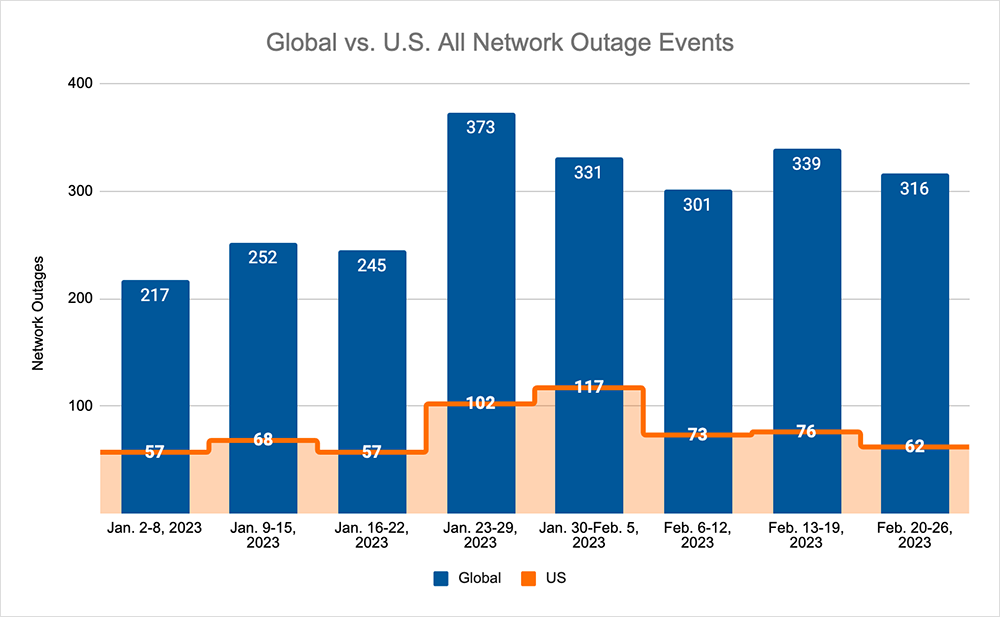
- Global outages initially reversed the downtrend seen over the previous two weeks, rising initially from 301 to 339, a 12% increase when compared to February 6–12. However, the downward trend returned the next week with global outages dropping from 339 to 316, a 7% decrease compared to the previous week.
- This pattern was reflected domestically, initially rising from 73 to 76, a 4% increase when compared to February 6–12. This was followed by a drop from 76 to 62, an 18% decrease compared to the previous week.
- U.S.-centric outages accounted for 21% of all observed outages, which is smaller than the percentage observed on January 30–February 5 and February 6–12, where they accounted for 30% of observed outages.
While data centers, and the cloud workloads they host, strive for always-on availability and maximum uptime, there are occasions when things go wrong. That often starts with power availability. When power is uneven or unavailable, teams have to determine whether a safe and “graceful” failover and/or shutdown is possible.
In the space of a week, we observed two data center incidents that led to “graceful” shutdowns of cloud infrastructure—and long-duration disruption for some customers.
Microsoft Outage: “Data Center Cooling Event” Impacts Teams & Azure Services
On February 7, Microsoft experienced a “data center cooling event” in Southeast Asia when a power brownout caused several chillers (units that provide cooling to the data center) to shut down. That reportedly caused difficulty for some customers in Southeast Asia when accessing a wide variety of cloud services, including Teams and other Azure services. The disruption lasted around 32 hours.
In its post-incident review, Microsoft indicated that a voltage dip at one of its Availability Zone caused the chillers to trip and lose power. While the power management system appears to have managed the voltage dip as designed, engineers attempting to restart the chillers were unable to do so due to what they describe as a “thermal lockout.”
This marks the third incident for Microsoft this year, after global service reachability issues in late January and the Outlook outage in early February. But Microsoft wasn’t the only cloud provider to experience data center issues in February.
Oracle’s NetSuite Outage
On February 14, Oracle had an issue with NetSuite, the Oracle-owned provider of ERP and CRM software. This was reportedly due to a possible electrical fire at the third-party facility hosting NetSuite infrastructure, which led to a controlled shutdown and evacuation of the site. It was offline for almost 24 hours, according to the reports.
