SaaS app architectures vary, even those from the same SaaS provider, and thus require slightly different monitoring approaches to prevent spikes in help desk costs. Yet, with hundreds or even thousands of remote workers, doing so demands a distinct solution to manage these nuanced end user experiences and ultimately keep employees productive.
Flexibility for Changing Workforce Routines
SaaS applications today are built on modern, hugely scalable, and dynamic architectures that came in handy when workforces went remote en masse in early 2020. In fact, SaaS spending will increase by another $20 billion in 2021. And in the foreseeable future, SaaS apps will be vital to enterprise success as we navigate the uncertain waters of variant strains that necessitate human-centric hybrid work arrangements.
The trend towards relying on applications from outside the corporate perimeter is nothing new (see digital transformation). What is changing is the environment for SaaS app delivery. No longer fixed to one location, end users are, by and large, free to decide when and where work gets done, which could change hourly and fluctuate depending on a variety of conditions. In addition, the SaaS apps themselves are becoming more complex, more distributed over cloud providers, and more reliant on high-performing APIs that are themselves distributed and reliant on third parties. Thus, the ecosystem is as vast as it is complex.
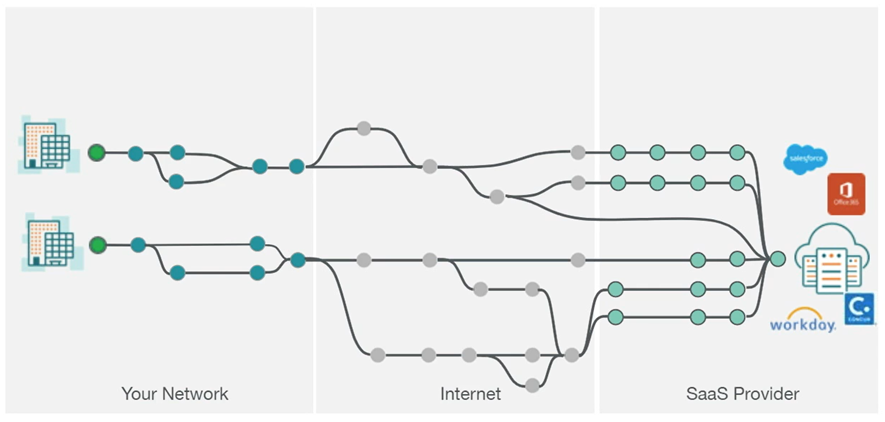
Where to Begin in This Ecosystem
For the network team, who are well versed in the extensive ecosystem of dependencies that a particular application depends on for proper transit to a single branch office, the new reality of monitoring multiple SaaS applications to hundreds of home offices (environments that can change daily) and branch sites creates an operational challenge for even the brightest of minds. Now add connectivity issues that can affect home WiFi setups, residential ISPs, or VPN performance, and the network team is left unsure where to begin when tickets pop up reporting subpar SaaS performance.
Get the Guide to Taming SaaS App Sprawl eBook
In the not-too-distant past, Ops teams turned to traditional network and application performance monitoring techniques to better assess the root cause of their app performance issues on-prem. But these techniques focus on the infrastructure you own, and, on the app side, they rely on code injection that just doesn’t work for SaaS.
What about using vendor status pages? Expect them to lag the real-time needs of network teams for outage responses, much less performance slowdowns, if the providers can detect any issues at all. These pages will also exclusively focus on their environment, meaning that relying only on status pages can leave network teams clicking refresh as tickets and costly downtime piles up.
Grasping Constantly Changing Dependencies
Teams serious about SaaS monitoring know that ThousandEyes' end-to-end visibility is the only way to go. From pre-deployed Cloud Agent vantage points located in over 200 cities, ThousandEyes offers enterprises a complete view of SaaS app performance and delivery with deep insights into external dependencies such as DNS, ISPs, CDNs, and SaaS provider networks. Keeping the deployment process flexible yet expansive to an organization's needs, ThousandEyes uses Enterprise Agents and Endpoint Agents to gather in-network and end user device data and correlates those details to underlying network layers. This data, visualized by ThousandEyes for easy understanding, allows network teams to collaborate and escalate problems productively with SaaS providers.
Cushman & Wakefield, a commercial leader in global real estate headquartered in Chicago, is one ThousandEyes customer who transformed how it delivers and monitors business-critical SaaS apps, like Outlook and SharePoint. Though both are Microsoft 365 services and hosted on the Azure cloud, the intranet and mail/calendar apps use different DNS techniques to engage with the SaaS network's backbone, requiring nuanced monitor approaches that account for constantly changing Internet routing.
"We had a number of monitoring solutions in place already, but they tended to focus on our internal networks," said Greg Telford, Head of Operations, EMEA at Cushman & Wakefield. "Now [that] we were more reliant on the public Internet and SaaS applications, we needed something that would let us monitor the user experience end-to-end, regardless of which networks we used to reach the application."
Pinpointing the Culprit
ThousandEyes’ capabilities have allowed Cushman & Wakefield to reduce mean time to resolution (MTTR) by detecting and quickly pinpointing the culprit of poor SaaS performance, be it home Internet service or SaaS infrastructure. In addition, for its SaaS rollout, Cushman & Wakefield trusted ThousandEyes to validate performance and success metrics before deployment, which uncovered and resolved issues before impacting its 50,000 team members in 60 countries.
Greg adds, "We were very easily able to see whether issues were caused by events in our core network, or in provider networks, and then share information showing the exact location of issues and how they link to application-level issues.”









