This is the Internet Report: Pulse Update, where we review and provide analysis of outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages.
We’re kicking off the new year with a refreshed format for this series. You can read our full analysis below as you always could, or watch (or listen to) our new podcast to hear our commentary first-hand.
The holiday period is traditionally a time of diverging fortunes for tech teams.
Some teams have been under strict orders to do less by way of code freezes. Wanting to avoid interruptions during the holiday period, engineering teams agree not to write or push changes to production for a number of weeks. With no major changes comes a lower likelihood of something major going wrong, particularly in a period where end users were more reliant on the technology being functional. At a time when people are looking for distractions and lean harder on their Internet connections for entertainment or on eCommerce sites to fulfill their holiday shopping needs, it makes sense to keep these services stable during this period of increased demand.
For other engineering teams, particularly those serving more internal-facing customers or a predominately enterprise customer base, the holiday period is traditionally an extended window of time in which to perform larger changes that would be too disruptive during regular working times: a migration or cutover between two critical systems, or a core network or switch upgrade. If anything goes wrong, there’s more time to iron things out or to roll back without the pressure of a looming business day.
While this kind of thinking still persists, it is becoming increasingly outdated. For a growing number of teams in charge of agile applications and highly resilient and self-healing infrastructure, the holiday period presents no special challenges.
Today, agile and continuous integration and deployment (CI/CD) methodologies have found mainstream use. In addition, applications are more likely to be highly scalable and resilient, built to be cloud-based or cloud-native rather than hosted on-premise.
This combination has made teams more confident that code freezes through the holiday period are no longer necessary: that changes can be deployed to production without breaking stuff (although, as we’ve previously analysed through 2022, this confidence is often misplaced. A lot of outages look like agile changes and rollback, or chaos testing and recovery.)
And so we now get situations where web apps like Twitter make large backend changes during a holiday period—and if something breaks, as it did in this instance, the engineering teams simply keep calm and carry on. The Twitter case is interesting because they did appear to enter a code freeze around Thanksgiving—we observed disruptions trail off to near zero during this period. It shows that the strategy for the modern holiday period can be multi-pronged: a code freeze affecting the application teams, for example, doesn’t preclude underlying infrastructure upgrades by another team. Even though there are freezes in production, there’s still a lot of active work causing some amount of instability.
This could point to a longer-term trend emerging where there’s no longer a need to adjust one’s engineering approach for the holidays. Suppose applications and the underlying infrastructure are resilient. In that case, it is increasingly plausible to roll through the holidays as though nothing special is happening, making things like change and code freezes a relic of the past.
There is still some work to do to reach this point, however. One of the key questions for cloud and Internet service providers (ISPs) is: when is a good time to make big changes? A consistent theme we explored throughout 2022 was that there just isn’t a good time-of-day or time-of-week anymore for any sort of disruption. With consumers and businesses alike heavily reliant on the Internet and on cloud-based applications and services, downtime—scheduled or unscheduled—will always impact someone somewhere in the world.
It’s possible that if changes become small and agile instead of large and concentrated towards the end of the calendar year—and the effect of these changes are visible, observable, and actively monitored—that this question can be satisfactorily resolved.
Clearly, not all service providers are well-positioned enough to be making agile changes all of the time today.
We are seeing evidence of movement in this direction. Seasonally adjusted, the number of cloud and network disruptions in the final months of 2022 was lower than in previous years and included the usual downward dip that we’d expect to see for the holiday season.
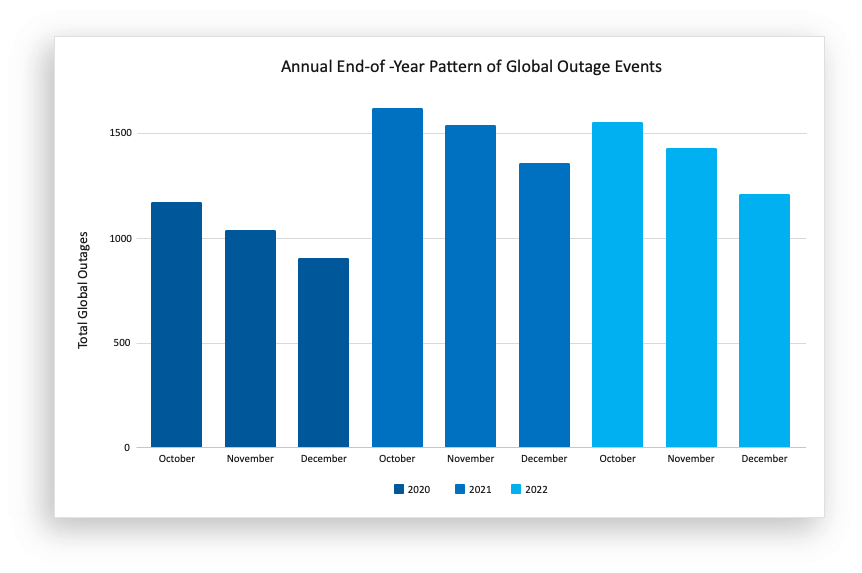
This year, we anticipate more providers getting better at agile and resilient infrastructures and application architectures, and with that, increased capability, end-of-year strategy, and mindset changes will become more common.
