This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
When it comes to outages, often a seemingly minor issue can cascade into something much bigger. While the component at issue may appear to be just a small link in the overall service delivery chain, when this link isn’t working properly, the repercussions can be significant. The impact of a malfunctioning “link” is often exacerbated by a lack of understanding or visibility into the entire end-to-end service delivery chain, especially in situations when a change is made outside of the standard operating procedures or pipelines.
Over the past fortnight, the disruptive power of these seemingly small links was on display when something as small as an expired security key had big ramifications for the .au direct namespace; when a security policy change closed off access to multiple clouds; and when a documented mitigation was undermined by another team’s approval process, which took precedence.
Read on to learn about all these outages and degradations, or use the links below to jump to the sections that most interest you.
.au Domains Fail to Resolve
A number of large Australian websites, using the direct domain .au, notably those belonging to media outlets, failed to resolve for up to an hour, due to a DNSSEC key signing error at the .au Top Level Domain (TLD) administrator, auDA.
DNSSEC is used to authenticate the integrity of the data sent by the DNS server and to secure DNS against certain attacks, such as hijacks and cache poisoning. During the auDA incident, “DNS resolvers with DNSSEC validation were unable to validate the authenticity of .au DNS records,” auDA wrote in a brief explanation. “As a result, the resolvers prevented resolution of .au domain names for their users.”
The root cause, auDA said, was a DNSSEC “key re-signing process that generated an incorrect record for a short period.” Observations indicate that the re-signing key itself may have expired.
The basic steps of DNSSEC resolution and validation go like this:
-
A client requests an A record, for example.com, from its local validating recursive server.
-
The validating recursive server starts the normal recursion process, beginning from the root and moving down to the authoritative servers of the example.com zone.
-
After that, the recursive server requests the A record from the authoritative server.
-
The authoritative server responds with the A record and corresponding RRSIG A record for example.com.
-
The recursive server then asks the example.com authoritative server for the DNSKEY record for the zone.
-
The authoritative server, for example.com, provides the DNSKEY record and corresponding RRSIG DNSKEY record for example.com.
All the above steps ensure that the client receives the requested A record for example.com, while also verifying the authenticity of the records received through the use of RRSIG records.
During the .au incident, the authoritative and recursive servers could not complete the key exchange, and things broke down from there.
The front-facing impact of the incident was uneven. Media consumers who regularly visited news sites may have saved them in a local cache, and were less likely to have experienced problems accessing the pages themselves. Similarly, most streaming services on the impacted .au domains remained available, since content is likely to have been held in cache via a content delivery network (CDN).
However, users starting new content sessions or people who had cleared or had their local cache timeout, may have been impacted. While the official duration is listed as “under an hour,” it’s likely that restoring customer access to the impacted sites took longer as they waited for the fix to propagate.
The incident highlights the importance of tracking “all the small things”—but particularly encryption artifacts like keys and certificates. We’ve observed similar incidents in the past few months: a cert expired at a Starlink ground station in April, and a cert error that impacted Microsoft SharePoint Online and OneDrive in July. In an effort to help avoid problems like this, teams may choose to invest in tools that provide them visibility and early warning into things like soon-to-expire certificates—or put other strategies and processes in place to guard against such issues.
Salesforce Outage
Salesforce experienced an issue with “multiple” cloud services on September 20, that took four-and-a-half hours to fully clear. The issue manifested to users as preventing login and access to their services.
Similar to the .au incident, the cause of this Salesforce outage appears to be a seemingly small thing that ended up having a big impact. The official explanation is that a cybersecurity policy was changed that “excessively restricted permissions for selected service-to-service communication, resulting in a functional disruption to [their] systems.” Given the nature of the change, it was likely introduced manually, but this led to issues in review and validation testing. Though the change was ultimately rolled back, some cloud services—Tableau and MuleSoft—took an extended period to fully recover.
Microsoft Azure Outage
During a September 16 Azure outage, mitigation efforts were reportedly hindered when another team’s approval process conflicted with the engineers’ work. On September 16, some Azure SQL Database customers in the East US region experienced issues when trying to connect to their databases. The incident lasted all day, though notably occurred on a Saturday, which would have lessened customer-facing impact.
“This incident was triggered when a number of scale units within one of the datacenters in one of the Availability Zones lost power and, as a result, the nodes in these scale units rebooted,” Microsoft said in its post incident review. “While the majority rebooted successfully, a subset of these nodes failed to come back online automatically.”
