2023 saw many outages across SaaS applications, ISPs, and other supporting infrastructures. These outages leave important lessons that can help teams minimize the impact of future disruptions, as well as proactively optimize their services and applications for more predictable performance.
Read on for analysis and takeaways from some of 2023’s most notable outages. And check out the recent Top Outages of 2023 webinar to hear first-hand commentary from ThousandEyes’ Internet intelligence team on the outages, including:
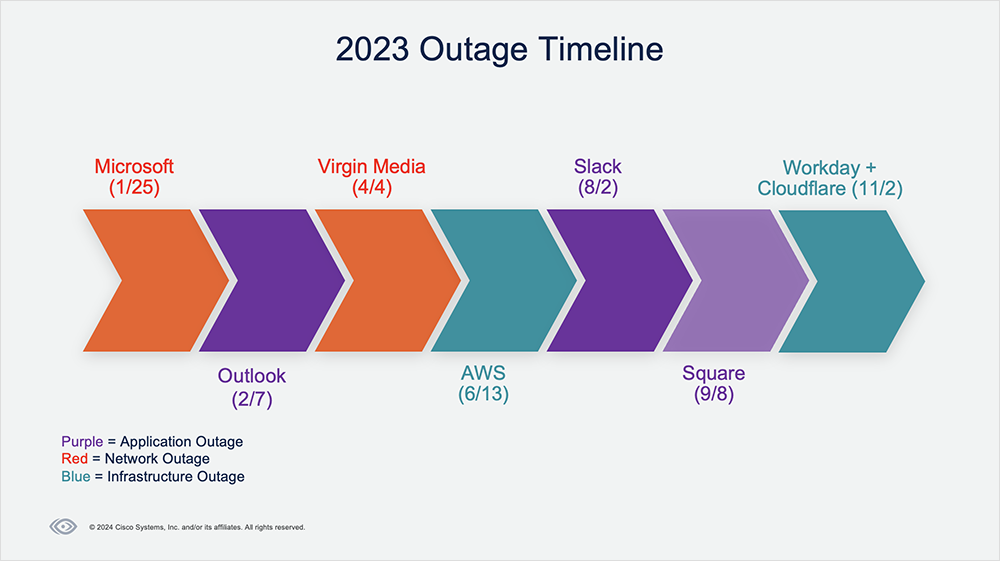
Microsoft 365 Outage | January 25, 2023
At about 7:05 AM (UTC) on January 25, 2023, users experienced connectivity issues with multiple Microsoft services, including Azure, Teams, Outlook, and Sharepoint. The disruption spanned about 90 minutes, but residual connectivity issues appeared to continue into the next day.
The outage began when Microsoft triggered an external BGP change* that affected connected service providers. This destabilized global routes to its prefixes, leading to significant packet loss and causing reachability issues for both Microsoft's services and its customers.
During the incident, ThousandEyes saw changes in traffic distribution via DNS, perhaps indicating efforts to steer traffic away from impacted areas within Microsoft’s network.