Spotify Disruption
Friday the thirteenth wouldn’t be complete without some form of misfortune, and this time around, it appears Spotify was the unfortunate recipient. While not of the magnitude described by singer-songwriter Don McLean in American Pie, the music did seem to stop streaming for a number of users globally for close to two hours. First observed around 7:40 PM EST, the disruption initially manifested as system timeouts. Connectivity to the Spotify services appeared to be intact, but an increase in wait time started to be observed, impacting a number of regions across the globe.
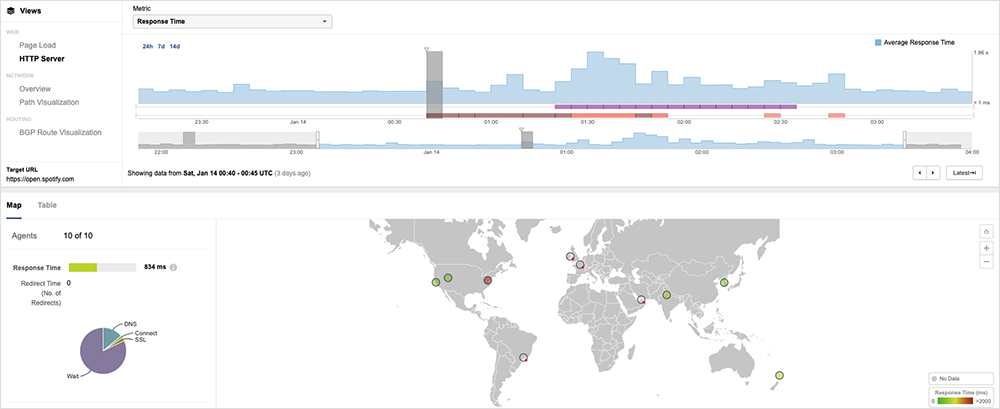
Around 8:20 PM EST, ThousandEyes began observing widespread issues affecting multiple regions globally, with a number of requests to Spotify services either timing out or returning service unreachable (HTTP 503) or unauthorized messages (HTTP 401), which is indicative of backend system issues as opposed to a network issue.

At 8:53 PM EST, Spotify announced that they were experiencing some issues and they were investigating. The disruption lasted around two hours, appearing to clear around 9:35 PM EST when services began to return. Around 11:16 PM EST, Spotify announced that all services had been restored.
Internet Outages and Trends
Looking at global outages across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks, we saw:
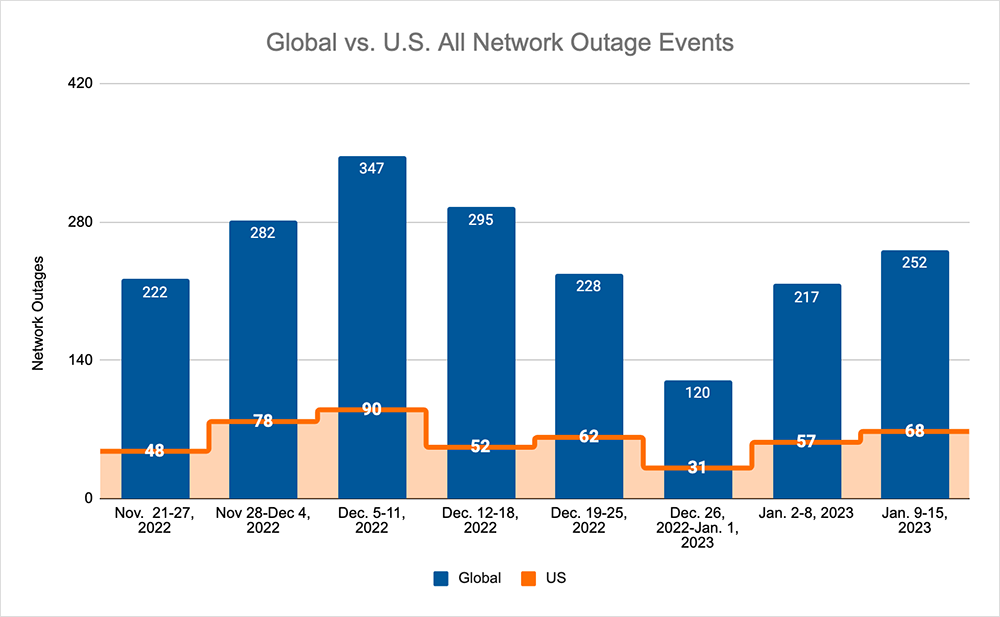
- After an initial increase of 23% when compared to November 28-December 4, global outages began a downward trend through the end of 2022—dropping from 347 to 120, a 65% decrease between December 5-11 and December 26-January 1. Subsequently, global outages rose from 120 to 217, an 80% increase compared to December 26-January 1, followed by another rise from 217 to 252, a 16% increase compared to the previous week.
- This pattern was not reflected domestically, initially rising from 78 to 90, a 15% increase when compared to November 28-December 4—followed by a drop from 90 to 52, a 42% decrease compared to December 5-11, before rising from 52 to 62, a 19% increase from December 12-18. The domestic numbers then halved, dropping from 62 to 31, a 50% decrease when compared to the previous week. Before mirroring the global pattern with rises of 31 to 57, an 83% increase compared to December 26-January 1, followed by another rise from 57 to 68, a 19% increase compared to the previous week.
- U.S.-centric outages accounted for 27% of all observed outages, which is the same percentage observed on November 21-27 and November 8-December 4, December 19-25 and, December 26-January 1, but higher than the percentage observed on December 5-11 and December 12-18, where they accounted for 22% of observed outages.