The outage was lengthened because unbeknownst to the on-call team, the documented mitigation— forcibly rebooting the nodes—was “blocked by an internal approval process, which has been implemented as a safety measure to restrict the number of nodes that are allowed to be forced rebooted at one time,” Microsoft noted. A “significant amount of time was spent exploring additional mitigation options.” However, once they understood what was actually inhibiting mitigation, they “proceeded to reboot the relevant nodes within the safety thresholds.”
We’ve seen similar occurrences before with other providers where the work of one team or area of an organization negatively impacted that of others. Again, it serves to highlight that the small things matter, and that understanding the end-to-end service delivery chain, your role in it, and how what you do affects others, is critical to performance and uptime.
PlayStation Network Disruption
On September 19, users “encountered a problem with the PlayStation Network, which prevented them from playing certain games they owned digitally or had downloaded through PlayStation Plus.” Single players on the PlayStation Network (PSN), predominately in North America, reportedly found themselves unable to access titles from their library of downloaded games or to initiate or connect to game sessions. Multiplayer access appeared to be unaffected.
PSN reported unspecified “external” issues as the root cause. It did not specifically name any third-party provider. Given the very specific way the disruption manifested for users, it appears likely to have been some form of connectivity issue in the PSN backend. Because of the dynamic nature of how online gaming works, any problems in the backend is likely to cause issues for the experience, affecting—for example—the ability to spin up new instances of a game, and therefore the ability of gamers to initiate new sessions. During the incident, users would likely have been presented with HTTP 500 errors when attempting to sign in or start a new session.
In highly dynamic real-time environments such as gaming, it is critical to understand the end-to-end service delivery chain, its interdependencies, and how the loss or degradation of one will affect the rest of the chain.
Microsoft Teams Outage
On September 13, Microsoft Teams users encountered “delays or failures sending and receiving messages.” The application frontend was accessible but attempts to log into the system and/or interact with it resulted in 500 errors and timeouts, indicating some form of backend system or distribution layer issue. The impact appeared to be primarily limited to users in North America, and the problems were ultimately resolved by rerouting the impacted traffic “to healthy infrastructure to alleviate [the] impact.”
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (September 11-24):
-
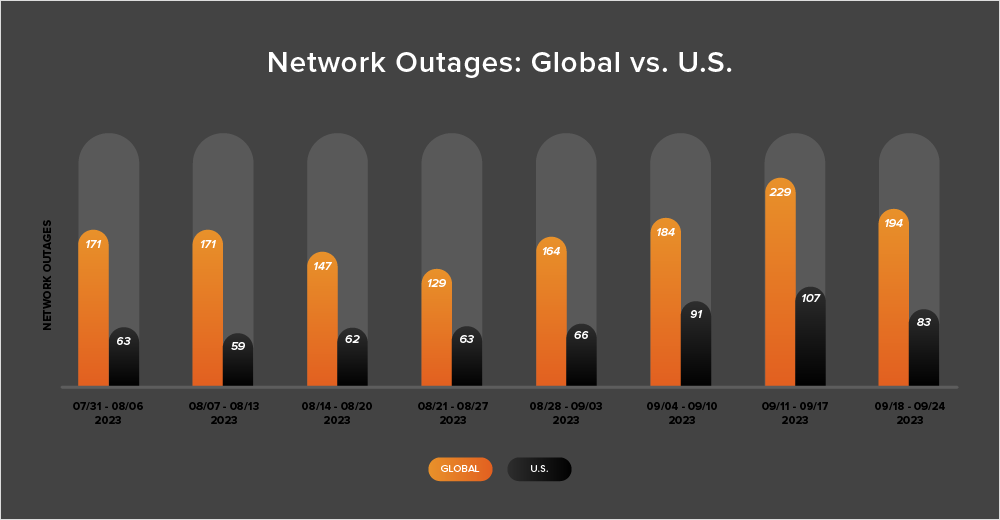
Global outages over the two-week period from September 11-24 initially rose from 184 to 229, a 24% increase when compared to September 4-10. This was followed by a 15% decrease the following week, with observed outages dropping from 229 to 194 (see the chart below).
-
U.S.-centric outages reflected the same pattern, initially rising from 91 to 107—an 18% increase when compared to September 4-10, they then dropped from 107 to 83 the next week, a 22% decrease.
-
This pattern is reflective of what ThousandEyes has observed in previous years: a rise in outages as we head into September, increasing from the previously discussed “lull” seen during the Northern Hemisphere summer period.
-
U.S.-centric outages accounted for 45% of all observed outages from September 11-24, making it the third consecutive fortnight this has happened. Since April, U.S.-centric outages have consistently made up at least 40% of all observed outages in a given fortnight—except for one brief period (July 31-August 13).