Explore This Outage in ThousandEyes | Read Analysis
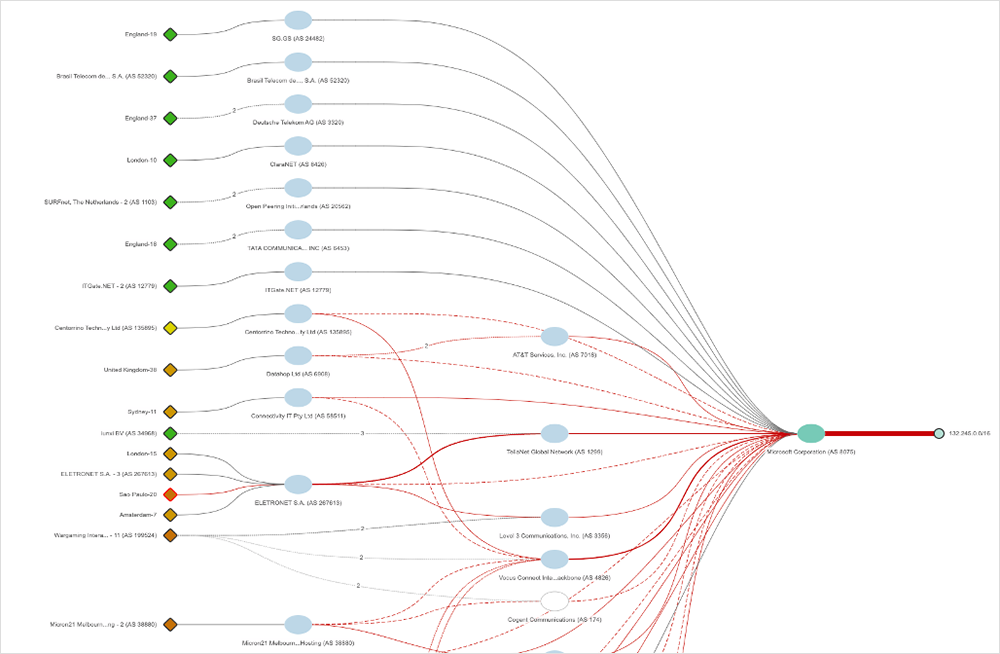
*To view Microsoft’s post-incident report, visit this link, sort the Date field by “All,” and scroll down to the Jan. 25 post-incident review titled “Azure Networking - Global WAN Issues.” You can also watch their incident retrospective video.
Dive Deeper: Watch the Top Outages of 2023 webinar now.
Microsoft Outlook Outage | February 7, 2023
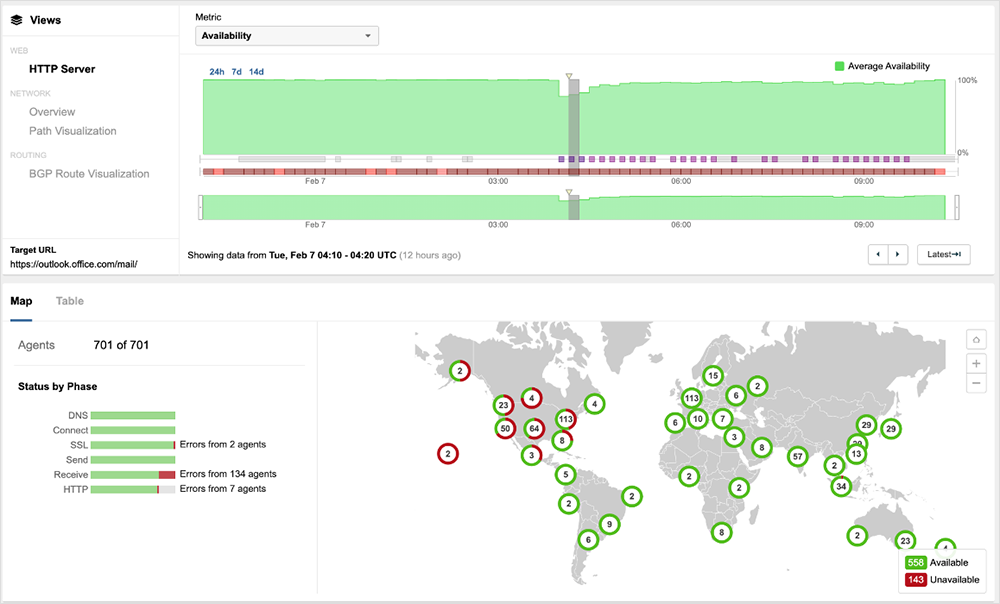
Microsoft experienced another outage on February 7. Unlike the January 25 disruption, however, this outage only impacted the Microsoft Outlook service. The February 7 issue didn’t appear to be network-related, as ThousandEyes observed no significant packet loss, latency, or unusual routing behavior during the incident.
The outage appeared to begin around 3:55 AM (UTC) when Microsoft customers in various regions, including North America, Europe, and Asia, started experiencing issues accessing the Microsoft Outlook service.
During the outage, ThousandEyes vantage points observed symptoms indicative of application-related issues, including elevated server response timeouts and increased page load times. The incident was largely resolved around 5:35 AM (UTC); however, intermittent issues continued to be observed until about 9:40 AM (UTC).
