This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.



Internet Outages & Trends
We’ve said it before, but it’s worth repeating: downtime is inevitable, and outages are a fact of life. While companies can and should take steps to minimize the possibility of an outage, it’s impossible to fully guard against them. To operate effectively in the digital age, ops teams must be able to proactively detect and address an issue, to engineer and build resiliency into the service delivery chain, and to limit overall (negative) impacts on users.
At the point an incident is confirmed, what the service provider does next—the implementation of their “Plan B”—is usually a good indicator for how things will play out, and how customers will react to the downtime.
Over the past two weeks, ThousandEyes saw a range of resiliency actions initiated, including asking customers to use alternative authentication methods (or to avoid logging out of a service), setting up a new contact center to re-establish lines of communication, and reverting to manual processes—with varying levels of success.
Read on to learn about these outages and disruptions, or use the links below to jump to the sections that most interest you:
Square Outage Impacts “Multiple” Services
Contactless payments provider Square experienced a disruption to “multiple” services on February 6, including two-step verification for merchants signing into their accounts. Consumers making payments using Square readers wouldn’t have necessarily noticed anything amiss; merchants, on the other hand, reported issues with payment histories being unavailable, causing some to question whether payments they’d taken had actually worked. Others had payment confirmation but were unable to initiate funds transfers, or they couldn’t accept payments at all.
The root cause was not disclosed but could be either in Square’s backend or alternatively with a cellular services provider. Around the same time, ThousandEyes observed an increase in page load times and failures when attempting to retrieve data from Square domains; however, this appeared to be purely circumstantial, with the two events unrelated.
Square suggested that merchant customers try to authenticate to their accounts using an alternative to the SMS method during the outage: “Please use an alternative two-step verification method to authenticate instead of SMS. If you are already logged in to your account, please do not log out,” the company advised in a post on X.
About 20 minutes into the outage, Square recommended using the alternative authentication method as a workaround, with recovery appearing to begin around 4 hours into the incident, with full resolution to the main incident declared several hours later. However, residual impacts may have been felt after this time, as Square noted that they were “continuing to update balances that were delayed during the disruption.”
Russia .ru Domain Outage
Russian Internet users were unable to reach .ru sites for over three hours earlier this month, reportedly due to an incorrect Domain Name System Security Extensions (DNSSEC) zone signature. The outage left Internet users unable to access key services such as online banking and search engines. ThousandEyes observed that some locations appeared to be able to resolve the sites, suggesting that some upstream resolvers were still able to validate the DNSSEC responses.
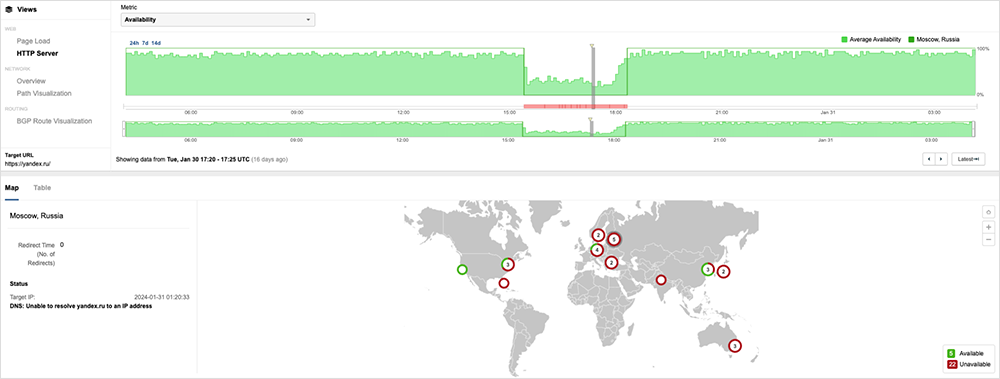
The incident bore similarities with an issue that affected Australia’s .au sites in September last year. Again, the root cause was an issue with DNSSEC, although that incident’s shorter duration meant that end-user impact was more contained.
Cyber Attack at Lurie Children's Hospital
A children’s hospital in Chicago is one of the latest primary healthcare providers that appear to have fallen victim to a ransomware infection. The incident started like many seem to: as a declared network outage affecting Internet and phone services, before later being attributed to a cybersecurity incident. With the network offline, the hospital reverted to alternative services to stay functional, ranging from initially standing up a new contact center to reopen lines of communication, to alternate processes to keep other aspects of the hospital functioning and able to accept patients. It’s a pattern often seen during incidents like these: The network is naturally the first thing that gets disconnected to limit the spread of an incident.
