


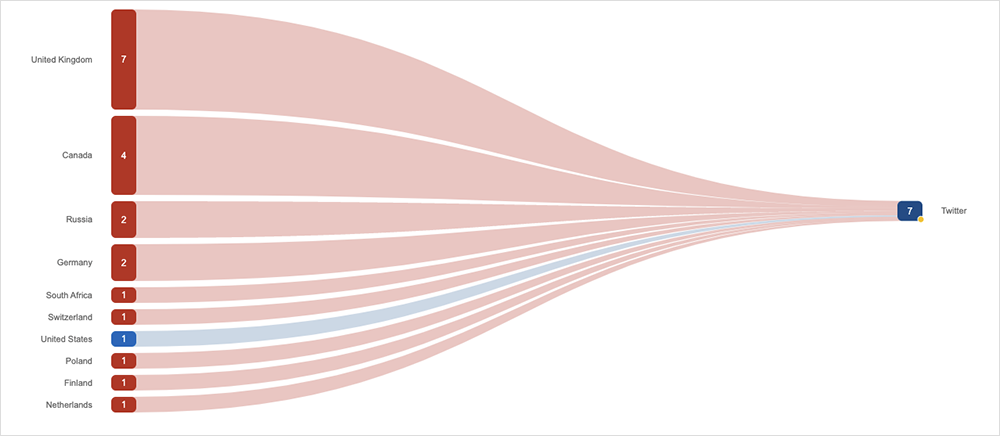
This week on the Internet, users across the UK and Europe may have noticed that Twitter was inaccessible for close to 40 minutes. While the impact of this incident was relatively minor, it did cause some confusion for those who use Twitter to validate in real time whether problems they’re experiencing with a cloud service or application are localized, or indicative of a more widespread problem. As one reporter noted, “Usually when there's an internet outage, people turn to Twitter to look for answers. That's... a little harder now.”
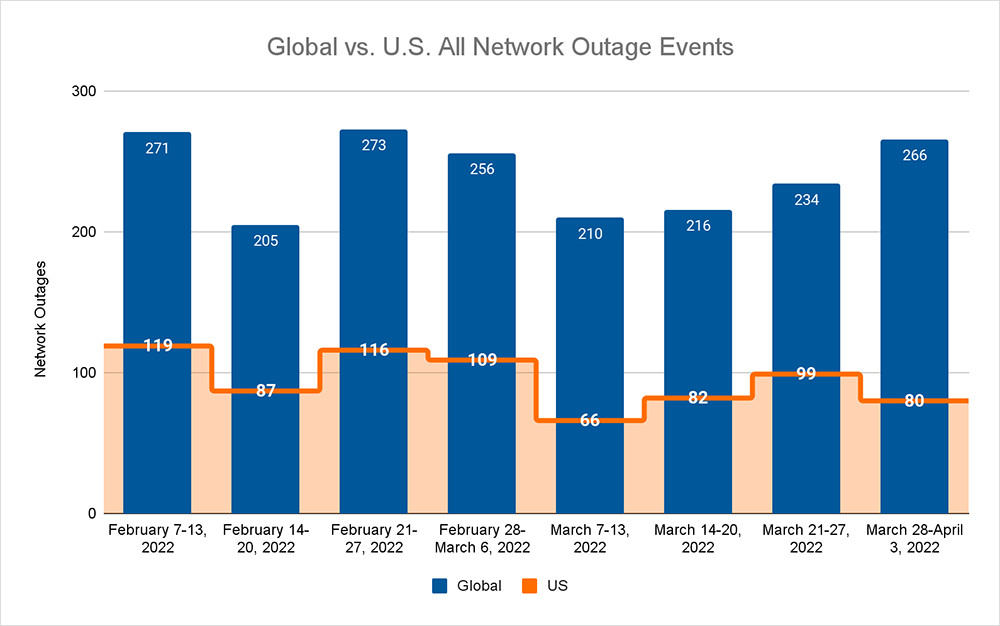
Before we discuss this outage, let's take a look at how the Internet performed this past week. Continuing the upward trend observed throughout March, total global outage numbers rose last week from 234 to 266, a 14% increase, compared to the previous week, and a 27% increase compared to the beginning of March. The upward trend we’re seeing in the global numbers is beginning to reflect my observations from a previous post. This trend was not reflected in the U.S., however, where observed outage numbers dropped from 99 to 80, a 19% decrease compared to the previous week. With the increase in global outages partially offset by the decrease in U.S. outages, the percentage of global outages attributed to domestic occurrences dropped from 42% to 30% for the past week.
Now, back to the Twitter incident. According to reports, the issue impacting users was the result of an ISP that erroneously advertised its network as the best way to get to Twitter. As with any border gateway protocol (BGP) route change mistake, this caused issues. The route advertisement was picked up by other carriers, allowing the error to propagate across much of Europe before it could be corrected.
We saw the full incident develop and unfold through the ThousandEyes platform. Initially, we saw access to Twitter time out across predominantly European locations.
To understand whether the issue was the result of a network or application condition, we inspected the traffic paths. Taking a path from the United Kingdom to Twitter, for example, we observed that the transit path appeared to terminate at a downstream ISP.