Explore This Outage in ThousandEyes | Read Analysis
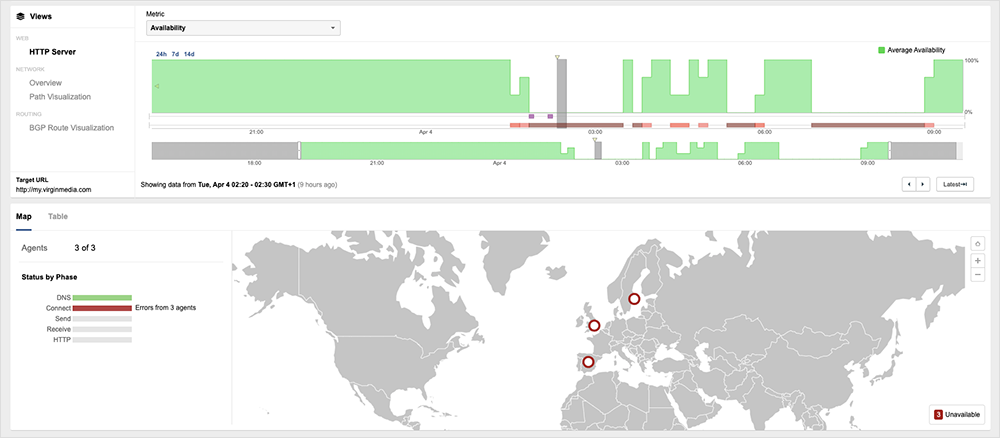
Virgin Media UK Outages | April 4, 2023
Virgin Media UK experienced two outages that affected the reachability of its network and services to the global Internet. Both outages involved the withdrawal of routes to its network, traffic loss, and intermittent periods of service recovery. The first incident took place between ~12:30 AM (UTC) and about 7:00 AM (UTC), while the second began at approximately 3:20 PM (UTC) and resolved around 5:30 PM (UTC).
During both incidents, a lack of viable BGP routes appeared to cause most of the observed traffic loss. However, these withdrawals didn’t seem to impact all service providers—some were still able to successfully route traffic towards the Virgin Media UK network. However, in these cases, all traffic was then dropped at Virgin’s network edge, suggesting the network operator was experiencing systemic duress (likely impacting its control plane), which prevented it from ingesting and routing traffic within its network.
Explore This Outage in ThousandEyes | Read Analysis
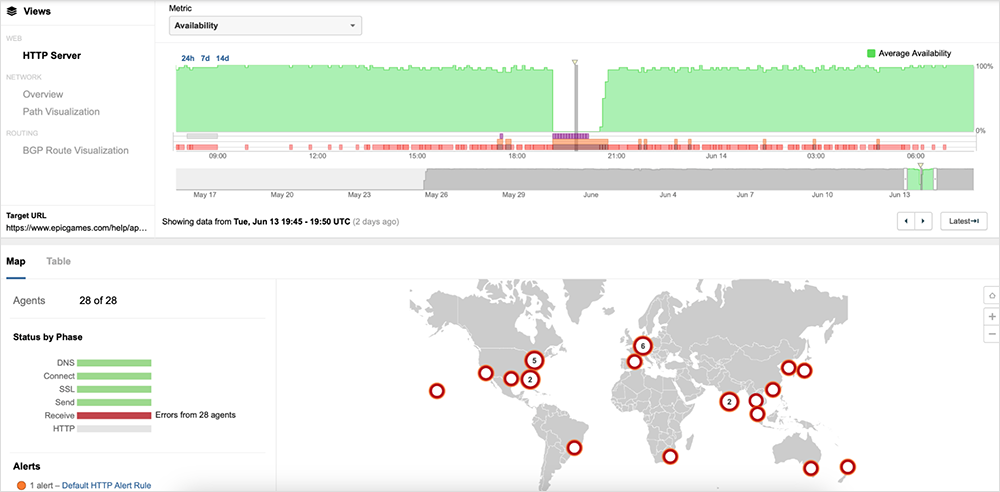
AWS Outage | June 13, 2023
On June 13, Amazon Web Services (AWS) experienced a more than two-hour incident that impacted a number of services in the US-EAST-1 region. The disruption was first observed around 6:50 PM (UTC) and appeared mostly resolved by 8:40 PM (UTC). At that point, availability for the majority of impacted AWS services and affected applications had returned to normal levels.