In addition to these data center-related incidents at Microsoft and Oracle, we observed other outages over the past two weeks that had a long duration or a large geographical impact, and—in some cases—both.
Oracle OCI Outage
On February 13, Oracle observed a “performance issue within the backend infrastructure that supports the Oracle Cloud Infrastructure (OCI) Public DNS API,” according to its incident report.
Impacted customers might have experienced “intermittent failures” when managing DNS resources and delays with DNS zone propagation. A number of OCI services encountered failure conditions, including being unable to spin up new instances or delete existing ones. There were also issues with identity, email, and web application firewall services, among others.
The incident lasted two days and five hours, according to the incident report—and was broadly felt across the OCI footprint.
Twitter Outage: Users Report Glitches With Tweet Limits
We’ve had Twitter under observation for some time, and although the infrastructure and architecture have proven to be resilient so far, the application itself has experienced some glitches.
On February 9, some Twitter users reported being erroneously greeted with a warning that they were “over the daily limit for sending tweets” and would be restricted from tweeting more. The limit is 2400 a day. Users also reported encountering messages that they’d breached other limits, such as the number of people they could follow in a day.
Twitter’s advisory at the time did not detail the issue, but with no significant reachability or network issues observed at the time, any functional issue within the platform may point to an application issue that could have possibly been the result of enhancing and tuning the way the application and its algorithm performs. As the application architecture is being changed, these kinds of breakages and glitches could become more common, although it should also be added that this was a relatively small duration incident.
Atlassian’s Backend Wobbles
On February 15, at around 9:04 AM UTC, Atlassian appeared to experience an outage that impacted access to some of its services. We observed a duration of around 50 minutes and an impact on all regions. While Atlassian utilizes AWS as its cloud provider, no other application services appeared to be impacted at the same time, and there were no significant network issues observed, implying this was related to some sort of backend change or issue specific to Atlassian, rather than an AWS problem.
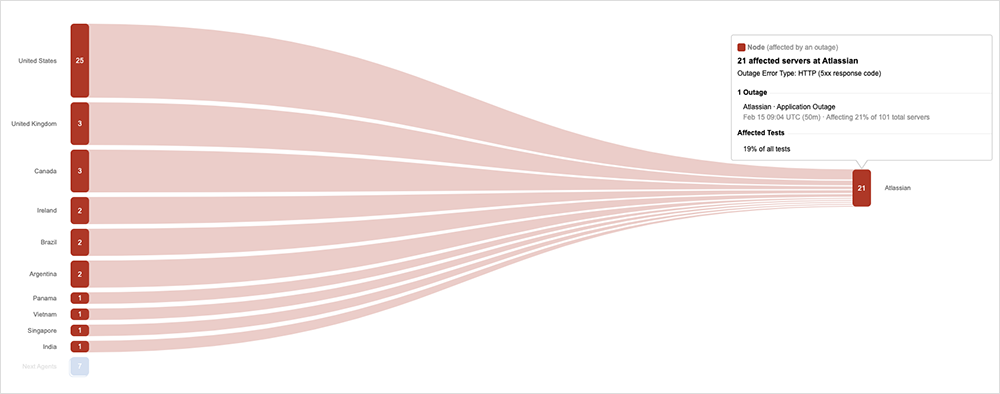
Impacted users would have been able to access the application frontend, but they may have encountered HTTP 503 service unavailable errors when trying to call upon backend resources or data.
No explanation has been provided, so it may well have been a maintenance exercise, but the incident underscores the importance of understanding the entire service delivery chain in order to be aware of every dependency and interconnection so that impact and footprint can be kept to a minimum.
Tesla App Outage
A Tesla app outage in Europe also garnered some attention, with car owners reportedly unable to lock or unlock their vehicles or find charging stations using the app. The issues mostly affected people outside of North America.
While owners could still access their cars via a physical key card, these types of backend issues will become increasingly important for companies to guard against as more and more cars rely on apps and subscription services to power all kinds of connected features.
Fitbit Issues
Users of Fitbit encountered consecutive syncing issues between devices and the mobile app in a 24-hour period. The issues point to some kind of backend or application issue, which the company indicated it had since resolved.








