We’ll skip the preamble this week because there isn’t much that thematically ties this set of incidents and degradations together. Suffice to say, some bad things happened, but some good will come out of them. We’ll start with the bad, before letting the good—the key learnings and takeaways and how these are manifesting in the architecture of applications, clouds, and networks—round things out.
Zoom’s Bad Gateway
Zoom users ran into problems on November 3 when both Zoom Meetings and the web client started to return 502 bad gateway errors. We observed some level of failure across a number of Zoom tests. Officially, Zoom stated that the impact was limited to “a subset of users.” Users could reach the front page but could not do much beyond that—such as starting, joining, or scheduling a call—due to the loss of backend connectivity. The incident ticket shows the issues started at 11:15 PDT and were resolved at 11:33 PDT, an 18-minute duration, which is similar to what we observed. As of when this post was written, no official post-mortem has been published.

Cases of Cable Theft and Sabotage
On November 2, Comcast customers in Yuba County and neighboring Nevada County in California started experiencing phone and Internet problems. The root cause was actually an alleged cable theft perpetrated by a confused opportunist looking to cash in on a lucrative aftermarket. According to reports, the suspect allegedly stole active cabling he thought was copper but was actually fiber optic. These kinds of incidents aren’t unprecedented—we also reported on an apparent cable sabotage incident in Marseilles, France, in our November 7th update, as well as a similar incident in Australia back in 2012. Of course, both of those involved actual copper!
In most incidents of cable theft and sabotage, the network impacts tend to be very localized. Due to the way terrestrial networks are designed, with many redundant paths, it’s unusual to see incidents of sabotage leave a large blast radius. The exception to that would be subsea cables, but, even then, it is rare these days for there to not be alternative transmission routes available with spare capacity to pick up the additional traffic while the damaged cable is repaired.
AWS Makes Post-incident Fix
Enterprise users may recall the hour-plus duration December 7, 2021, outage experienced by AWS in US-EAST-1. After all, it was one of seven major outages that shook up 2021.
One of the impacts of this outage was on the AWS service health dashboard, which could not be updated. At the time, AWS promised a fix in its official post-incident report, and recently it was confirmed that AWS has made good on that promise, rearchitecting the support case management system and health dashboard to unwind the dependency on US-EAST-1.
It’s always encouraging to be able to revisit these kinds of major incidents and see positive changes enacted from the learnings. While “never let a crisis go to waste” has become overused in corporate presentations recently, courtesy of the past few years, it rings true nonetheless.
Network Issues at Cryptocurrency Exchanges
On November 8, Coinbase experienced “network connection issues” that impeded sign-ins to its web and mobile apps and slowed down the loading of content. Coinbase acknowledged the issues at 11:09 PST, and a fix was implemented at 13:59 PST, meaning a few hours of problems for users of the cryptocurrency exchange. ThousandEyes observed user requests timing out across the period of degradation.
There was also an incident in September where a BGP hijack was used to gain temporary control of a subdomain for the Celer Bridge exchange. According to multiple sources, including Coinbase’s threat intel team, the attackers reportedly placed a malicious smart contract on the subdomain and used it to steal cryptocurrency. (Coinbase, we should note, are to be commended in this circumstance for analyzing external issues and seeking to learn from them and build those learnings into their own platform).
A couple of points to draw out of all of this: first, there’s a lot to consider as a user of a cryptocurrency exchange, let alone as an operator of one. From a network perspective, it’s not only important to understand how you’re immediately connecting to the exchange via an ISP, but it’s also equally important to understand the full end-to-end path and whether all elements in that path can be trusted. Second, there are many different influences and complexities that can impact exchanges. It is worthwhile to understand that complexity exists in the end-to-end construction of the ecosystem.
Needless to say, having good real-time visibility over the end-to-end path that customer traffic is taking is particularly important for operators.
Internet Outages and Trends
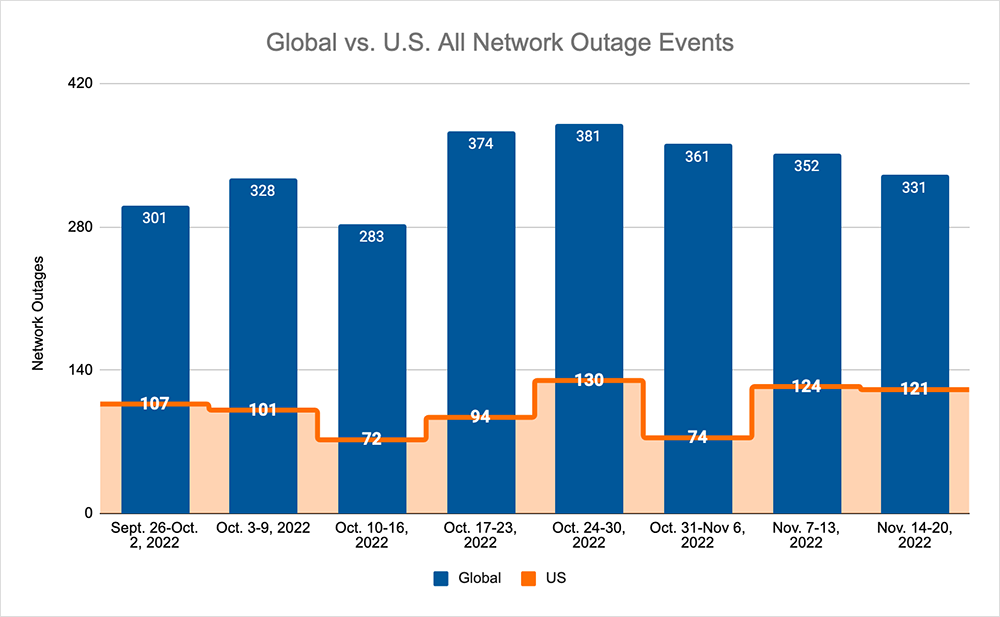
Looking at global outages across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks, we saw:
- Global outages continued the recent downward trend, dropping from 361 to 352 initially, a 2% decrease compared to October 24-30. The trend then continued, dropping from 352 to 331, a 6% decrease when compared to the previous week.
- This pattern was not reflected domestically, with an initial rise from 74 to 124, a 68% increase compared to October 24-30, before dropping from 124 to 121, a 2% decrease from the previous week.
- US-centric outages accounted for 36% of all observed outages, which is larger than the percentage observed on October 24-30 and October 31-November 6, where they only accounted for 27% of observed outages.