


In the age of DevOps and chaos engineering, “moving fast” often means that not everything pushed to production is going to work perfectly all of the time. The month of August served to reinforce that notion, as repercussions of these approaches appeared to manifest as outages. Two issues in particular stood out over the past month—but more on that in a moment.
Internet Outage Trends
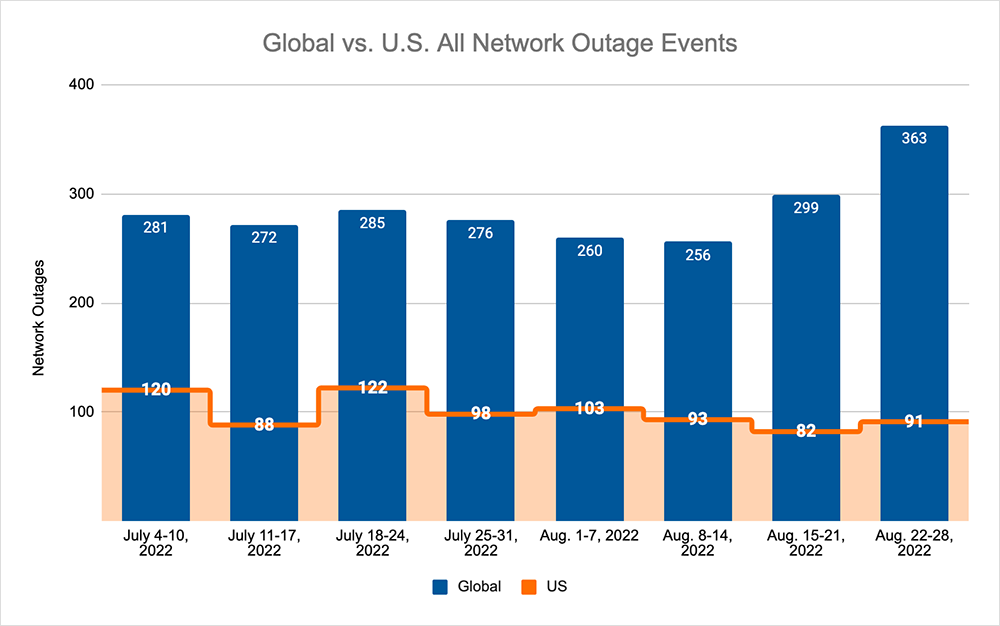
First, let's take a look back at the global outage numbers for the last couple of weeks. During that period, we saw the downward trend, which we also observed during late July and early August, come to an end.
- Global outages rose 17% during the week of August 15 (256 to 299 as shown in the chart below) when compared to the first week in August, then rose another 21% during the week of August 22-28.
- That global upward trend was not reflected in the U.S. The observed numbers there fluctuated, from a 12% drop (93 to 82) between the weeks of August 8 and August 15, to an 11% increase (82 to 91) between the weeks of August 15 and August 22.
- Even with that increase during the week of August 22, U.S. outages decreased overall by 2% (93 to 91) as compared to the week of August 8.
Application Issues Abound
On August 8, Google experienced an outage that affected the availability of several services, including Google Search, Google Maps, and associated services that use them, such as Gmail.
Customer-facing impacts were first observed at around 9:15 PM EDT, as users were unable to access the service, although the application remained reachable from a network perspective. The disruption lasted a total of 41 minutes over a 55-minute period, and cleared by around 10:10 PM EDT.
The official explanation for the issue was a software update that went wrong. That correlates with what we observed in the ThousandEyes platform: the errors we saw were indicative of a back-end application issue.
