This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
Outages can look very different, depending on where in the end-to-end service delivery chain they occur. There are material differences in blast radius, from localized impact extending to global impact; they can be the result of planned or unplanned work; and the mean-time-to-resolution (MTTR) also varies.
The distributed architecture of today’s applications means lots of moving parts need to be orchestrated in unison to deliver a service or to enable a workflow. These parts are often single points of failure, and because they may be used for a similar purpose by many applications, the impact of an outage could be widely felt.
By contrast, the anatomy of a network outage depends on where in the network the problem occurs. A transit network incident—a cable break, for example—may impact multiple providers, compared to a problem impacting the last-mile, which is likely to only affect the customers of one provider. That being said, an outage on a popular transit route may not always cause the widespread impact it once might have due to the proliferation of diverse routes available, and traffic from one path can often be re-routed seamlessly to another, making an outage on one problematic route barely perceptible to end users.
Different anatomies point to different categories of outages or degradations that are useful to track over time. The frequency and severity of these incidents is interesting, as well as the impact that improved visibility, together with architectural and operational optimizations, has on minimizing both the occurrence and impact of outages.
This kind of intelligence can be helpful in recognizing the early onset of patterns that match the anatomy of a particular outage or degradation type. Speedy recognition and diagnosis can help teams to remediate or route around the problem, before it can impact backend functions or customer-facing services.
To learn more about outage anatomy and common warning signs of several types of outages, read on for some recent case studies and also see this Internet Outages Survival Cheat Sheet.
Understanding the Anatomy of an Outage: Recent Case Studies
In the past fortnight, we saw some of these common outage patterns surface and resurface over and over.
We’ve covered in past weeks the ransomware-related outage at Dish Network, and what its network statistics show us about how it is recovering its systems and services. The anatomy of this type of outage might be characterized as the sudden disappearance of public-facing assets and services, consistent with equipment being unplugged or gracefully shut down to ring-fence a security incident and prevent its spread.
Two similar cases occurred this month.
Security-induced Incidents: Western Digital and SD Worx Outages
Earlier in April, Western Digital users started reporting 503 errors and being unable to authenticate when trying to access the company’s My Cloud storage services. It quickly became clear that the root cause was an attack on Western Digital’s systems that prompted the company to suddenly pull its public and Internet-facing services offline. Following the typical anatomy of this type of outage, it took over a week for regular service to resume.
Similarly, SD Worx, a European payroll and HR platform operator, shut off public access to its systems following anomalous traffic detection. A status message sighted by several news outlets stated it had “preventively isolated all systems and servers to mitigate any further impact. As a result, there is currently no access to our systems.”

A Single-Point-of-Aggregation Issue: SpaceX’s Starlink Outage
SpaceX’s Starlink also experienced a security-related outage, but the anatomy of its incident was quite different from that of Western Digital and SD Worx.
The root cause in this case was an expired security certificate at a ground station: a single point of failure that led to hours of downtime for Starlink’s global customer base. The company pledged a sweep of its operations for other single-point vulnerabilities in the aftermath. This kind of incident is infrequent but does happen. The frequency is lower in a world where, operationally speaking, much of this kind of management overhead is being offloaded to automation suites, which help eliminate mistakes of this nature.
Last-Mile Challenges: Vodafone UK Outage
We also observed an outage that impacted part of the customer base of a single telco, Vodafone UK. The anatomy of this outage suggested that the problem was in the last-mile, between the customer’s premise and a traffic handoff point.
Similar to the issues experienced earlier in April by Virgin Media UK, Vodafone UK customers ran into challenges when Vodafone’s ability to establish a working connection out to the public Internet suddenly ceased. The anatomy of the Vodafone and Virgin incidents looked relatively similar, in that they impacted their customers' connectivity to the Internet directly, but did not significantly impact downstream partners or customers’ connectivity. They also reflect a pattern we’ve observed in network-related outages, where impacts are relatively localized in nature.
By the Numbers
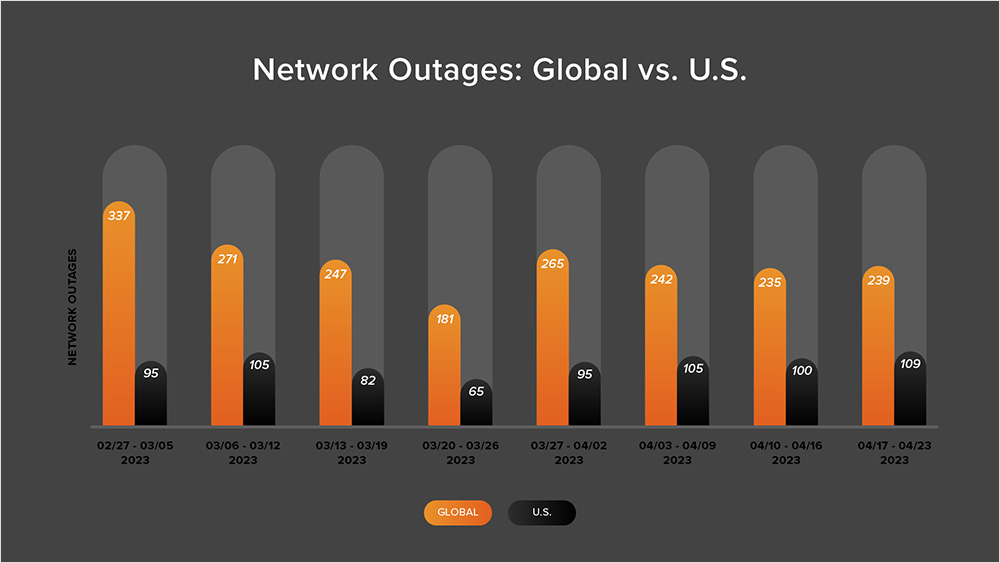
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (April 10 - April 23):
- Following a couple periods of greater fluctuation, the last two weeks saw outage numbers somewhat stabilize. Initially, global outages dropped slightly from 242 to 235, a 3% decrease when compared to April 3-9. This was followed by a slight rise, with global outages nudging up from 235 to 239, a 2% increase compared to the previous week (see the chart below).
- This pattern was reflected in the U.S. as outages dipped slightly, dropping from 105 to 100, a 5% decrease when compared to April 3-9. This was followed by a small rise from 100 to 109 the next week, a 4% increase.
- U.S.-centric outages accounted for 44% of all observed outages, which is larger than the percentage observed between March 27 and April 2, where they accounted for 39% of observed outages. This is the first time in 2023 that U.S.-centric outages have accounted for more than 40% of all observed outages.