In this case, the path appeared to terminate at the ISP, MTS. A quick look at how this route was advertised shows us that, following a route change advertisement, the route to Twitter was now being erroneously advertised.
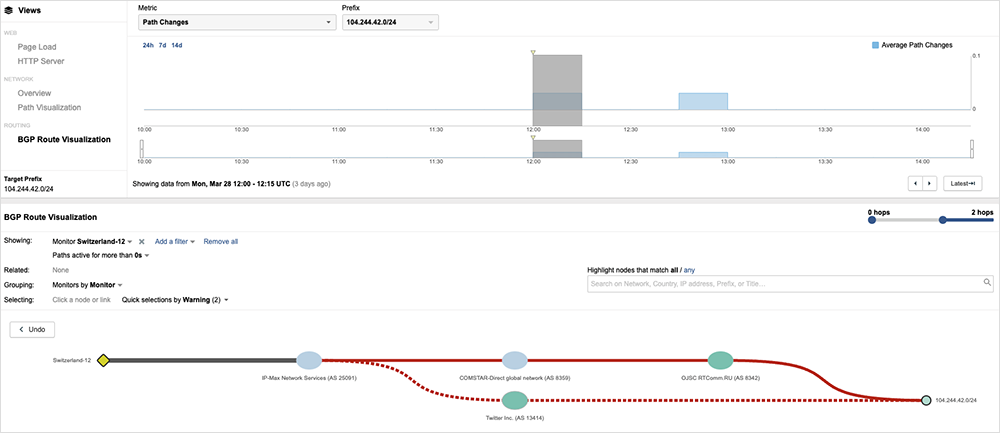
In this case, the expected path to Twitter (ASN 13414) was replaced with a path advertised by RTComm (ASN 8342) and picked up by its BGP peer MTS (COMSTAR ASN 8349), which in turn propagated this route to its peers. Twitter traffic taking this new path failed to reach the destination as RTComm was not authorized to serve Twitter traffic.

Twitter’s technical teams were able to react and respond quickly, resulting in RTCom withdrawing the route, potentially limiting the geographic “blast radius” of the incident and its duration.
While it used to be a more frequent occurrence, this won’t be the last time a provider incorrectly inserts itself into the path of someone else’s routes. We recently discussed that the suspected cause of outages is “always DNS,” but there was a time when “It’s always BGP” rang true as well. These days, it’s often neither: the more common explanation for outages is scale and complexity, making these kinds of BGP errors a bit more noteworthy.
Moving on, regular readers may recall that we previously explored the idea of what constitutes a proportionate response to an outage, or set of outages.
The issue of proportionate responses re-entered the news cycle this week as HR managers were canvassed on what they believed to be a proportionate response to a month or more of downtime to a key service that was taken offline by a cyber incident.
To be clear, this ransomware-related incident isn’t the type of “outage” that ThousandEyes is designed to detect, nor would we see such an incident on our platform. Our interest in this story is around how users dealt with the extended outage duration and the extent to which it tested the limits of anything they might have planned for disaster recovery (DR) purposes.
It’s common for DR plans to take into account issues that last hours or days and to have manual workarounds available in case. It’s often less likely that these workarounds are suitable to remain in place for an extended period of time or indefinitely in the event of a more crippling scenario unfolding.
While an outage of lengthy duration may be considered more of an edge case or outlier, it is a realistic possibility today.
Whenever you make use of software-as-a-service (SaaS), cloud or a third-party app, you’re essentially outsourcing the creation and management of that software or service to a specialist provider. You’re also signing off on a spectrum of risks, from performance blips to more catastrophic incidents.
Your DR strategy needs to contemplate this spectrum of possible issues. Best-practice DR planning today involves mapping out the worst situation that could happen. It should also define trigger points for action and contain workarounds that enable you to stay operational for as long as the outage persists.
In addition to contemplating a complete failure for an extended period of time, digital disaster plans should also anticipate scenarios where a single third-party component or critical dependency fails, breaking the process it is embedded into. This is a much more common scenario today, where the composition of an application or process is complex, comprising dependencies, plugins, microservices and containerized services.
A key input into planning for any, and all, scenarios (and to recognize key signs as they unfold) is a holistic view of your network, cloud and software assets. You need to understand everything you use and to “know what you don’t know” about the digital services you use in order to understand the extent of risks you face in these different ecosystems.