During the incident, ThousandEyes did not observe any significant issues, such as high latency or packet loss, for network paths to AWS’ servers. However, ThousandEyes did see an increase in latency, server timeouts, and HTTP 5XX server errors impacting the availability of applications hosted within AWS.
About 35 minutes into the incident, AWS identified the issue’s source as a capacity management subsystem located in US-EAST-1 that was impacting the availability of many of its services, including Lambda, AWS Management Console, and many more. As ThousandEyes observed, AWS confirmed that these affected services were experiencing “increased error rates and latencies.” This in turn caused service availability issues for applications using these AWS services, regardless of where they were hosted or where they were serving users.
Explore This Outage in ThousandEyes | Read Analysis
Get More Internet Insights: Tune in to The Internet Report podcast.
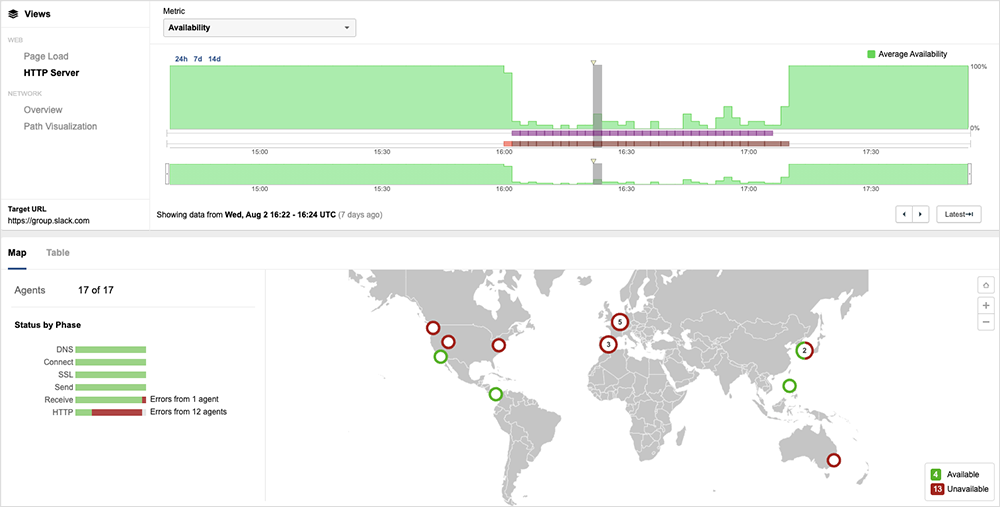
Slack Outage | August 2, 2023
Between 4:01 PM (UTC) and 6 PM (UTC), some Slack users experienced difficulties in uploading files or with images appearing blurry. This issue worsened for a subset of users, leading to errors or delays in other functions of the service. Some users also faced prolonged page load times and general instability.
This disruption in Slack demonstrates that just because a service is available, it doesn't necessarily mean it's usable. If some key functions do not work as expected, users may not be able to complete their desired tasks. For instance, during the Slack outage, some users who spoke with ThousandEyes were able to send text-only messages but experienced difficulties in sending screenshots. The decreased functionality affected usability to such an extent that some users temporarily switched to another collaboration service.
