This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
Backend-related incidents—whether caused by data center power, technical floor space, hardware, or common (shared) services—have been a recurring theme in outages across 2023.
This hasn’t always been the case. In past years, the most dominant form of outage was network or Internet infrastructure-related. Today, however, network and Internet infrastructure-related outages appear less commonly as the amount of redundancy now present in that ecosystem helps maintain performance and resiliency.
The same can’t necessarily be said for web-based applications. The infrastructure needed to run these applications relies on data centers. Application owners need to consider how the site hosting their application is powered, and also pay attention to the architecture of the application itself, to avoid a data center becoming a single aggregation point that could render an entire service unavailable if it encounters issues.
Even the best-laid plans can go awry when application architecture is allowed to evolve in different ways, or where decision-making by the data center operator during an evolving incident may not be completely transparent.
Most large application makers also have their own disaster recovery infrastructure, but it is not always simple to spin up, and leeway is often given to the source of an incident, particularly a primary facility operator, to right the ship before the disaster recovery (DR) option is engaged (knowing that recovering the primary site may be faster than failing over to the DR infrastructure). However, in the case of the recent Cloudflare outage as discussed further below, recovery appeared to be delayed by a third-party facility operator taking longer than anticipated in this regard (an issue that also may have contributed to the recent banking outages in Singapore, as discussed in the previous Pulse Update).
Read on to learn more about what happened at Cloudflare and Workday, as well as a disruption at OneLogin and some recent availability issues at GitLab—or use the links below to jump to the sections that most interest you.
Data Center Power Problems Cause Workday and Cloudflare Outages
On November 2, both Cloudflare and Workday experienced service outages. Given the overlap in timing, and with both initially attributing their issues to data center power failures, the immediate question is whether the two incidents were related. A combination of post-mortems, OSINT, and ThousandEyes observations suggest that is indeed the case.
Cloudflare provided an extensive incident post-mortem report. It was over six hours before disaster recovery was successfully enabled, and it took 36 hours in total to fully recover. Workday officially reported full-service restoration around 5:00 PM PDT, but its customer status notifications indicated that services had been restored around 2:30 PM PDT.
The common element appears to be a partial mains power outage at a Flexential data center in Portland, Oregon (while Workday doesn't specifically name their data center at issue, they reference a Portland, Oregon, data center and, due to the similar timing, we speculate that they're referring to the same data center). According to Cloudflare, when one mains feed to the site was disabled, the remaining feed was supplemented with power from onsite generators, only for a further ground fault with a transformer to cause a complete power loss to the site. It appears the complete power loss only became apparent when equipment ungracefully shut down, and application makers sent their own technicians on site.
A few things reportedly exacerbated Cloudflare’s problems.
Cloudflare says it had unknown dependencies on critical services hosted only at the one site, which had remained undetected because a complete site shutdown had never been tested. In addition, the company found some capabilities that were generally available (GA) did not conform to engineering best practices. Not wanting to slow down engineering teams from innovating and developing new functionality, the company allowed for some variations as long as they were resolved prior to the functionality going GA. However, this did not occur uniformly, impacting recovery. The company also found itself operating in an official information vacuum, at least initially, which made determining remediation aspects difficult.
At 13:40 UTC—two hours after the complete power loss, and after the Oregon data center operator and local utility encountered complications in restoring power—Cloudflare decided to fail over to disaster recovery sites located in Europe.
Workday’s official explanation is less detailed, though it similarly notes that recovery of the Oregon site took longer than expected. “Due to issues with backup power failures, as well as an unstable power environment resulting in additional challenges, service restoration has taken longer than is typical,” it noted. Its problems mostly impacted the Workday WD5 instance, which is said to be hosted in the same facility.
ThousandEyes observed a range of issues with Workday, from “page content did not match” errors (which occur when the interaction between the client and server breaks down) to an immediate redirect at the login request to a static maintenance page. Another element to note is that ThousandEyes tests show that the static content is being served out of AWS; prior to the outage, Workday content was being served via Cloudflare.
OneLogin Disruption
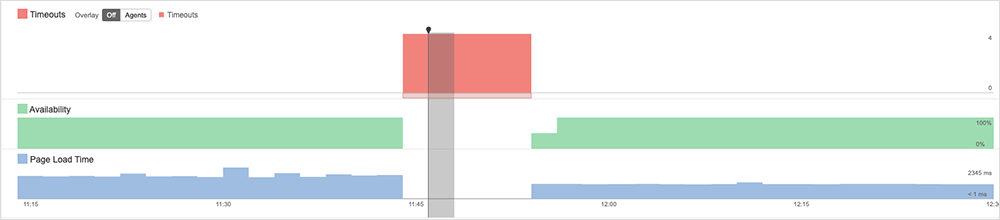
On October 26, cloud-based identity and access management provider OneLogin experienced a service disruption that manifested as 5xx errors to users. The disruption’s length was officially reported as 183 minutes—a bit over three hours—but it appears to have had a much longer total duration.