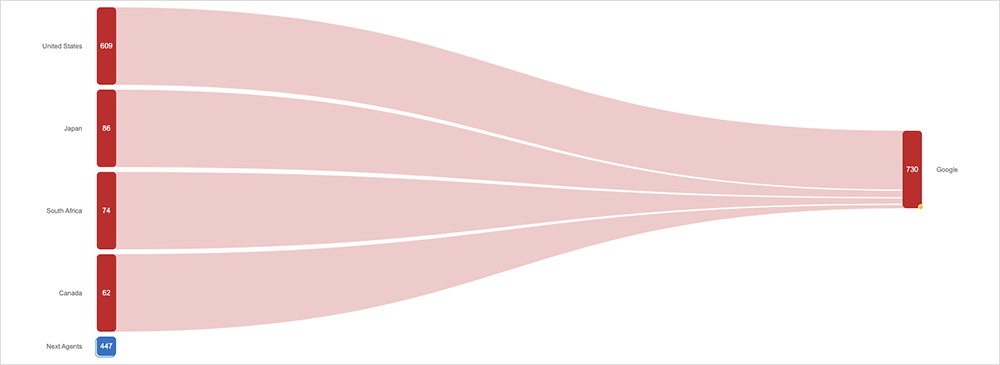
One possible explanation is that the update was related to how Google indexes search queries and terms. The commercial search industry reported issues with the indexing of web pages and particularly with page and site rankings. These issues lasted for about 24 hours after the Search outage, before being fixed.
In the absence of a detailed post-incident report, it’s difficult to say with certainty that the Search/Maps outage and indexing issues are related, although it is certainly plausible they are/were.
The following day, Twitter experienced a service disruption that impacted users globally, which was also blamed on a bad software update that had to be rolled back. First observed around 2:00 PM EDT, users were unable to access the service, although the application remained reachable from a network perspective. The disruption lasted 28 minutes, with service access restored to users around 2:30 PM EDT.

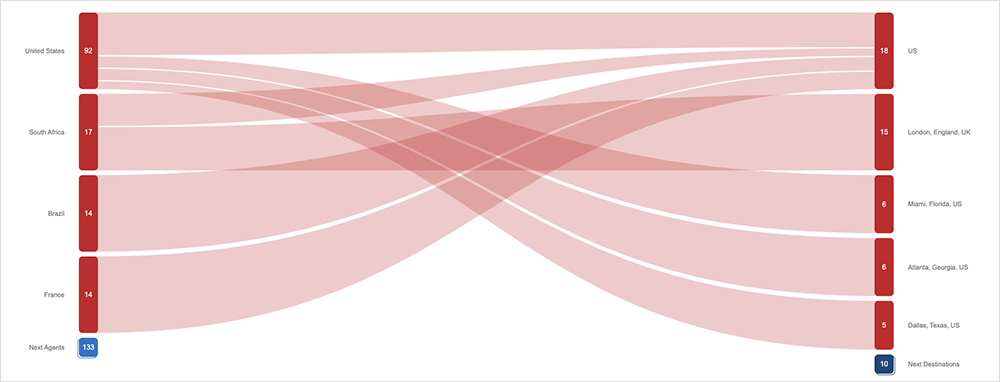
Again, the errors we observed during the incident were indicative of a back-end application issue. In addition, Twitter later announced that the disruption had been caused by an internal system change issue that has since been reverted.
As the world becomes more Internet-based and cloud-hosted, more of what we do is software-defined. Coupled with agile sprints and DevOps strategies designed to move code to production faster, it’s inevitable that the occasional bad update will slip through quality control.
However, it’s also possible the software update in each case was fine in isolation, but it caused unanticipated impacts upstream or downstream once put into production.
Have Your DevOps (With a Side of Visibility)
I’ve written several times before in this column about dependencies and interdependencies in software delivery chains, and how hard these are to identify or track without specific tools that establish this kind of cross-ecosystem visibility.
We’ve also previously seen outage incidents caused by one part of an organization not knowing what another part was doing.
These days, nothing can be introduced to an environment in isolation. A team may be responsible only for one part of a software application, but it has to be aware of, and have immediate visibility into, the impact of actions that it takes on the rest of the code packages that make up that application.
This may be more easily said than done in large organizations, where it may be challenging to map out the full range of consequences that could potentially flow from taking a single action.
That’s why, within large and complex environments, we often see ThousandEyes being used almost as a DevOps-type tool—giving the team that pushes a software update or new feature to production an immediate feedback mechanism where they can monitor for, and quickly identify, instances where the introduction of new code has unexpected impacts on the overall service delivery.
Developers or teams may only be accountable for one part of an application or service, but they still have a responsibility to ensure their actions don’t break or degrade overall application or service delivery. There’s always a possibility that coding mistakes might slip through, but full end-to-end application or service delivery visibility can provide an extra layer of insurance for fast-moving dev teams: so that if something unexpectedly breaks, it can be recognized and rolled back before significantly impacting the user's digital experience.