Applied Digital’s Multi-Week Data Center Issue
Applied Digital—which previously provided colocation services for cryptocurrency mining operators but is now pivoting to underpin similarly intensive AI workloads—was without power to its Ellendale data center for nearly a month, starting January 19. According to information Applied Digital provided to the SEC, the issue seemed to be related to an external utility, which was working to restore mains stability to the site. The company reported that as of February 15, “the required upgrades to ensure stability of our electrical supply were completed by our electricity provider and the facility is now re-energized.”
The company is positioned in market segments that are experiencing rapidly scaling demand for compute resources. This, in turn, is creating higher rack densities, requiring existing plant (e.g., cooling systems) and related infrastructure to work harder. It can be challenging for facilities to keep up with this huge demand for resources.
Applied Digital and its utility provider may be considering how to eliminate power supply as a single aggregation point of reliance to the site, and to put processes in place to reduce this ongoing dependence.
UC Berkeley Data Center Outage
The University of California, Berkeley, had issues accessing “critical systems” as well as campus Wi-Fi on February 9 when its data center lost power. A preliminary incident report states the cause as a failure of “several components” of a “temporary generator that the data center uses” for backup power. It’s not immediately apparent why the data center was on backup power. Historically, backup generators would not have the capacity to run a data center at full load, requiring ops teams to know what to run and what to safely shut down. One possible explanation is that the backup generator was being stress-tested to see how it would survive under growing load—a chaos engineering-type of scenario testing—but these details will need to be clarified once a full post-incident report is published.
By the Numbers
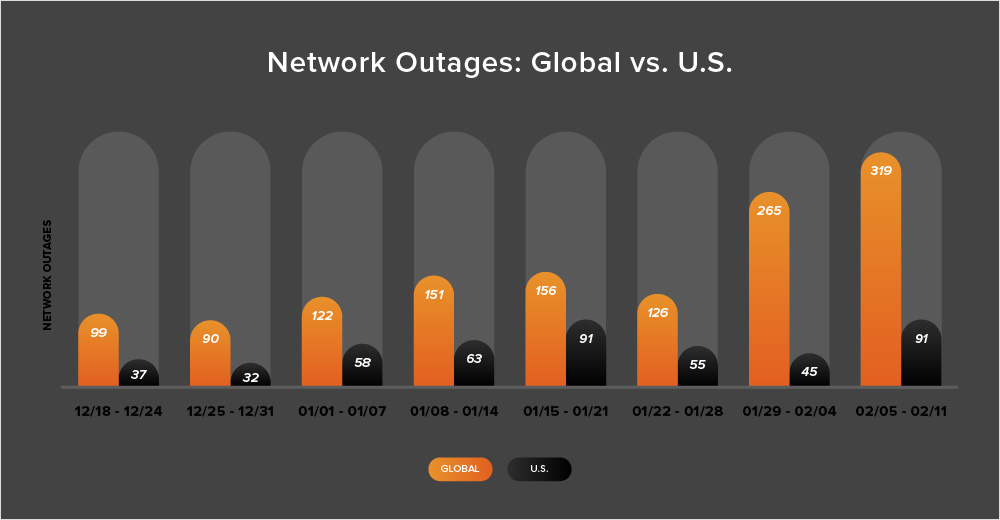
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (January 29 - February 11):
-
The start of February coincided with a significant increase in global outages compared to the previous weeks. Initially, the number of outages rose from 126 to 265, which is a 110% increase. The following week (February 5-11), there was a further increase of 20%. This increase appeared to result from a significant rise in cloud service provider (CSP) outages observed in the APJC region.
-
There was a different story in the United States where outages initially decreased from 55 to 45, a 17% drop compared to the previous week, before rising by 102% the following week (February 5-11).
-
Additionally, during this two-week period (January 29 - February 11), U.S.-centric outages accounted for only 23% of the total observed outages, breaking the trend seen almost consistently since April 2023, wherein U.S.-centric outages have typically contributed at least 40% of all observed outages in a given two-week period. It is most likely that the significant increase in CSP outages observed in the APJC region is responsible for the recent departure from this trend.
-
Since the period we’re discussing includes the final days of January, let’s also take a look at the month-over-month data. In January, there was a 17% rise in the number of global outages when compared to December, with total outages increasing from 558 to 653. The United States also experienced a 26% rise, with outages increasing from 225 to 284. These trends are consistent with previous years, as outages tend to increase after the holiday break.