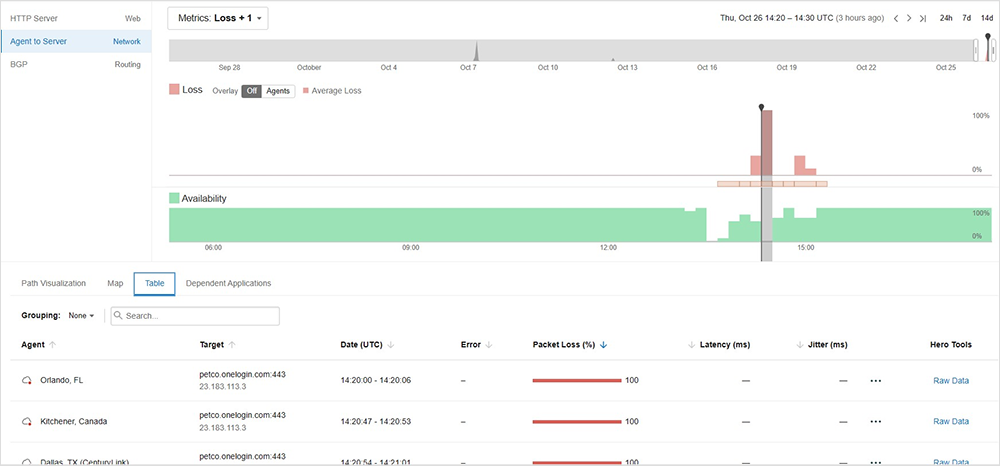
While duration is often lengthened by the time required to fully propagate backend changes or get all affected users fully reconnected, in this instance, it appears something went wrong with the recovery process for the initial service fault. This caused increased packet loss and more users to experience issues. In other words, while the initial fault was more contained, or at least its impact was uneven, recovery activity created connectivity problems that affected a broader subset of users, and that also served to lengthen the total duration.
Similar problems affected other single sign-on (SSO) platforms this year. A common workaround, though obviously a bit more time-consuming, is for enterprises to have users individually log into the third-party applications or services that they would normally authenticate to via SSO. Users may have taken that step during the OneLogin incident, lessening the impact. However, we saw no specific chatter of workarounds, which could also suggest some impacted organizations elected to just ride the disruption out, rather than implement temporary backup solutions.
The company is very transparent in its publishing a calendar view of historical outages, both planned and unplanned. OneLogin had three “red” service disruptions (defined as impacting its uptime rating) in 2022 and four in 2023. By contrast, its records show it did not have any such disruptions between 2014 and 2021, suggesting that outages may have increased since OneLogin was acquired in 2021. We saw a similar pattern emerge with X after it changed hands, with considerable backend work leading to increased disruptions. It could be the same is occurring at OneLogin, in terms of an increased amount of optimization work being carried out on the application and/or its underlying infrastructure post acquisition.
GitLab.com’s Availability Issues
On October 30, GitLab.com was affected by “availability issues” for almost three hours due to increased load on the underlying database infrastructure. The database became saturated by a large increase in bulk import jobs; GitLab resolved that by temporarily disabling bulk import functionality for all of GitLab.com, allowing the queued jobs to run, and clearing the way for other imports to resume.
Users impacted by the issues would have been able to log in, but then seemingly experienced timeouts when attempting to access or retrieve data held in GitLab.com. These timeouts likely manifested as failure to retrieve errors, which are indicative of backend service issues.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (October 23-November 5):
-
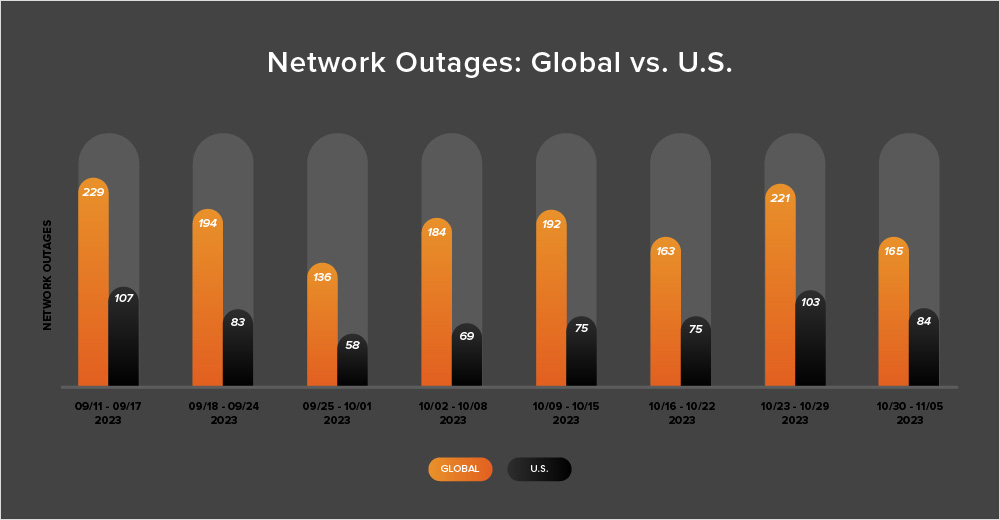
Between October 23 and November 5, the number of outages worldwide fluctuated fairly significantly. During the first week of this period (October 23-29), the number of outages increased from 163 to 221, which represents a 36% rise compared to the previous week (October 16-22). However, the following week saw a 25% decrease in outages, which dropped from 221 to 165. This is illustrated in the chart below.
-
Outages in the U.S. followed a similar pattern. They rose from 75 to 103 during October 23-29, representing a 37% increase. However, during the following week (October 30 - November 5), outages decreased from 103 to 84, an 18% drop from the previous week.
-
From October 23 to November 5, U.S.-based outages accounted for 48% of all observed outages, a continuation of the trend observed almost every fortnight since April 2023 in which U.S.-based outages accounted for at least 40% of all observed outages in a given two-week period.
-
Looking at recent month-over-month trends, in October, the number of global outages increased from 770 to 831, which is an 8% rise when compared to September. The same trend was observed in the United States, where the outages increased slightly from 352 to 355, a 1% rise. These patterns are in line with previous years, where outages tend to increase after the Northern Hemisphere summer.