Explore This Outage in ThousandEyes | Read More
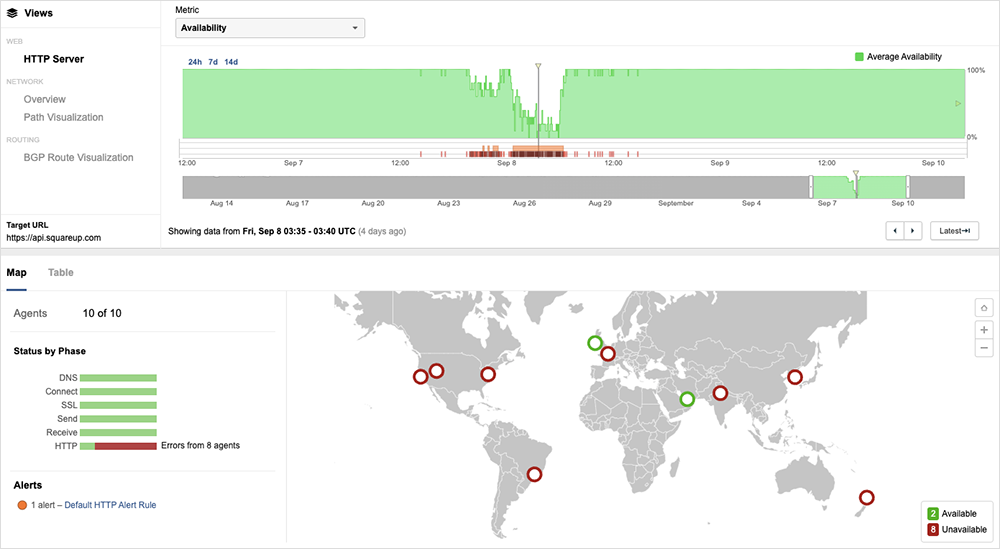
Square Outage | September 8, 2023
On September 8, contactless payments terminal and service provider Square experienced an 18.5-hour disruption that prevented businesses from processing transactions. Caused by backend connectivity issues, impacts were felt across “multiple Square services” around the world.
To safeguard against issues going forward, Square is taking a number of actions, such as expanding offline payment capabilities. Backup systems and processes like this can make all the difference when minimizing the impact of outages. This Square disruption serves as a good reminder for companies to think creatively about what backup solutions they need.
Explore This Outage in ThousandEyes | Read More
Explore the Internet Outages Timeline for more outage analysis and practical tips.
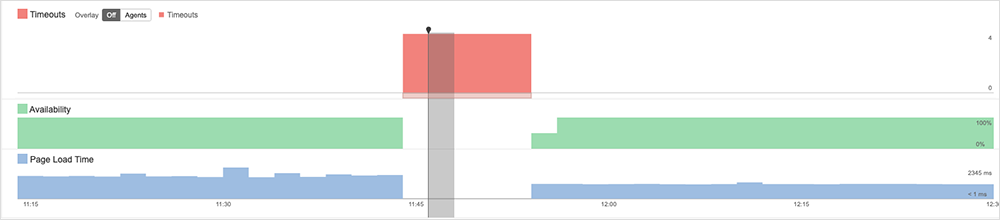
Workday + Cloudflare Outages | November 2, 2023
On November 2, Cloudflare and Workday experienced service outages that appeared related due to the overlap in timing, and both companies initially cited data center power failures as the cause. A combination of post-mortems, OSINT, and ThousandEyes observations suggest that the two outages were related.
The link between the outages appears to be a partial mains power outage at a Flexential data center in Portland, Oregon, which Cloudflare pointed to in its detailed post-mortem report. Although Workday did not name the specific data center they were having issues with, they noted it was in Portland and given the similar timing, it is likely that they are referring to the same one.
Cloudflare explained in its report that when one mains feed to the site was disabled, the remaining feed was supplemented with power from onsite generators. However, the site ended up completely losing power due to a further ground fault with a transformer. This complete power loss only became apparent when equipment ungracefully shut down, and application makers sent their own technicians on site.
It took over six hours for Cloudflare to successfully enable disaster recovery and about a day and a half total for full recovery (see more details in their extensive post-mortem report). Workday officially reported full-service restoration around 12:00 AM (UTC) on November 3 (5:00 PM [PDT] on November 2), but customer status notifications suggested that services were restored a few hours earlier, around 9:30 PM (UTC) on November 2 (2:30 PM [PDT]).
Explore the Workday Outage in ThousandEyes | Read More
More Outage Insights
For additional details about these outages and important lessons learned, check out the recording from the Top Outages of 2023 webinar. And for more regular insights on Internet health and outage analyses, subscribe to The Internet Report podcast on Apple Podcasts, Spotify, SoundCloud, or wherever you get your podcasts.
To experience how ThousandEyes can help you troubleshoot and proactively guard against outages that may impact your service, start your free trial today.





